I keep coming back to a simple question that seems to sit underneath much of crypto: what exactly is being owned when a system says it is “decentralized”? In payments, ownership is obvious enough. In lending, it is capital. In blockchains built for computation, the answer becomes less clean, because the most valuable thing is often not the ledger itself but the data, models, and systems of coordination that feed it. OpenLedger is trying to make that hidden layer visible. On its own site, it describes itself as an AI blockchain designed to unlock liquidity around data, models, and agents, and its whitepaper frames the project around a mechanism called Proof of Attribution. That framing already tells me something important: this is less a claim that AI should be “onchain” in some abstract sense, and more a proposal that the inputs to AI should be tracked, credited, and made economically legible.
The problem it is addressing did not appear overnight. For years, AI systems have improved by absorbing enormous amounts of data from public and private sources, but the people who assembled, cleaned, labeled, or specialized that data rarely had any reliable path to recognition or compensation. OpenLedger’s own paper says this directly: training data is often treated as anonymous and static, while contributors remain disconnected from the value their data helps create. That is not only an ethical complaint. It is also a structural one, because once data is reduced to an invisible input, there is little reason for outsiders to keep contributing high-quality, domain-specific material. The result is a familiar crypto pattern in another form: value concentrates at the center while provenance becomes an afterthought.
Earlier attempts to solve this problem have usually failed for one of two reasons. Some systems tried to build marketplaces for datasets, but stopped at listing or licensing, without tracing how a specific contribution shaped a specific output. Others focused on model transparency in a broad sense, which is useful, but still does not answer the harder question of attribution. OpenLedger’s whitepaper is explicit that it wants a verifiable link between model behavior and the training data that influenced it, with rewards distributed from that link. That is a more ambitious claim than simple openness. It is trying to turn attribution into infrastructure, not just documentation. The difference matters, because documentation can be ignored while infrastructure is harder to route around.
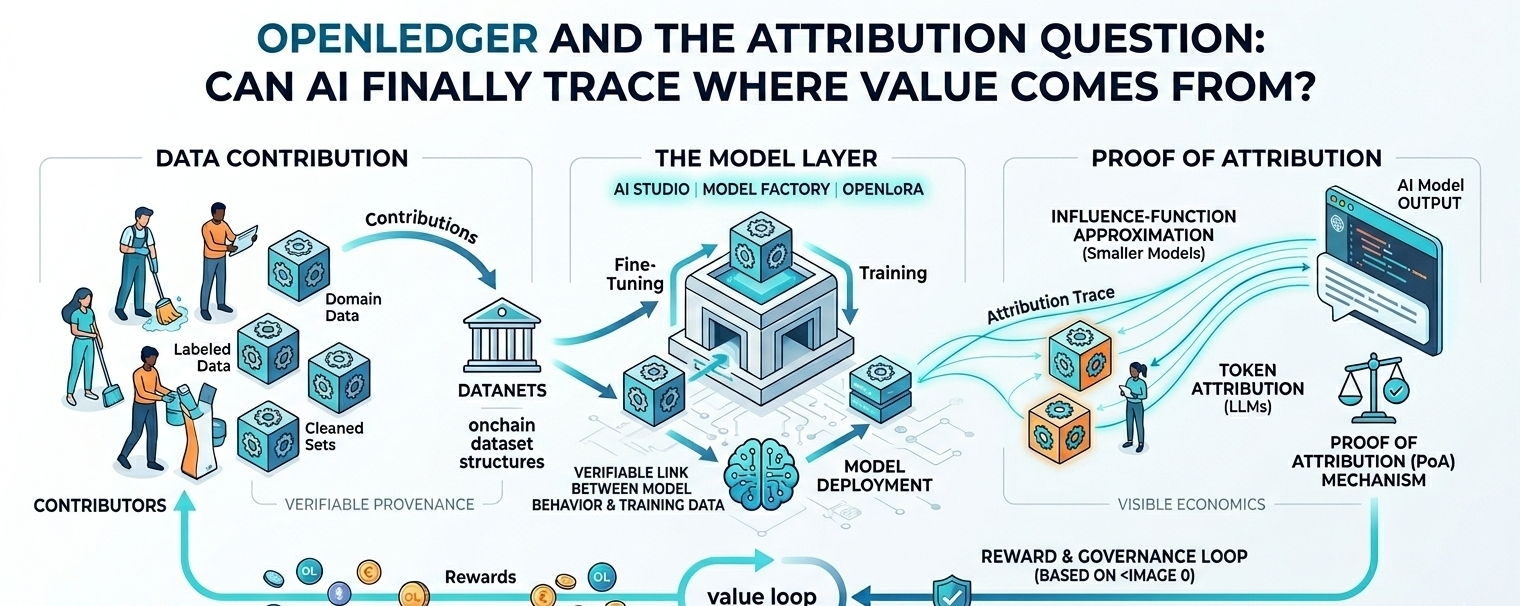
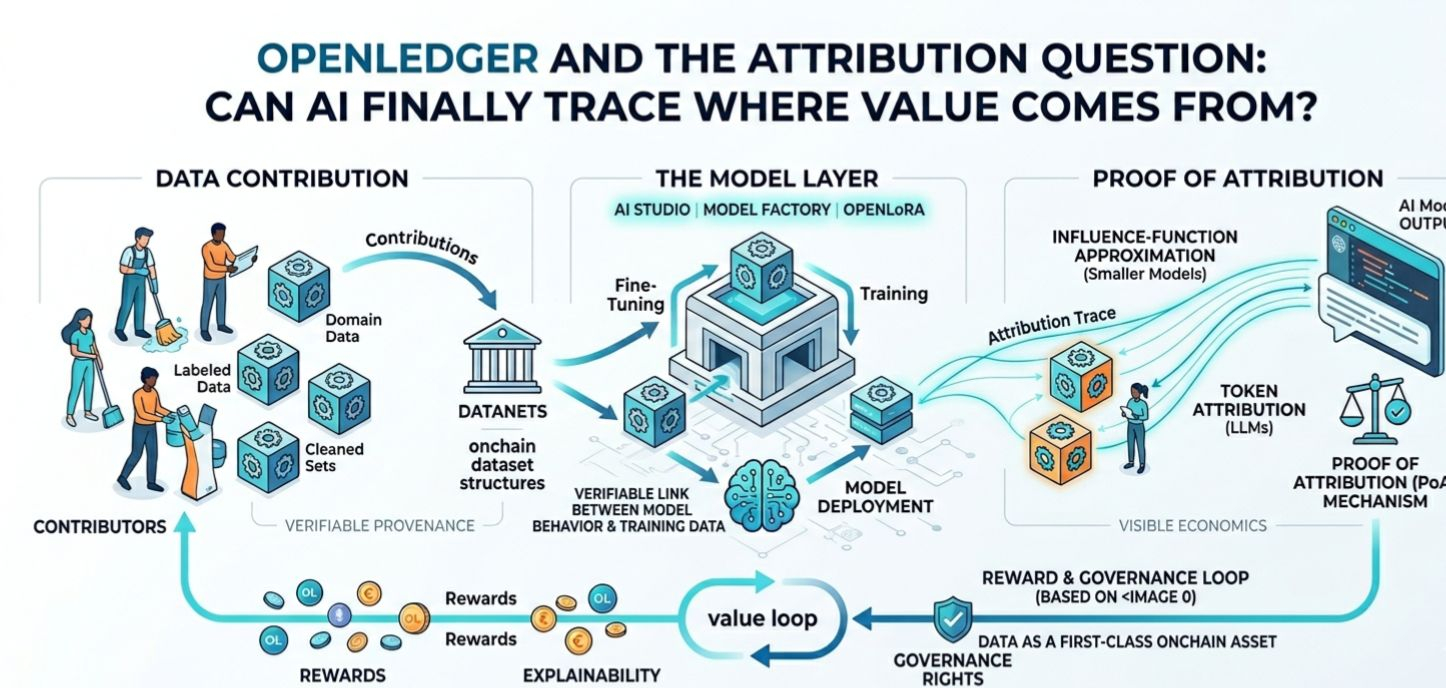
The architecture OpenLedger describes has a few moving parts, and the design logic is fairly easy to follow. At the center are DataNets, which the paper describes as onchain dataset structures built through community contribution. In the project’s own materials, DataNets are where communities co-create, curate, and contribute datasets that later influence model training. Then comes the model layer: OpenLedger describes an AI Studio, a Model Factory, and OpenLoRA. The first is for building, the second for fine-tuning, and the third for cheaper deployment. The broader idea is that data collection, model training, and model serving are not separate worlds; they are linked by provenance, attribution, and reward. That linkage is the project’s core thesis.
