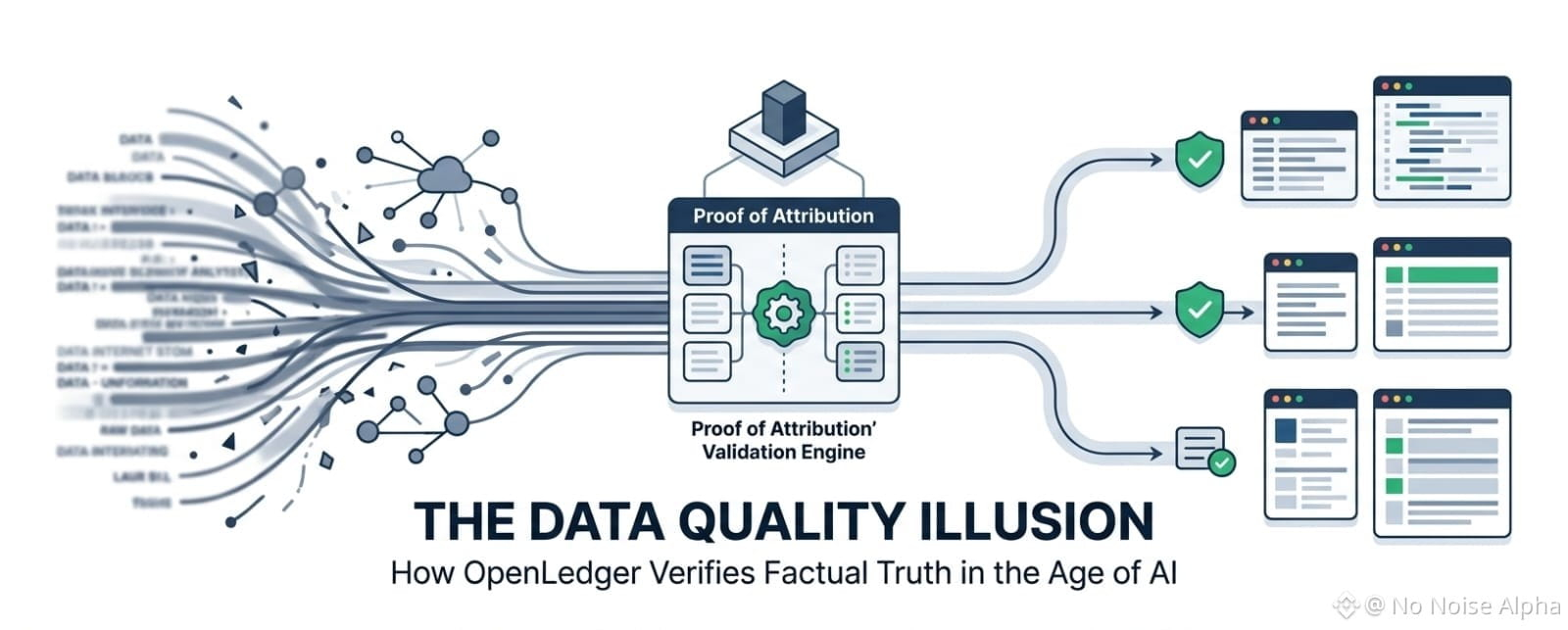
A volte penso che la maggior parte delle persone non capisca ancora quanto sarà importante la "validazione dei dati" nel mondo dell'AI autonoma.
Se dovessi dirlo dal profondo del mio cuore, è perché tutta la discussione è ancora bloccata sulla quantità. Quale modello ha più parametri, quale ha estratto più terabyte di testo, quale azienda ha accumulato il più grande server farm. Ma sotto, sta succedendo qualcosa di molto più profondo... e probabilmente è la purezza dei dati. Chi pulisce e verifica realmente le informazioni prima che la macchina le apprenda? E onestamente, più guardo l'architettura di OpenLedger Datanet, più sembra che non stiano solo creando un altro bucket di storage decentralizzato. Stanno cercando di ridefinire la relazione tra informazioni grezze e verità verificata.
Sembra grande. Forse anche extra grande – intendo qualcosa di assolutamente massiccio. E potrebbero volerci ancora alcuni cicli perché le persone capiscano se questa validazione decentralizzata funzionerà effettivamente su larga scala sotto forte stress di scraping. Eppure…. c'è qualcosa di diverso qui a livello strutturale. Perché tradizionalmente, i modelli AI assorbono vasti oceani di spazzatura internet – ma una volta che il modello inizia a essere affetto da allucinazioni o a prendere decisioni sbagliate, i dati tossici sottostanti sono completamente nascosti agli utenti che si affidano ad essi.
Il modello impara tutto.
Il sistema non verifica nulla.
Questo squilibrio è presente da molti anni.
