这几天半夜刷安安广场差点给我整精神了,首页全是OpenLedger(OPEN)的影子,说心里话第一眼我也以为是哪个新出的土狗盘准备收割,正打算划走,结果越看越不对劲,这帮人居然在纠结一件咱们早就麻木了的事:凭啥AI吃了咱们这么多年的数据,一分钱都不给?
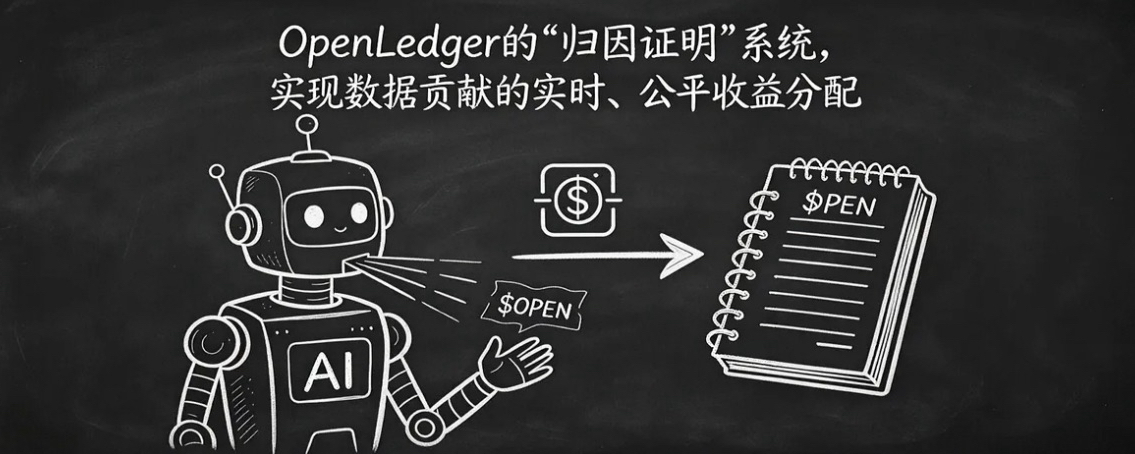
我觉得这事儿简直讽刺到家了。回想一下,这十几年来咱们在网上发动态、晒照片、写代码,互联网大厂靠这些赚得盆满钵满,咱们拿到过一分钱吗?现在轮到AI大模型把这些数据全部吞进去训练,咱们还是只能喝西北风。OpenLedger想干的活儿,就是要把这笔烂账算清楚,他们搞了个叫“归因证明”的东西,听着高大上,其实就是个公平的记账系统。逻辑特别简单:以后AI每次吐出答案,系统都能算出这句话里哪部分用了你的数据,然后当场给你打钱。这跟以前那种让你存数据等着涨价的“数据仓库”完全两码事,这是个“活”的系统,只要你的数据被用了,收益实时结算,这要是真跑通了,那绝对是生产关系的大升级。
更有意思的是他们的玩法,我看着特别像当年的YouTube。谁都能往上面传东西,不管是你的毕业论文、珍藏的代码,还是你在贴吧发的冷门知识,只要被AI模型调用了,你就能变现。为了防止有人瞎传垃圾糊弄事,他们还弄了个质押机制,想上传数据得先押点币当保证金,要是你传的是废料,钱就被扣了,这招在Web3里特别常见。我还特意去看了眼他们的技术底子,是基于OP Stack和EigenDA做的Layer 2,这就比较稳了,没敢瞎搞野路子。查了下,他们主网和那个归因系统今年9月刚上线,动作不算慢,最关键的是代币$OPEN 已经上了币安,还有Polychain、Borderless这些顶级机构背书,这就说明不是那种随便圈钱的野鸡项目。
但是啊,作为在这个圈子里被反复教育过的老韭菜,我必须得泼点冷水。虽然这愿景看着美好,但落地难度简直是地狱级的。我最大的疑问就是这个“归因”到底准不准?大家都知道AI是个黑盒子,它学完之后吐出来的东西,你怎么能精确证明是哪条数据起的作用?如果算不清楚,那所谓的公平分配不就成了糊涂账?还有就是防作弊,一旦真能赚钱,那些搞工作室的肯定会冲进来传海量垃圾数据薅羊毛,那个质押惩罚机制能不能挡住这波洪流,现在还得打个问号。我也看了下竞品,像Vana走的是数据主权路线,逻辑比较直白,而OpenLedger死磕这种复杂的“归因证明”,更像是一场豪赌。
在我看来,@OpenLedger 是个野心巨大的基础设施实验,现在的估值里装满了大家对未来的幻想。这项目能不能成,关键就看接下来这半年。如果他们的算法真能扛住几十亿次调用的考验,那OPEN这波叙事就算立住了;要是最后发现只是个好看的概念,那故事讲完也就散了。反正我会一直盯着他们的链上数据看,毕竟咱们炒币的,光听故事不行,还得看疗效。这只是我个人熬夜整理的研究笔记,绝对不构成投资建议,大家DYOR。#OpenLedger $OPEN 
