Autore: 0xjacobzhao | https://linktr.ee/0xjacobzhao
Questo rapporto di ricerca indipendente è supportato da IOSG Ventures, il processo di ricerca e scrittura è stato ispirato dal rapporto di ricerca sul rafforzamento dell'apprendimento di Sam Lehman (Pantera Capital); grazie a Ben Fielding (Gensyn.ai), Gao Yuan (Gradient), Samuel Dare & Erfan Miahi (Covenant AI), Shashank Yadav (Fraction AI), Chao Wang per i preziosi suggerimenti forniti su questo articolo. Questo articolo cerca di mantenere un contenuto obiettivo e preciso, alcune opinioni coinvolgono giudizi soggettivi, inevitabilmente esistono delle deviazioni, si prega di comprendere.
L'intelligenza artificiale sta passando da un apprendimento statistico principalmente basato sul "fitting dei modelli" a un sistema di capacità incentrato sul "ragionamento strutturato", con l'importanza del post-training che sta rapidamente aumentando. L'emergere di DeepSeek-R1 segna un cambio di paradigma nel rafforzamento dell'apprendimento nell'era dei grandi modelli; si è formata una consapevolezza comune nel settore: la pre-formazione costruisce una base di capacità generali per i modelli, e il rafforzamento dell'apprendimento non è più solo uno strumento di allineamento dei valori, ma si è dimostrato in grado di migliorare sistematicamente la qualità della catena di ragionamento e la capacità di decisione complessa, evolvendosi gradualmente in un percorso tecnologico per migliorare continuamente il livello di intelligenza.
Nel frattempo, Web3 sta ricostruendo le relazioni di produzione dell'AI attraverso reti di calcolo decentralizzate e sistemi di incentivi crittografici, mentre l'apprendimento rinforzato richiede strutturalmente campionamenti rollout, segnali di ricompensa e addestramento verificabile, che si adattano perfettamente alla cooperazione di calcolo, distribuzione di incentivi e esecuzione verificabile della blockchain. Questo rapporto di ricerca analizzerà sistematicamente il paradigma di addestramento dell'AI e i principi tecnici dell'apprendimento rinforzato, dimostrando i vantaggi strutturali di RL × Web3 e analizzando progetti come Prime Intellect, Gensyn, Nous Research, Gradient, Grail e Fraction AI.
1. Le tre fasi dell'addestramento AI: pre-addestramento, fine-tuning delle istruzioni e allineamento del post-addestramento
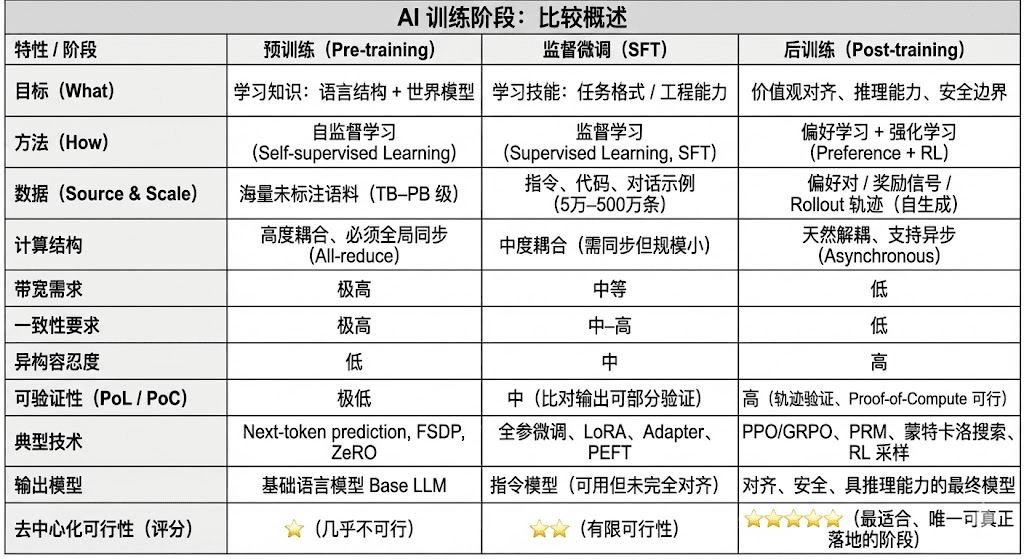
Il ciclo di vita completo del training dei moderni grandi modelli di linguaggio (LLM) è tipicamente suddiviso in tre fasi centrali: pre-addestramento (Pre-training), fine-tuning supervisionato (SFT) e post-addestramento (Post-training/RL). Ognuna di queste assume funzioni di "costruzione di un modello mondiale - iniezione delle capacità di compito - formazione di ragionamento e valori", le loro strutture computazionali, requisiti di dati e difficoltà di verifica determinano il grado di corrispondenza per la decentralizzazione.
