Credo che una delle domande più importanti nell'AI non sia solo “chi ha costruito il modello?” ma “quali dati hanno aiutato il modello a diventare utile?”
Quella domanda è rimasta nella mia mente quando ho guardato @OpenLedger .
La maggior parte dei modelli AI non diventano utili per magia. Hanno bisogno di dati. Hanno bisogno di esempi. Hanno bisogno di segnali da persone reali, comunità reali e casi d'uso reali. Ma la parte strana è che il contributore di dati spesso viene messo in secondo piano una volta che il modello inizia a generare valore.
Penso che sia un serio gap.
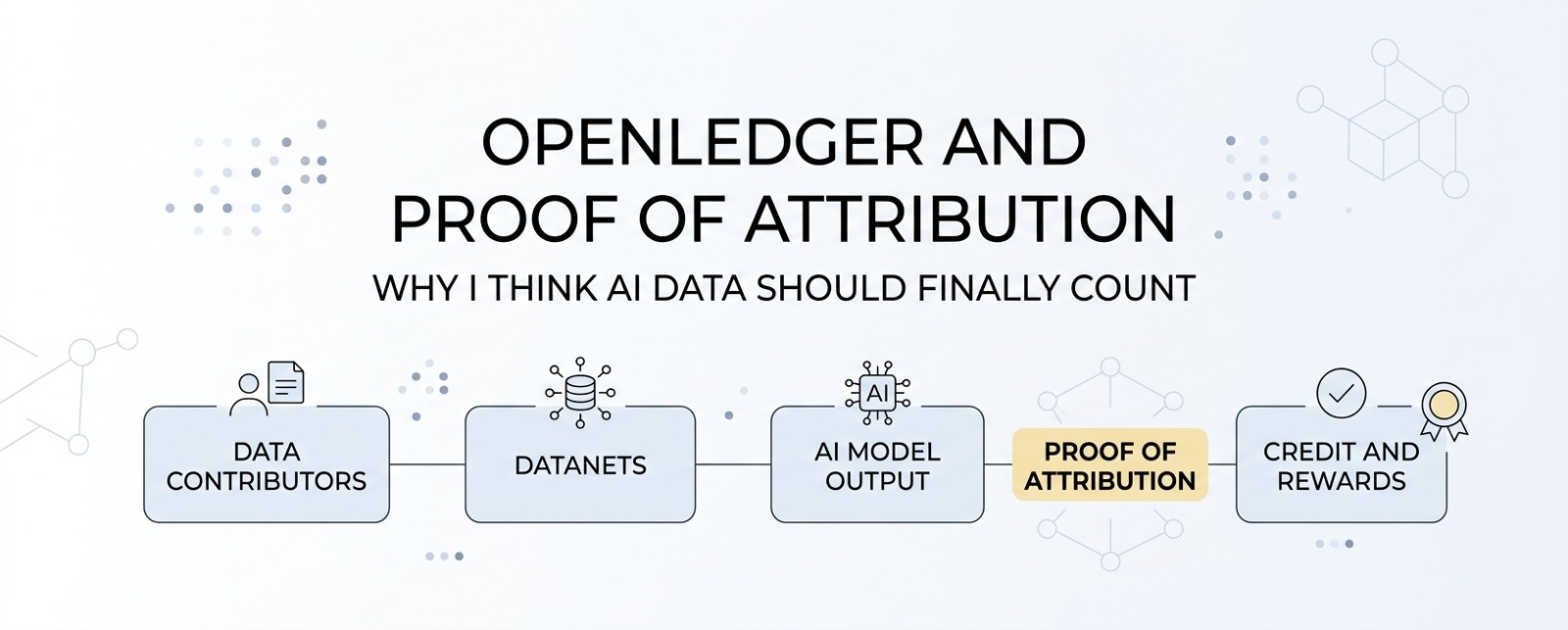
Openledger sta cercando di colmare questo gap con un sistema AI-blockchain costruito attorno a dataset di proprietà della comunità chiamati datanets. Vedo i datanets come piscine di dati focalizzate dove le persone possono contribuire con informazioni utili per modelli AI specializzati. Questo è importante perché i dati generali non sono sempre sufficienti. Alcuni casi d'uso dell'AI hanno bisogno di dati più puliti, più profondi e più specifici.
È qui che la prova di attribuzione diventa importante.
