
OPENLEDGER ($OPEN): AI, DATA OWNERSHIP & THE NEW VALUE LAYER
I used to think AI progress was mostly a question of better algorithms and more compute, something that naturally moves forward as technology improves, almost like a straight line if you wait long enough. At first I thought the real competition was between models, between who trains faster and who scales bigger, and everything else around it was just supporting structure. I didn’t pay much attention to the idea that data itself could become the main economic layer, something that carries ownership and value in its own right rather than just being input for training systems.
But the more I look at things like OpenLedger, the more that simple picture starts to feel incomplete. What first catches my eye is not the technical architecture but the quiet shift in framing, where data is no longer treated as passive material but as something closer to a living economic asset. Then it started to feel like the question is not about how advanced the AI is, but about who the system is actually built for, and who quietly ends up holding the value after everything runs.
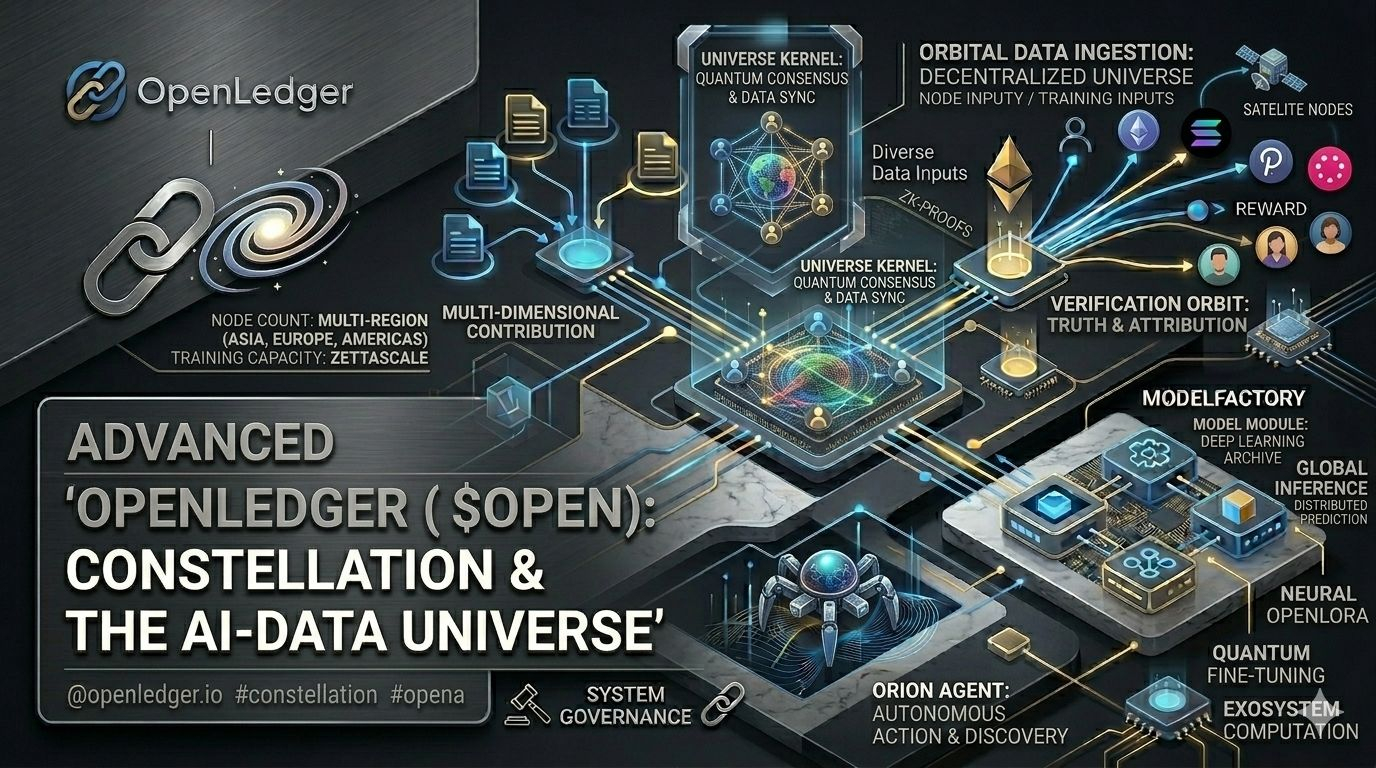
What I’ve been noticing something subtle in these systems is that they always look clean at the surface, but underneath, value flow is never as simple as it appears. In something like OpenLedger, the idea is straightforward on paper: users contribute data, that data gets used in training or inference, and value is redistributed back through attribution mechanisms and tokens. But what keeps bothering me is how many steps sit between contribution and reward, and how easily each step can be influenced by incentives rather than pure value creation.
Then it starts to feel like the system is not just about data contribution, but about shaping behavior around contribution. People upload, curate, interact, not always because the data is valuable in a deep sense, but because the system rewards activity that looks like value. At least from where I’m standing, that difference between “useful data” and “rewarded activity” is where a quiet tension begins.