Il pre-addestramento (Pre-training) costruisce la struttura statistica linguistica del modello e un modello mondiale cross-modale attraverso un apprendimento auto-supervisionato su larga scala, fondamentale per le capacità LLM. Questa fase richiede addestramento su trilioni di dati in modo globalmente sincronizzato, dipendendo da cluster omogenei di migliaia a decine di migliaia di H100, con costi che raggiungono l'80-95%, estremamente sensibili a larghezze di banda e diritti d'autore sui dati, quindi deve essere completata in un ambiente altamente centralizzato.
Il fine-tuning (Supervised Fine-tuning) serve a iniettare capacità di task e formati di istruzioni, con volumi di dati piccoli, costi pari a circa il 5-15%, il fine-tuning può essere effettuato sia con addestramento completo che con metodi di fine-tuning efficienti in parametri (PEFT), tra cui LoRA, Q-LoRA e Adapter, che sono i più comuni nel settore. Tuttavia, richiede ancora la sincronizzazione dei gradienti, limitando quindi il suo potenziale di decentralizzazione.
Il post-addestramento (Post-training) è composto da più sotto-fasi iterative, determinando la capacità di ragionamento, i valori e i confini di sicurezza del modello, i metodi includono sia sistemi di apprendimento rinforzato (RLHF, RLAIF, GRPO) che metodi di ottimizzazione delle preferenze senza RL (DPO), così come modelli di ricompensa del processo (PRM). Questa fase ha un basso volume di dati e costi (5-10%), concentrandosi principalmente su rollout e aggiornamento delle politiche; supporta naturalmente l'esecuzione asincrona e distribuita, i nodi non devono detenere pesi completi, combinando il calcolo verificabile con incentivi on-chain per formare una rete di addestramento decentralizzata aperta, la fase più adatta per Web3.
2. Panorama della tecnologia dell'apprendimento rinforzato: architettura, framework e applicazioni
2.1 Architettura di sistema dell'apprendimento rinforzato e fasi chiave