Proof of Attribution is where that thesis becomes concrete. In the whitepaper, OpenLedger says it uses two different attribution methods depending on model size: influence-function approximations for smaller models and suffix-array-based token attribution for larger models. That tells me the team is aware that attribution is not one uniform technical problem. Small models can be handled with gradient-based approximations of how removing a data point would change loss, while larger language models need a different approach that compares output tokens against a compressed representation of the training corpus. The logic is sensible, but it also reveals the difficulty: the system is not simply “proving” a contribution in a legal sense. It is estimating influence with the best available machinery, then using that estimate to split credit and rewards.
I find that distinction important because it keeps the project honest. A lot of AI attribution talk sounds more exact than it really is. OpenLedger’s design is more careful than that. The paper says model outputs, metadata, and timestamps are committed onchain, and attribution is calculated after inference so contributor rewards can be distributed based on relative influence. That makes the system auditable, but not magically perfect. It can show a chain of provenance and a reward path; it cannot erase the ambiguity that always lives inside complex machine learning systems. Attribution in AI is rarely a clean ledger entry. It is usually an approximation wrapped in policy. OpenLedger seems to understand that, even while it presents the approximation as a protocol primitive.
This is also where the project begins to look less like a slogan and more like a serious experiment. OpenLedger says it is not a general-purpose chain. It is focused on AI and model workflows, and it even contrasts itself with general blockchains by emphasizing native data attribution, provenance, and governance around model quality rather than protocol changes. On paper, that specialization is appealing. Too many crypto systems try to be everything at once, which usually means they become vague at the exact moment they need to be precise. OpenLedger’s narrower scope gives it a clearer job: keep track of where AI data came from, who contributed it, how it influenced models, and how rewards are distributed. That is a coherent frame. Whether it is enough is a separate question.
The technical promise, however, does not remove the trade-offs. A system like this has to carry the weight of registration, verification, inference accounting, reward distribution, and governance, all while trying to remain useful to builders who may not want extra friction in their workflow. The paper suggests a public attribution graph and even hints that governance rights could later reflect a dataset’s influence across models. That is intellectually interesting, but it also raises familiar problems: who decides the attribution rules, how are disputes handled, what happens when a dataset is reused in ways the original contributor did not expect, and how expensive does the system become as usage scales? These are not side issues. They are the difference between a framework that can be admired and a framework that can be adopted.
There is also a more subtle concern about what gets measured. If attribution becomes the basis for rewards, then the protocol’s notion of influence starts to shape contributor behavior. That can be healthy, because it encourages higher-quality data and more deliberate curation. It can also narrow incentives in unintended ways, because contributors may optimize for traceable influence rather than broad usefulness. OpenLedger’s own materials describe reward flows, explainability, and proof tied to each response, which is exactly the kind of mechanism that can improve accountability. But the same mechanism can create pressure to simplify complex contributions into whatever the attribution system can most easily recognize. In other words, the protocol may reward what it can measure before it fully understands what matters. That is not a flaw unique to OpenLedger, but it is a real design constraint.
Adoption is another quiet obstacle. A project like this needs more than a strong narrative. It needs datasets worth contributing, builders willing to train or fine-tune through its stack, and model users who care enough about provenance to prefer a more accountable system over a simpler one. OpenLedger’s own ecosystem pages point to products such as Explorer, staking, AI Studio, and an Open Circle community layer, which suggests it is trying to build the social and technical surface area required for sustained participation. That makes sense. But infrastructure only matters if the people using AI feel the absence of provenance as a real cost. Many do not, at least not yet. So the first audience for a system like this is likely to be the people already closest to the problem: data contributors, niche model builders, auditors, and communities trying to create domain-specific AI with some traceability intact.
That still leaves open a larger uncertainty, which is probably the most interesting thing about OpenLedger. It is trying to make data into a first-class onchain asset, and that idea is more convincing than it first sounds because AI really does depend on a chain of contribution that is usually hidden from view. Yet the harder the project leans into attribution, the more it must prove that the system is accurate enough, lightweight enough, and fair enough to survive beyond the whitepaper. I can see why the problem keeps resurfacing: AI keeps consuming more value than it can transparently return. OpenLedger is one attempt to answer that imbalance. The unresolved question is whether the future of AI will actually reward the systems that make contribution visible, or whether visibility itself will remain too expensive for the market to fully embrace.