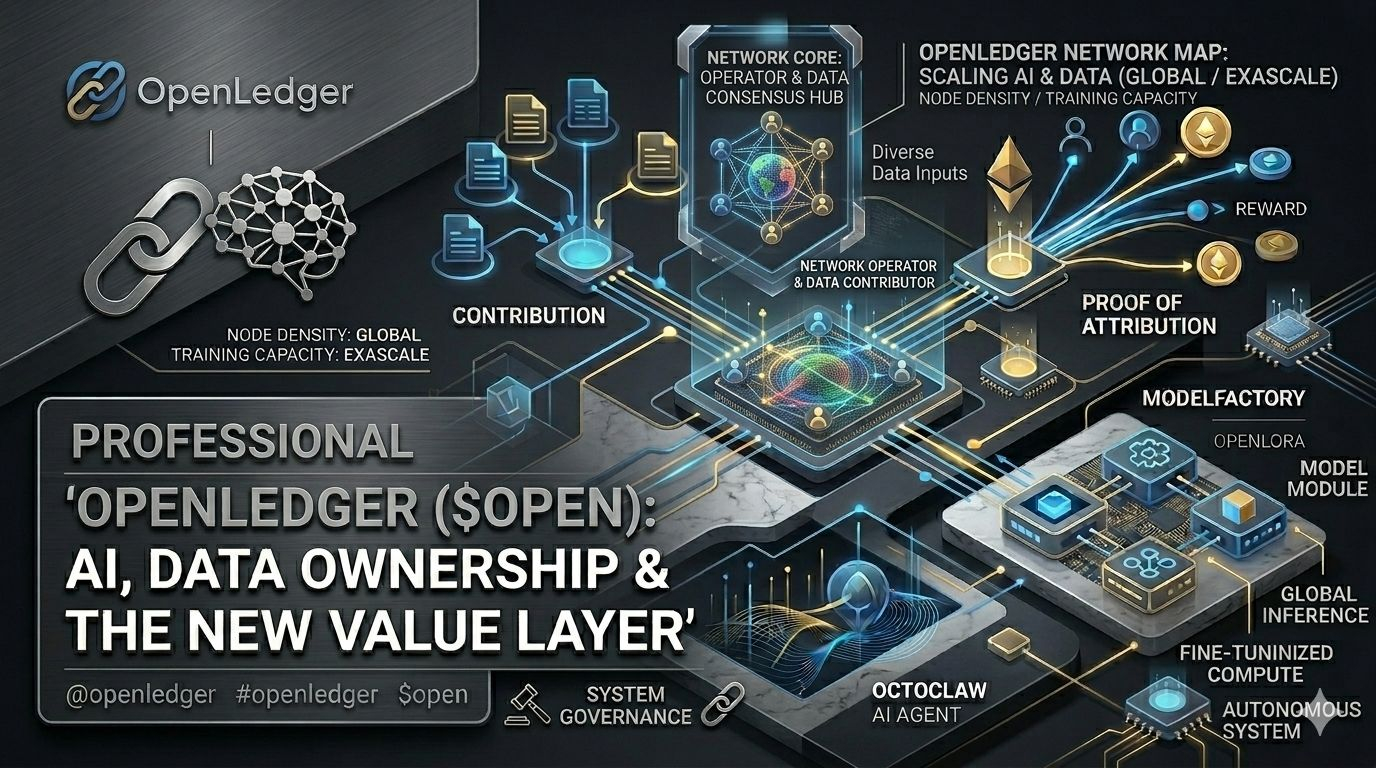
That’s where it gets interesting when you look at layers like ModelFactory or OpenLoRA, where the promise is efficiency through decentralized fine-tuning and shared compute, but the deeper question is whether efficiency alone creates adoption, or whether it just creates a more complex system waiting for real demand to justify it. OctoClaw adds another shift, because now AI is not just producing outputs but acting inside systems, and when AI starts acting instead of just responding, the boundary between infrastructure and agency becomes less stable than we usually assume.
Then Proof of Attribution enters as the attempt to make invisible contributions visible, to trace which data influenced which output and distribute rewards accordingly. On paper it feels like a missing piece being solved, but what I keep thinking about is how attribution behaves in recursive systems where data influences models that later influence new data again, creating loops where origin becomes harder to define than we admit. The strange part is that the more connected the system becomes, the harder it may be to cleanly assign ownership.
I keep coming back to the idea that maybe what we are really building is not just AI infrastructure but a new kind of ownership structure for intelligence itself. Because whoever controls attribution controls the direction of incentives, and whoever controls incentives quietly shapes what kind of data gets produced in the first place. That’s where it starts to feel like infrastructure is not neutral anymore, but behavioral, almost like a system that guides participation rather than just records it.
Zooming out, this connects into a much broader shift in both AI and crypto systems, where value is no longer tied only to final outputs but increasingly to the underlying layers that make those outputs possible. Digital ownership starts to blur when the thing being owned is not a static asset but a contribution inside a continuously evolving system. And crypto, in this context, becomes less about tokens themselves and more about whether it can successfully coordinate trust, attribution, and distribution at scale across machines and humans at the same time.
What keeps bothering me is whether this entire direction is stable or just early-stage experimentation wrapped in a compelling narrative. Because legitimacy, funding, and ecosystem metrics can show momentum, but momentum does not always translate into long-term usage or sustainable behavior. And when token supply structures and future unlocks enter the picture, the system becomes even more sensitive to demand that may or may not exist at scale yet.
maybe I’m wrong, maybe attribution systems will mature enough to support a real AI economy layer, or maybe this is still early infrastructure where we are projecting clarity onto something still forming. I’m not sure yet, and that uncertainty feels important rather than uncomfortable.
And I keep thinking about one simple question that doesn’t fully resolve itself: if AI becomes the dominant engine of digital value creation, then where does that value actually settle in the end, in the data, in the model, in the protocol, or in something we still haven’t clearly defined yet, and that question is still open in a way that feels like it will only be answered by time rather than theory.