L'apprendimento rinforzato (Reinforcement Learning, RL) guida il miglioramento autonomo delle capacità decisionali dei modelli attraverso "interazione ambientale - feedback di ricompensa - aggiornamento delle politiche", la sua struttura centrale può essere vista come un ciclo di feedback composto da stati, azioni, ricompense e politiche. Un sistema RL completo di solito include tre tipi di componenti: Policy (rete di politiche), Rollout (campionamento esperienziale) e Learner (aggiornamento delle politiche). Le politiche interagiscono con l'ambiente per generare traiettorie, il Learner aggiorna le politiche in base ai segnali di ricompensa, formando un processo di apprendimento continuo, iterativo e sempre ottimizzato:
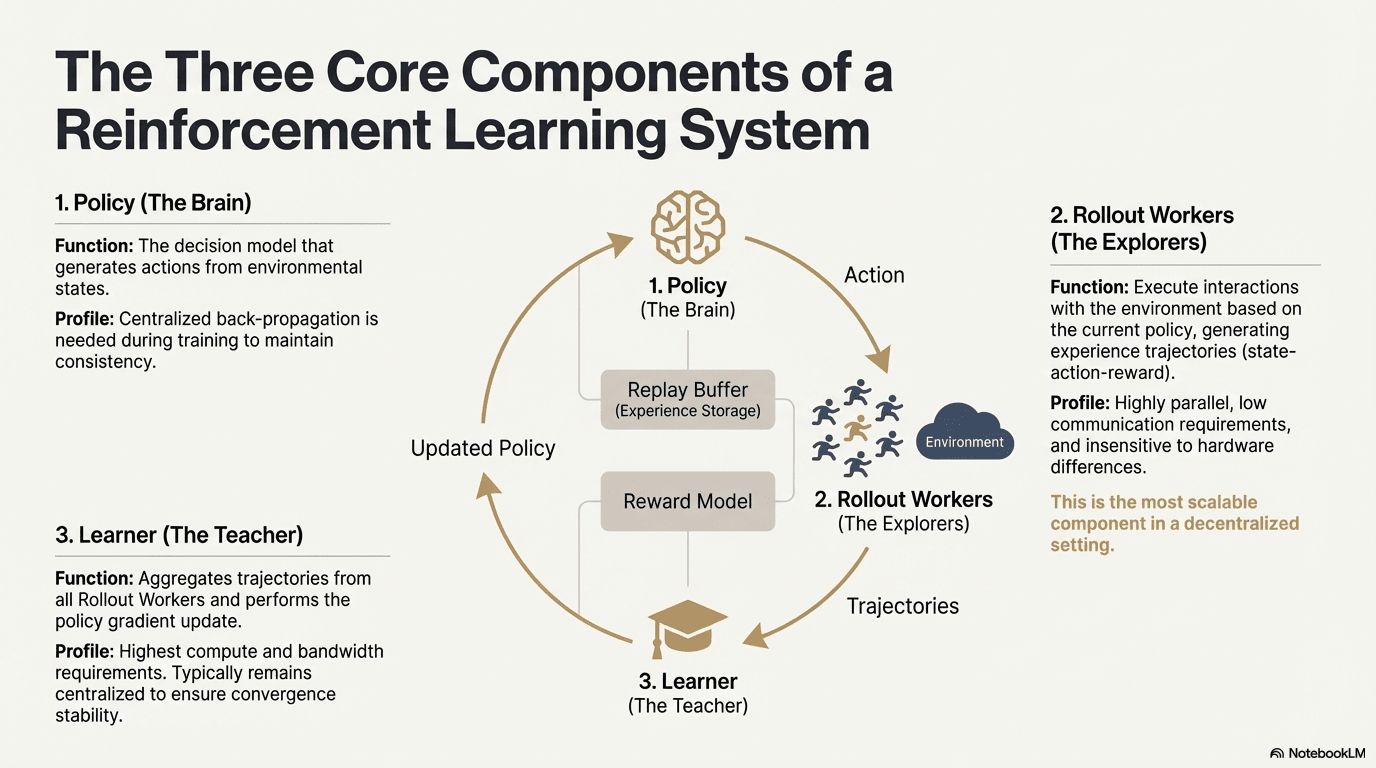
Rete di politiche (Policy): genera azioni dallo stato ambientale, è il nucleo decisionale del sistema. Durante l'addestramento, è necessaria una retropropagazione centralizzata per mantenere la coerenza; durante l'inferenza può essere distribuita su diversi nodi per funzionare in parallelo.
Campionamento esperienziale (Rollout): i nodi interagiscono con l'ambiente secondo le politiche, generando traiettorie di stato-azione-ricompensa, ecc. Questo processo è altamente parallelo con comunicazioni estremamente basse ed è insensibile alle differenze hardware, rendendolo il segmento più adatto per l'espansione decentralizzata.
Apprendista (Learner): aggrega tutte le traiettorie di rollout ed esegue l'aggiornamento del gradiente delle politiche, è il modulo che richiede le più alte capacità di calcolo e larghezza di banda, quindi di solito è mantenuto centralizzato o leggermente centralizzato per garantire stabilità di convergenza.
2.2 Struttura della fase di apprendimento rinforzato (RLHF → RLAIF → PRM → GRPO)
L'apprendimento rinforzato può generalmente essere suddiviso in cinque fasi, il processo complessivo è descritto di seguito:
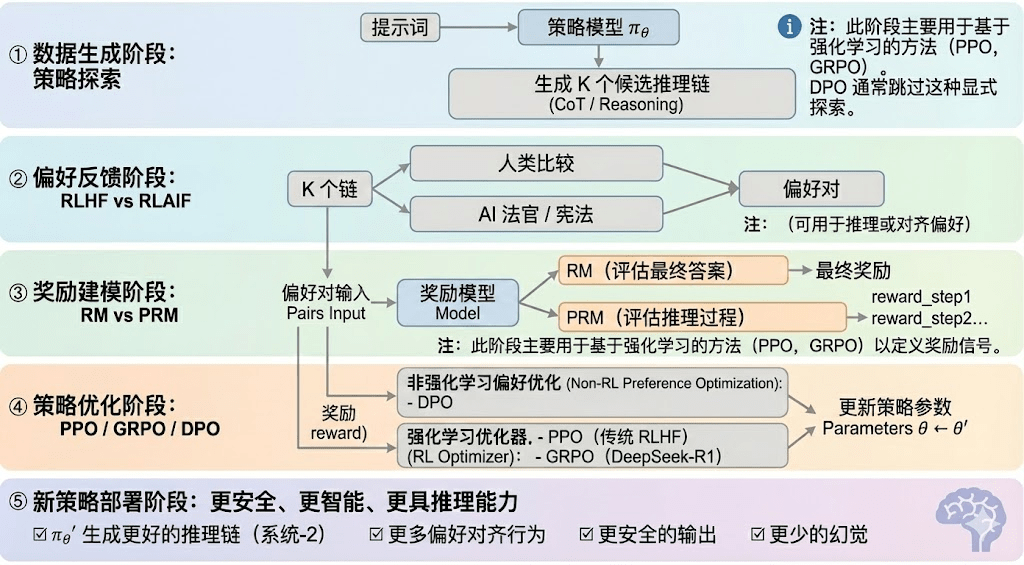
Fase di generazione dati (Policy Exploration): sotto condizioni di input fornite, il modello di politica πθ genera più catene di inferenza candidati o traiettorie complete, fornendo una base di campioni per la successiva valutazione delle preferenze e modellazione delle ricompense, determinando l'ampiezza dell'esplorazione delle politiche.
