Someone dropped a mention of @OpenLedger in a thread I was half-reading. Not a shill post. More like a quiet observation: "what happens to the people who actually trained these models?"
I kept scrolling. Then came back to it.
So I started looking into OpenLedger properly. And the surface pitch is easy enough to absorb — decentralized AI infrastructure, on-chain data provenance, contributors getting recognized for their inputs. Fine. I've seen variations of this framing before.
But then something sat differently when I read further.
The thing OpenLedger is actually attempting isn't really about building better AI. It's about creating economic memory for AI contribution. Which sounds like a small distinction — until you realize almost no one in the current AI economy has this.
Think about it for a second.
Right now, the people who label data, curate datasets, write synthetic prompts, fine-tune domain-specific models — they contribute something real and then... it dissolves. The model improves. The company benefits. The contributor gets a one-time payment if they're lucky, or nothing if they weren't in the right contract. There's no trail. No attribution. No compounding return.
OpenLedger is essentially arguing: what if contribution didn't disappear?
I thought the interesting part was the tech at first. But actually — it's the economic design underneath.
The way it's structured, data contributions get logged on-chain with verifiable provenance. That log doesn't just sit there for compliance reasons. It's supposed to feed into how value flows back when that data gets used downstream. So if a contributor's dataset ends up being foundational to a model that gets commercially deployed, there's a mechanism — at least in theory — for that to matter financially.
That's the part people are mostly skipping past.
Everyone's comparing OpenLedger to other decentralized AI projects on infrastructure terms. Compute efficiency, model performance, token incentives. And sure, those comparisons make sense on the surface.
But the actual bet here is quieter and weirder: that AI development has an attribution problem, not just a performance problem.
Here's the part that bothers me though.
Attribution in AI is genuinely hard. Not politically hard. Technically hard. Even if you log every data contribution perfectly — tracing which specific inputs actually moved the needle on a model's capability is a problem that researchers haven't solved cleanly. Models don't learn linearly. Data interacts with other data. One person's labeled images might matter enormously or barely at all, and there's no clean way to know.
So when I try to picture how OpenLedger's reward mechanisms actually distribute value in practice... I'm not fully convinced this holds under pressure. The on-chain record can be pristine and the attribution logic can still be arbitrary.
That's not a dealbreaker. It might just be version one of a hard problem. But it's the gap between what sounds correct in the whitepaper and what gets messy when you deploy it against real model training pipelines with millions of contributors and non-linear outcomes.
The other thing I keep sitting with — who actually uses this?
Not in a dismissive way. Genuinely. The contributors who would benefit most from this system are probably not the ones already plugged into crypto infrastructure. They're researchers, domain experts, niche dataset curators. Getting that population to operate on-chain, trust a token-based reward mechanism, and persist through the early ugly version of the product... that's a real adoption gap.
It doesn't mean it fails. Early internet infrastructure had similar problems with onboarding people who didn't think like engineers.
But it does mean the success condition isn't just "does the tech work." It's "does the economic recognition actually reach the people it's designed for."
There's something in here that feels like it matters more than the average infrastructure play. Maybe because it's pointing at a problem that's going to get louder — not quieter — as AI models get more commercially dominant and the question of "who contributed to this?" becomes harder to ignore.
Or maybe it gets quietly absorbed into a larger player's roadmap and the attribution logic never matures past a whitepaper promise.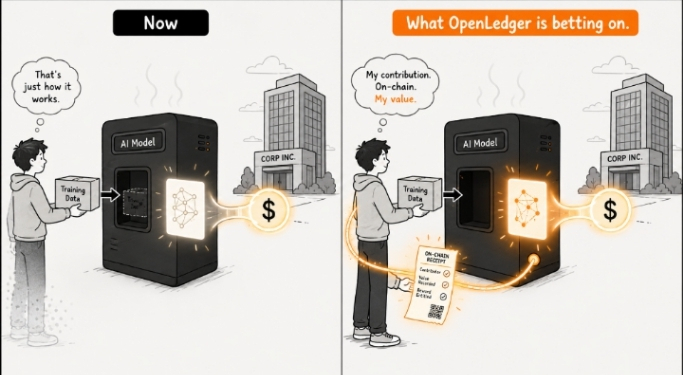
Honestly, market still looks uncertain and I've got tabs open I haven't finished reading. I'll probably just watch how this one develops.