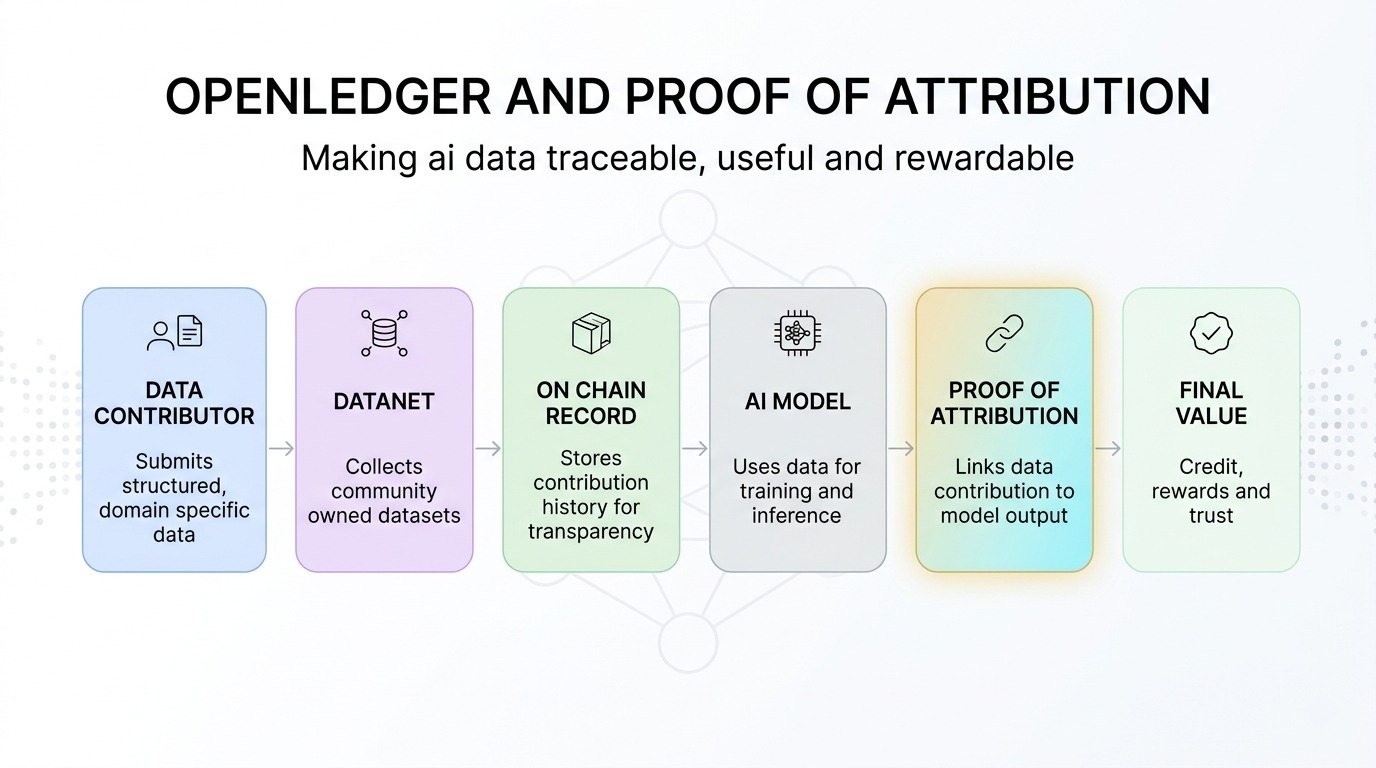
Per me, la prova di attribuzione sembra un sistema di ricevute per i dati AI. È progettato per collegare i contributi di dati con le uscite dei modelli AI. In parole semplici, se una persona aggiunge dati utili e quei dati aiutano il modello a performare meglio, il sistema mira a rendere quel contributo tracciabile.
Mi piace questa idea perché cambia il nostro modo di pensare al valore dell'AI.
Oggi, molte persone parlano di modelli, token e app. Ma meno persone parlano del layer dati dietro di essi. Penso che l'approccio di #OpenLedger sia interessante perché avvicina il contributore alla catena del valore. Non tratta i dati come una risorsa nascosta. Tratta i dati come qualcosa che può essere verificato, tracciato e premiato.
Questo potrebbe anche migliorare la qualità dei dati. Se i contributori sanno che il loro lavoro può essere riconosciuto, hanno più motivi per fornire dati utili invece di informazioni casuali.
Comunque, non direi che sia un problema facile. Tracciare l'influenza dei dati reali nell'AI è difficile. L'idea sembra forte, ma la vera prova è se openledger può rendere l'attribuzione accurata su larga scala.
Per me, il punto chiave è semplice. Il futuro dell'AI non dovrebbe solo premiare il proprietario del modello. Dovrebbe anche riconoscere le persone dietro ai dati.