Fase di feedback delle preferenze (RLHF / RLAIF):
RLHF (Reinforcement Learning from Human Feedback) ottimizza le uscite del modello per allinearle ai valori umani attraverso risposte multiple, annotazione delle preferenze umane e addestramento di modelli di ricompensa (RM) utilizzando PPO, rappresentando un passaggio chiave da GPT-3.5 a GPT-4.
RLAIF (Reinforcement Learning from AI Feedback) automatizza l'acquisizione delle preferenze utilizzando giudici AI o regole di tipo costituzionale, riducendo significativamente i costi e dotandosi di caratteristiche scalabili, diventando il paradigma di allineamento principale per Anthropic, OpenAI, DeepSeek, ecc.
Fase di modellazione delle ricompense (Reward Modeling): le preferenze influenzano il modello di ricompensa, apprendendo a mappare le uscite in ricompense. RM insegna al modello "qual è la risposta corretta", PRM insegna al modello "come ragionare correttamente".
RM (Reward Model) serve a valutare la bontà delle risposte finali, assegnando punteggi solo alle uscite:
Modello di ricompensa del processo PRM (Process Reward Model) non valuta più solo le risposte finali, ma assegna punteggi a ogni passo di ragionamento, a ogni token, a ogni segmento logico, rappresentando anche una tecnologia chiave di OpenAI o1 e DeepSeek-R1, fondamentalmente "insegnando al modello come pensare".
Fase di verifica delle ricompense (RLVR / Reward Verifiability): introduce vincoli di "verificabilità" nel processo di generazione e utilizzo dei segnali di ricompensa, affinché le ricompense provengano da regole, fatti o consensi riproducibili, riducendo i rischi di reward hacking e deviazione, migliorando la verificabilità e scalabilità in ambienti aperti.
Fase di ottimizzazione delle politiche (Policy Optimization): aggiornamento dei parametri delle politiche in base ai segnali forniti dal modello di ricompensa, per ottenere politiche πθ′ con maggiore capacità inferenziale, maggiore sicurezza e modelli comportamentali più stabili. Le principali modalità di ottimizzazione includono:
PPO (Proximal Policy Optimization): ottimizzatore tradizionale di RLHF, noto per la sua stabilità, ma spesso affronta limiti di convergenza lenta e instabilità in compiti di ragionamento complessi.
GRPO (Group Relative Policy Optimization): innovazione centrale di DeepSeek-R1, stima il valore atteso modellando la distribuzione dei vantaggi all'interno di un gruppo di risposte, piuttosto che semplicemente ordinandole. Questo metodo conserva le informazioni sull'ampiezza delle ricompense, rendendolo più adatto all'ottimizzazione delle catene di ragionamento, con un processo di addestramento più stabile, considerato un importante framework di ottimizzazione dell'apprendimento rinforzato per scenari di ragionamento profondo dopo PPO.
DPO (Direct Preference Optimization): metodo di post-addestramento non rinforzato: non genera traiettorie né costruisce modelli di ricompensa, ma ottimizza direttamente sulle preferenze, a basso costo e con risultati stabili, ampiamente utilizzato per l'allineamento di modelli open source come Llama, Gemma, senza migliorare la capacità inferenziale.
Fase di distribuzione della nuova politica (New Policy Deployment): il modello ottimizzato si manifesta in capacità di generazione di catene di ragionamento più forti (System-2 Reasoning), comportamenti più allineati ai valori umani o AI, tassi di allucinazione più bassi e maggiore sicurezza. Il modello apprende continuamente preferenze, ottimizza il processo e migliora la qualità decisionale, formando un ciclo chiuso.

2.3 Cinque categorie principali delle applicazioni industriali dell'apprendimento rinforzato
L'apprendimento rinforzato (Reinforcement Learning) è evoluto da un'intelligenza di gioco precocemente sviluppata a un framework centrale di decisione autonoma trasversale all'industria, i suoi casi d'uso possono essere classificati in cinque categorie in base al grado di maturità tecnica e attuazione industriale, spingendo avanti le principali scoperte in ciascuna direzione.
Sistemi di gioco e strategia (Game & Strategy): questo è il primo campo in cui l'RL è stato convalidato, in ambienti di "informazione perfetta + ricompensa chiara" come AlphaGo, AlphaZero, AlphaStar, OpenAI Five, l'RL ha mostrato capacità decisionali in grado di competere e persino superare gli esperti umani, ponendo le basi per gli algoritmi di RL moderni.
Robotica e intelligenza incarnata (Embodied AI): l'RL fa apprendere ai robot il controllo, la modellazione dinamica e l'interazione ambientale attraverso il controllo continuo, sta rapidamente avanzando verso l'industrializzazione, rappresentando una chiave tecnologica per l'implementazione della robotica nel mondo reale.