E ad essere onesti, è qui che l'attenzione di OpenLedger sui dati verificabili inizia a sembrarmi interessante. Non per il branding. Onestamente, i progetti crypto lanciano nuovi marketplace di dati quasi ogni settimana. Ma poiché il framework di contributi è passato all'esecuzione dal vivo, la discussione si è spostata dalla teoria allo stato economico. Ora il layer Datanet non è più solo un disegno concettuale. I contributori possono inviare dataset specifici, i validatori verificano fisicamente la qualità e i contratti smart gestiscono le metriche di attribuzione on-chain. Cambia la struttura psicologica della creazione dei dataset.
Improvvisamente, i dati non sono più solo carburante grezzo.
Diventa un asset verificato e tracciabile.
E penso che questa distinzione sia più importante di quanto la gente pensi. Soprattutto dopo aver osservato da vicino come il motore di Proof of Attribution gestisce input sovrapposti. L'architettura si basa sull'inserire contesto curato da esseri umani direttamente in un motore di validazione distribuito. Se un dataset specifico è avvelenato con fatti falsi, o se un bot fornisce intenzionalmente spam, il punteggio di qualità scende istantaneamente. Monitorando questi cambiamenti di qualità a livello granulare, il framework cerca di attribuire matematicamente quale contributore ha effettivamente fornito il segnale pulito. Perché mappare una risposta AI pulita a una rete opaca di siti web estratti è un ostacolo ingegneristico scomodo.
Le fonti sono collettive.
Le origini sono sfocate.
Quasi irrintracciabile.
Quindi cercare di isolare l'esatta origine di un singolo input fattuale all'interno di un enorme corpus di addestramento… è in realtà un problema infrastrutturale enormemente ambizioso. E forse imperfetto. Non credo che la verifica dei dati sarà mai completamente matematicamente pura. Tuttavia, cercare di creare almeno uno strato di validazione trasparente sembra essere un cambiamento diverso rispetto a dove l'industria stava andando. La maggior parte delle piattaforme ottimizza l'estrazione semplice dei dati. OpenLedger sta almeno cercando di ottimizzare la responsabilità dei dati. O almeno sta andando in quella direzione.
Ecco un'altra cosa a cui continuo a pensare... la realtà legale e commerciale per le persone che effettivamente costruiscono queste cose. Quando guardi a un'AI lucida che risponde a una domanda complessa medica o finanziaria, sembra incredibilmente intelligente. Ma nel mondo pratico, le imprese e gli sviluppatori non guardano all'interfaccia liscia. Stanno ponendo domande difficili:
Questo dataset è legalmente pulito?
Le fonti sono verificate?
Come gestisce il modello gli input avvelenati?
Le origini reggeranno in tribunale?
E questo potrebbe cambiare l'intera dinamica dell'ecosistema della macchina commerciale. Guardando all'approccio di OpenLedger ai dataset specifici per il dominio, sembrano consapevoli di questa realtà. Non stanno cercando di costruire uno scraper generico che ruba tutto. Si stanno concentrando su ambienti di dati specializzati e ad alta fedeltà. Onestamente, sembra rinfrescante in un mercato in cui molti progetti stanno ancora cercando di essere "layer di dati per tutto". Ma allo stesso tempo..... Non penso che il viaggio sarà facile da qui. Perché dove le vere ricompense economiche incontrano la presentazione dei dati, si presenteranno comportamenti imprevedibili.
Loop di dati sintetici.
Manipolazione della qualità.
Spam farming.
Dispute di validazione.
Queste pressioni sono inevitabili. Quindi il vero test probabilmente inizia ora, mentre più costruttori collegano i loro dataset personalizzati allo stack. Il processo di validazione rimarrà forte anche quando si scalano migliaia di invii paralleli? Il punteggio di qualità sarà affidabile attraverso milioni di interazioni autonome? Gli incentivi a lungo termine manterranno onesti i validatori?
Onestamente.......
Non lo so con certezza. Ma forse questa incertezza è ciò che rende questa fase importante. Perché dopo molto tempo, sta emergendo un progetto che non parla solo di potenza di calcolo astratta o narrazioni speculative. Stanno cercando di rispondere a una domanda molto più scomoda:
“Se i sistemi AI diventano la base della nostra conoscenza... l'infrastruttura saprà effettivamente ciò che è vero e ciò che è falso?”
E onestamente, penso che l'industria dovrà affrontare questa domanda prima o poi. OpenLedger potrebbe non avere ancora tutte le risposte. Tuttavia, sembra che questa sia una delle poche architetture che non sta evitando la realtà confusa della qualità dei dati, ma piuttosto sta cercando di costruire una base permanente attorno ad essa.
Se attualmente stai perfezionando o sperimentando con dataset personalizzati, come stai gestendo la validazione delle origini su larga scala in questo momento?
@OpenLedger #openledger #OpenLedger $OPEN
