I wasn't looking for anything specific. Saw $OPEN mentioned in a feed, clicked through, started reading about the Proof of Attribution system — and then I just… stayed there longer than I expected.
Here's the thing that clicked.
Everyone frames @OpenLedger as a data ownership story. Upload your data, own your contribution, earn from AI. That's the pitch. That's the narrative the whole #OpenLedger community rallies around. And on the surface it makes sense — finally, a system where the people who actually fed the machine get a cut.
But the more I read into how Proof of Attribution actually works mechanically, the more I realized the ownership framing is only half the story. The part people keep glossing over is when the reward actually triggers.
You don't earn at upload. You earn at inference.
The payout only happens when a model gets queried — when someone runs it, uses it, asks it something. Your data sitting in a Datanet, verified, attributed, recorded on-chain? Still dormant economically until a developer's model actually gets called. The $OPEN distribution flows from inference fees, split among model developers, stakers, and data contributors at the moment of use.
I thought this was a minor technical detail at first. But actually… it changes the whole picture.
Because it means the economic value of your contribution isn't determined by what you put in. It's determined by how often the model built on top of your contribution gets used. You're not monetizing your data. You're taking a passive stake in someone else's model's adoption curve. Those are very different things.
And I'm not sure most people uploading to Datanets right now understand that distinction.
The contributor who benefits most isn't the one with the highest quality data necessarily. It's the one whose data happened to flow into a model that a developer built well and promoted aggressively enough to generate consistent inference volume. That's a very different bet than "my data is valuable, I should be rewarded."
But here's the part that still bothers me.
If inference volume is what actually unlocks the economics — and right now inference volume is thin by any honest measure, the network launched mainnet only in November 2025 — then the fair monetization story is mostly prospective. It's a design that works beautifully when there's demand. What it can't do is manufacture that demand. The attribution engine is sound. The payout logic is elegant. But if inference requests aren't flowing at scale, the data contributors sitting in Datanets are just… waiting.
I kept going back to that. The mechanism is real. The fairness layer is genuinely novel. But the thing that makes it economically meaningful — query volume, consistent model usage, developers choosing to build here over every other AI infra option — that part isn't guaranteed by the design. It has to be earned in market.
Which is probably obvious in hindsight. But the way it's presented, you'd think uploading good data was enough. It isn't. It's a starting condition, not a sufficient one.
Anyway. Still watching how the inference side develops over the next quarter. That's the actual number to track — not price, not community size. How many models are getting called, and how often.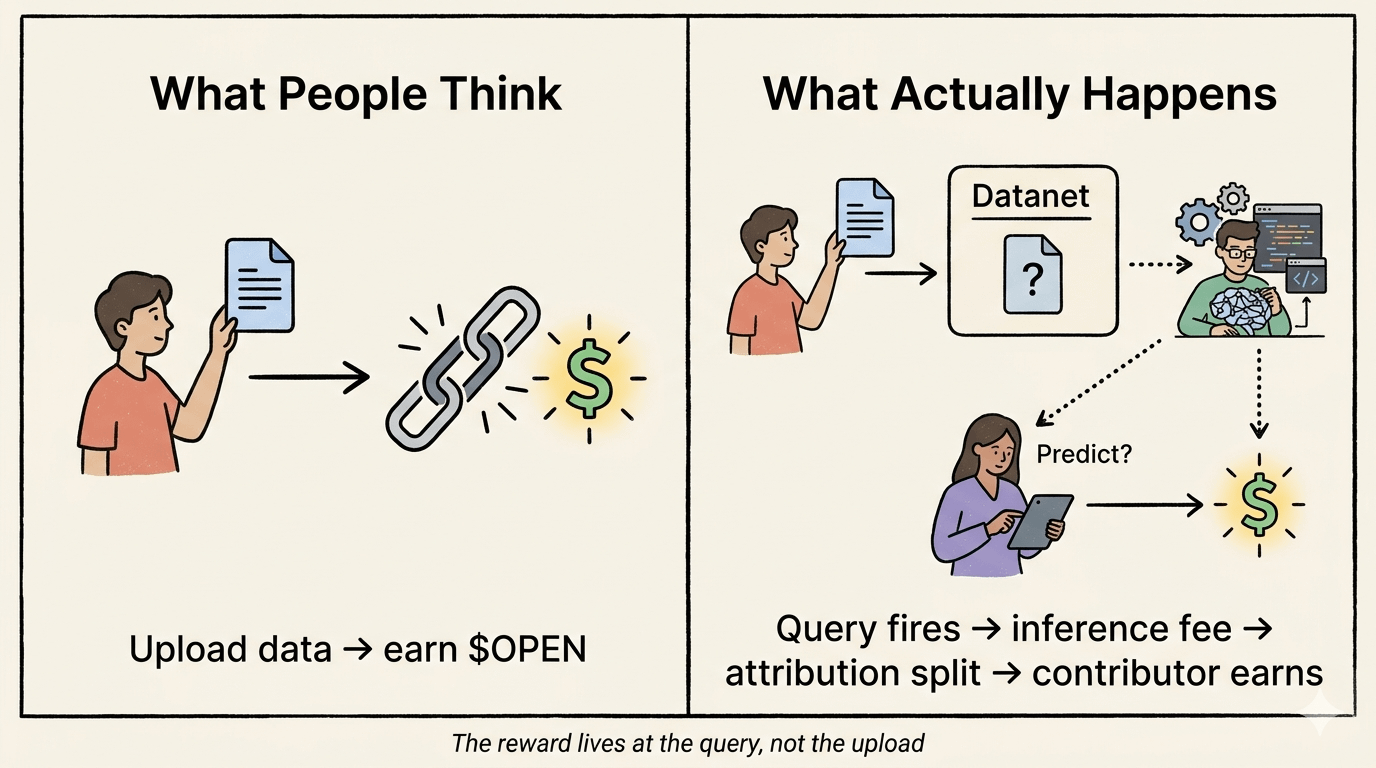
Everything else is just infrastructure waiting for a reason to run.