Ragionamento digitale (Digital Reasoning / LLM System-2): RL + PRM guidano i grandi modelli dal "mimetismo linguistico" alla "ragionamento strutturato", i risultati rappresentativi includono DeepSeek-R1, OpenAI o1/o3, Claude di Anthropic e AlphaGeometry, la loro essenza consiste nell'ottimizzazione delle ricompense a livello di catena di ragionamento, piuttosto che una semplice valutazione delle risposte finali.
Scoperta scientifica automatizzata e ottimizzazione matematica (Scientific Discovery): l'RL cerca strutture o strategie ottimali in spazi di ricerca enormi, complessi e senza etichette, realizzando fondamentali progressi come AlphaTensor, AlphaDev, Fusion RL, mostrando capacità esplorative superiori all'intuizione umana.
Decisioni economiche e sistemi di trading (Economic Decision-making & Trading): l'RL è utilizzato per ottimizzare strategie, controllare rischi ad alta dimensione e generare sistemi di trading adattivi, capace di apprendere in modo continuo in ambienti incerti, è una parte fondamentale della finanza intelligente.
3. La corrispondenza naturale tra apprendimento rinforzato e Web3
L'integrazione dell'apprendimento rinforzato (RL) e Web3 deriva dalla loro essenza comune di "sistemi guidati da incentivi". RL dipende dai segnali di ricompensa per ottimizzare le politiche, mentre la blockchain coordina il comportamento dei partecipanti attraverso incentivi economici, rendendo i due naturalmente coerenti a livello meccanico. Le esigenze fondamentali di RL - rollout eterogenei su larga scala, distribuzione delle ricompense e verifica della veridicità - sono i vantaggi strutturali di Web3.
Separazione di inferenza e addestramento: il processo di addestramento dell'apprendimento rinforzato può essere chiaramente suddiviso in due fasi:
Rollout (campionamento esplorativo): il modello genera un gran numero di dati basati sulla strategia attuale, è un compito ad alta intensità computazionale ma con comunicazioni scarse. Non richiede frequenti comunicazioni tra i nodi, rendendolo più adatto a generazioni parallele su GPU di consumo distribuite globalmente.
Aggiornamento (aggiornamento dei parametri): aggiornamento dei pesi del modello basato sui dati raccolti, richiede nodi centralizzati ad alta larghezza di banda per essere completato.
Il "decoupling di inferenza e addestramento" si adatta naturalmente alla struttura di calcolo eterogenea decentralizzata: il Rollout può essere esternalizzato a una rete aperta, con regolamenti basati su token che compensano in base al contributo, mentre l'aggiornamento del modello rimane centralizzato per garantire stabilità.
Verificabilità (Verifiability): ZK e Proof-of-Learning forniscono i mezzi per verificare se i nodi stanno realmente eseguendo inferenze, risolvendo il problema di onestà nelle reti aperte. In compiti deterministici come codice e ragionamento matematico, i verificatori devono solo controllare le risposte per confermare il carico di lavoro, migliorando significativamente la credibilità dei sistemi RL decentralizzati.
Livello di incentivazione, meccanismo di produzione di feedback basato sull'economia dei token: il meccanismo dei token di Web3 può premiare direttamente i contribuenti del feedback di preferenza di RLHF/RLAIF, rendendo la generazione di dati di preferenza trasparente, liquidabile e senza permessi; staking e slashing ulteriormente vincolano la qualità del feedback, formando un mercato di feedback più efficiente e allineato rispetto al tradizionale crowdsourcing.
Potenziale dell'apprendimento rinforzato multi-agente (MARL): la blockchain è essenzialmente un ambiente multi-agente pubblico, trasparente e in evoluzione continua, dove conti, contratti e agenti modificano continuamente le politiche sotto l'influsso di incentivi, rendendo naturale la costruzione di un campo di esperimenti MARL su larga scala. Sebbene sia ancora nelle fasi iniziali, le sue caratteristiche di stato pubblico, esecuzione verificabile e incentivi programmabili offrono vantaggi principiali per il futuro dello sviluppo MARL.
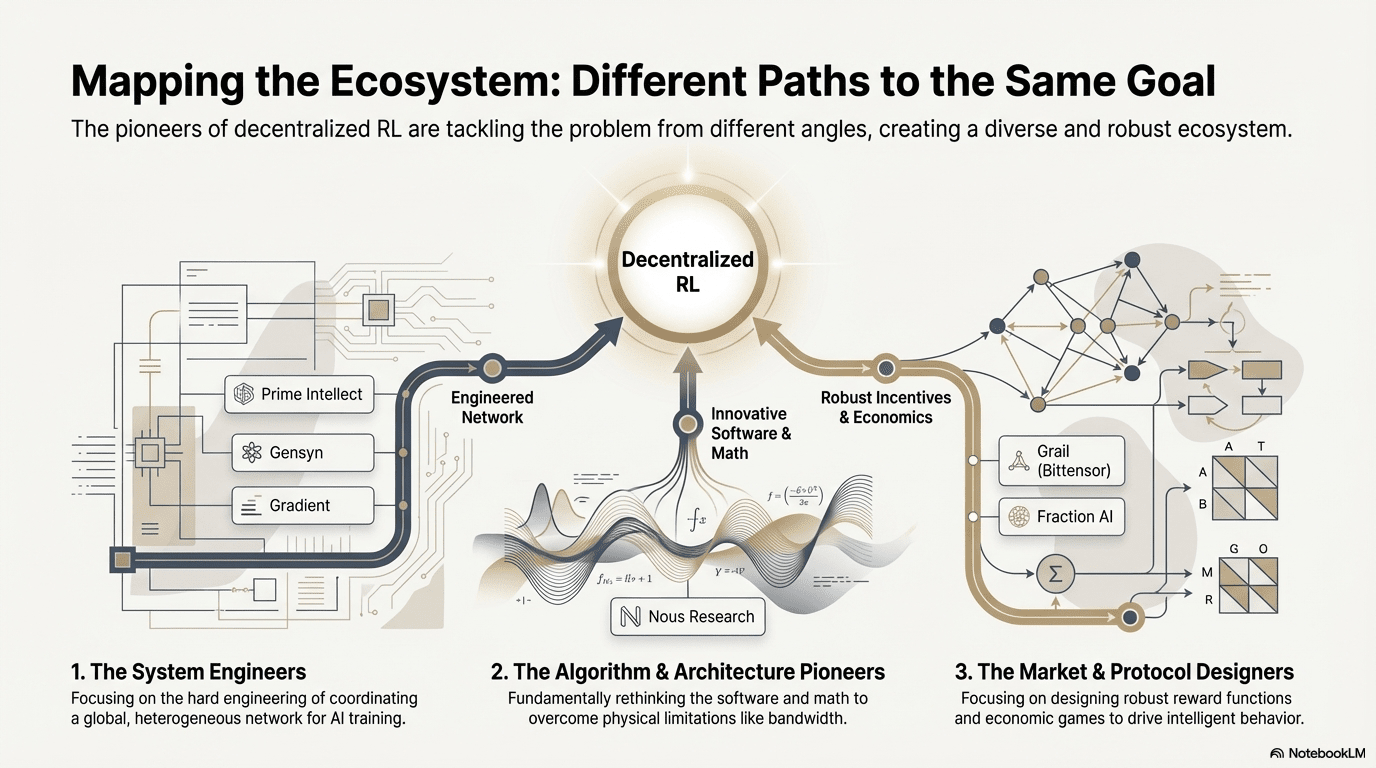
4. Analisi dei progetti classici Web3 + apprendimento rinforzato
Sulla base del framework teorico sopra esposto, procederemo ad un'analisi succinta dei progetti più rappresentativi nell'ecosistema attuale:
Prime Intellect: paradigma di apprendimento rinforzato asincrono prime-rl
Prime Intellect si impegna a costruire un mercato globale di potenza di calcolo aperto, abbassando le barriere all'addestramento, promuovendo l'addestramento decentralizzato collaborativo e sviluppando un intero stack tecnologico di super intelligenza open source. Il suo sistema include: Prime Compute (ambiente di calcolo unificato/cloud distribuito), famiglia di modelli INTELLECT (10B–100B+), centro ambientale di apprendimento rinforzato aperto (Environments Hub) e un motore di dati sintetici su larga scala (SYNTHETIC-1/2).
Il componente centrale dell'infrastruttura di Prime Intellect, il framework prime-rl, è progettato per ambienti distribuiti asincroni e altamente correlati all'apprendimento rinforzato, gli altri includono il protocollo di comunicazione OpenDiLoCo che supera il collo di bottiglia della larghezza di banda e il meccanismo di verifica TopLoc che garantisce l'integrità computazionale.
Panoramica dei componenti chiave dell'infrastruttura di Prime Intellect

Fondamento tecnologico: framework di apprendimento rinforzato asincrono prime-rl
prime-rl è il motore di addestramento centrale di Prime Intellect, progettato per ambienti decentralizzati asincroni su larga scala, implementando un completo decoupling tra inferenza ad alta capacità e aggiornamenti stabili attraverso l'architettura Actor–Learner. Gli esecutori (Rollout Worker) e gli apprendisti (Trainer) non sono più bloccati in sincronizzazione, i nodi possono unirsi o uscire in qualsiasi momento, basta continuare a estrarre le politiche più recenti e caricare i dati generati.
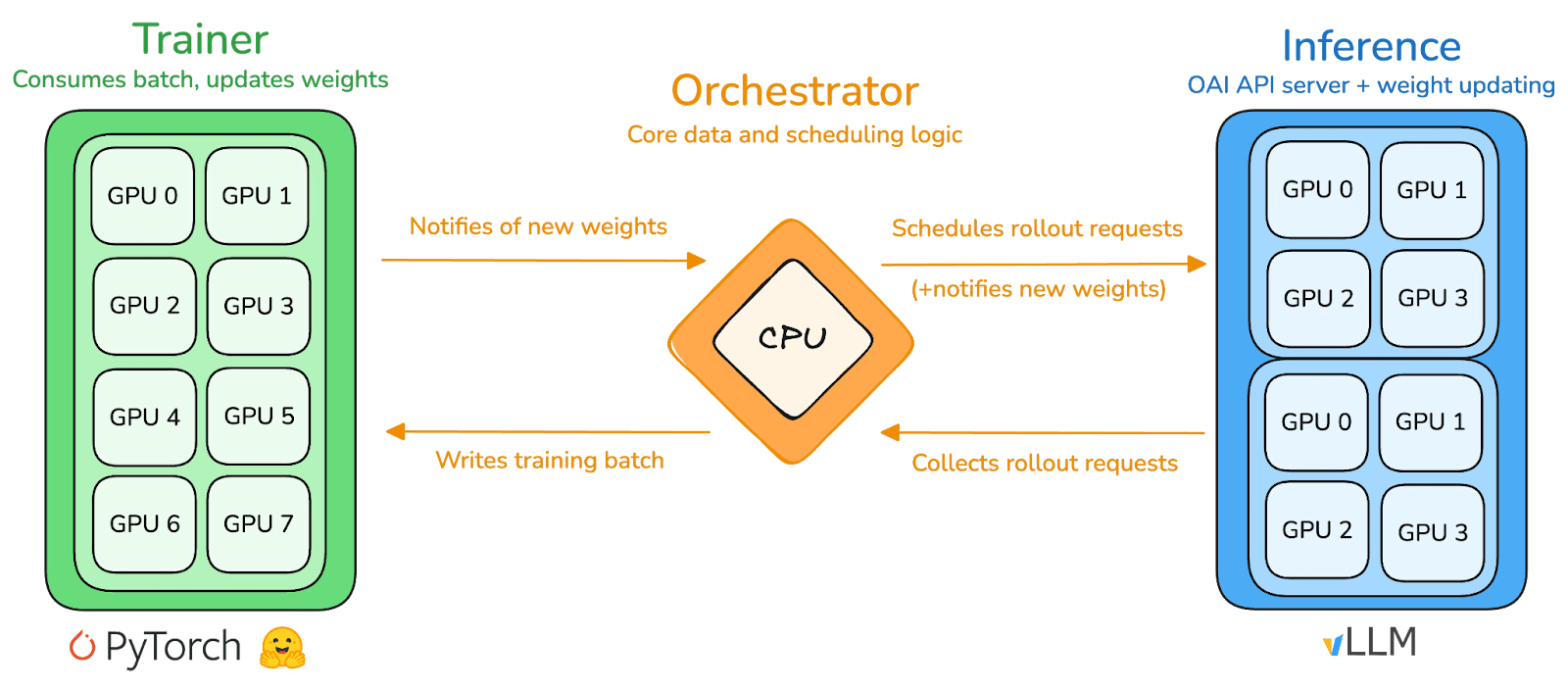
Attori esecutori (Rollout Workers): responsabili dell'inferenza del modello e della generazione di dati. Prime Intellect ha innovato integrando un motore di inferenza vLLM all'endpoint degli attori. La tecnologia PagedAttention di vLLM e la capacità di elaborazione continua (Continuous Batching) consentono agli attori di generare traiettorie inferenziali a throughput estremamente elevati.
Apprendista Learner (Trainer): responsabile dell'ottimizzazione delle politiche. L'apprendista estrae in modo asincrono i dati da un buffer di riproduzione dell'esperienza condiviso (Experience Buffer) per aggiornamenti del gradiente, senza dover attendere che tutti gli attori completino il batch attuale.
Coordinatore (Orchestrator): responsabile della programmazione dei pesi del modello e del flusso di dati.
Punti chiave dell'innovazione di prime-rl:
Vero asincrono (True Asynchrony): prime-rl abbandona il paradigma di sincronizzazione tradizionale di PPO, non attende nodi lenti e non richiede allineamento dei batch, consentendo a un numero arbitrario di GPU con prestazioni diverse di connettersi in qualsiasi momento, stabilendo la fattibilità dell'RL decentralizzato.
Integrazione profonda di FSDP2 e MoE: attraverso il tagging dei parametri di FSDP2 e attivazioni sparse di MoE, prime-rl consente a modelli da miliardi di parametri di essere addestrati in modo efficiente in ambienti distribuiti, con attori che eseguono solo esperti attivi, riducendo significativamente la memoria e i costi di inferenza.
GRPO+ (Group Relative Policy Optimization): GRPO elimina la rete Critic, riducendo significativamente i costi di calcolo e memoria, adattandosi naturalmente agli ambienti asincroni, GRPO+ di prime-rl assicura inoltre la convergenza affidabile in condizioni di alta latenza attraverso meccanismi di stabilizzazione.
Famiglia di modelli INTELLECT: simbolo della maturità della tecnologia RL decentralizzata
INTELLECT-1 (10B, ottobre 2024) ha dimostrato per la prima volta che OpenDiLoCo può addestrare in modo efficiente su una rete eterogenea che attraversa tre continenti (comunicazione <2%, utilizzo della potenza di calcolo 98%), rompendo la cognizione fisica dell'addestramento interregionale;
INTELLECT-2 (32B, aprile 2025) come primo modello RL senza permessi, verifica la stabilità di convergenza di prime-rl e GRPO+ in ambienti asincroni a più passi di latenza, realizzando un RL decentralizzato con partecipazione alla potenza di calcolo globale aperta;
INTELLECT-3 (106B MoE, novembre 2025) adotta una struttura sparsa attivando solo 12B di parametri, addestrando su 512×H200 e raggiungendo prestazioni di inferenza flagship (AIME 90.8%, GPQA 74.4%, MMLU-Pro 81.9%, ecc.), mostrando prestazioni complessive che si avvicinano e persino superano quelle di modelli chiusi centralizzati molto più grandi.
Prime Intellect ha anche costruito diverse infrastrutture di supporto: OpenDiLoCo riduce di centinaia di volte il volume di comunicazione dell'addestramento interregionale attraverso comunicazioni sparse nel tempo e differenze di pesi quantizzati, consentendo a INTELLECT-1 di mantenere il 98% di utilizzo anche su reti intercontinentali; TopLoc + Verifiers formano un livello di esecuzione decentralizzato e fidato per attivare le impronte digitali e la verifica della sandbox, garantendo la veridicità dei dati di inferenza e ricompensa; il motore di dati SYNTHETIC produce catene di inferenza di alta qualità su larga scala e consente al modello 671B di funzionare in modo efficiente su cluster GPU di consumo grazie all'elaborazione parallela in pipeline. Questi componenti forniscono una base ingegneristica fondamentale per la generazione di dati, la verifica e il throughput inferenziale dell'RL decentralizzato. La serie INTELLECT ha dimostrato che questo stack tecnologico può generare modelli di livello mondiale maturi, segnando il passaggio del sistema di addestramento decentralizzato dalla fase concettuale a quella pratica.
Gensyn: stack centrale dell'apprendimento rinforzato RL Swarm e SAPO
L'obiettivo di Gensyn è raccogliere la potenza di calcolo globale inutilizzata in un'infrastruttura di addestramento AI aperta, trustless e illimitatamente scalabile. Il suo core include un livello di esecuzione standardizzato cross-device, una rete di coordinamento peer-to-peer e un sistema di verifica dei compiti trustless, e assegna compiti e ricompense automaticamente tramite contratti intelligenti. Sulla base delle caratteristiche dell'apprendimento rinforzato, Gensyn introduce meccanismi chiave come RL Swarm, SAPO e SkipPipe, decouplando le tre fasi di generazione, valutazione e aggiornamento, utilizzando un "sciame" composto da GPU eterogenee globali per realizzare un'evoluzione collettiva. La sua consegna finale non è solo potenza di calcolo, ma intelligenza verificabile (Verifiable Intelligence).
Applicazioni di apprendimento rinforzato dello stack Gensyn

RL Swarm: motore di apprendimento rinforzato collaborativo decentralizzato
RL Swarm mostra un nuovo modello di collaborazione. Non è più una semplice distribuzione di compiti, ma un ciclo decentralizzato di "generazione-valutazione-aggiornamento" che simula l'apprendimento della società umana, in un ciclo infinito:
Solutori (esecutori): responsabili dell'inferenza del modello locale e della generazione di rollout, senza ostacoli di eterogeneità tra i nodi. Gensyn integra un motore di inferenza ad alta capacità (come CodeZero) in locale, in grado di produrre traiettorie complete e non solo risposte.
Proponenti (creatori di compiti): generano dinamicamente compiti (problemi matematici, problemi di codice, ecc.), supportando la diversità e l'adattamento della difficoltà del tipo Curriculum Learning.
Valutatori (evaluators): utilizzano un "modello giudice" congelato o regole per valutare i rollout locali, generando segnali di ricompensa locali. Il processo di valutazione può essere auditato, riducendo lo spazio per comportamenti fraudolenti.
I tre insieme formano una struttura organizzativa RL P2P, in grado di completare un apprendimento collaborativo su larga scala senza la necessità di programmazione centralizzata.
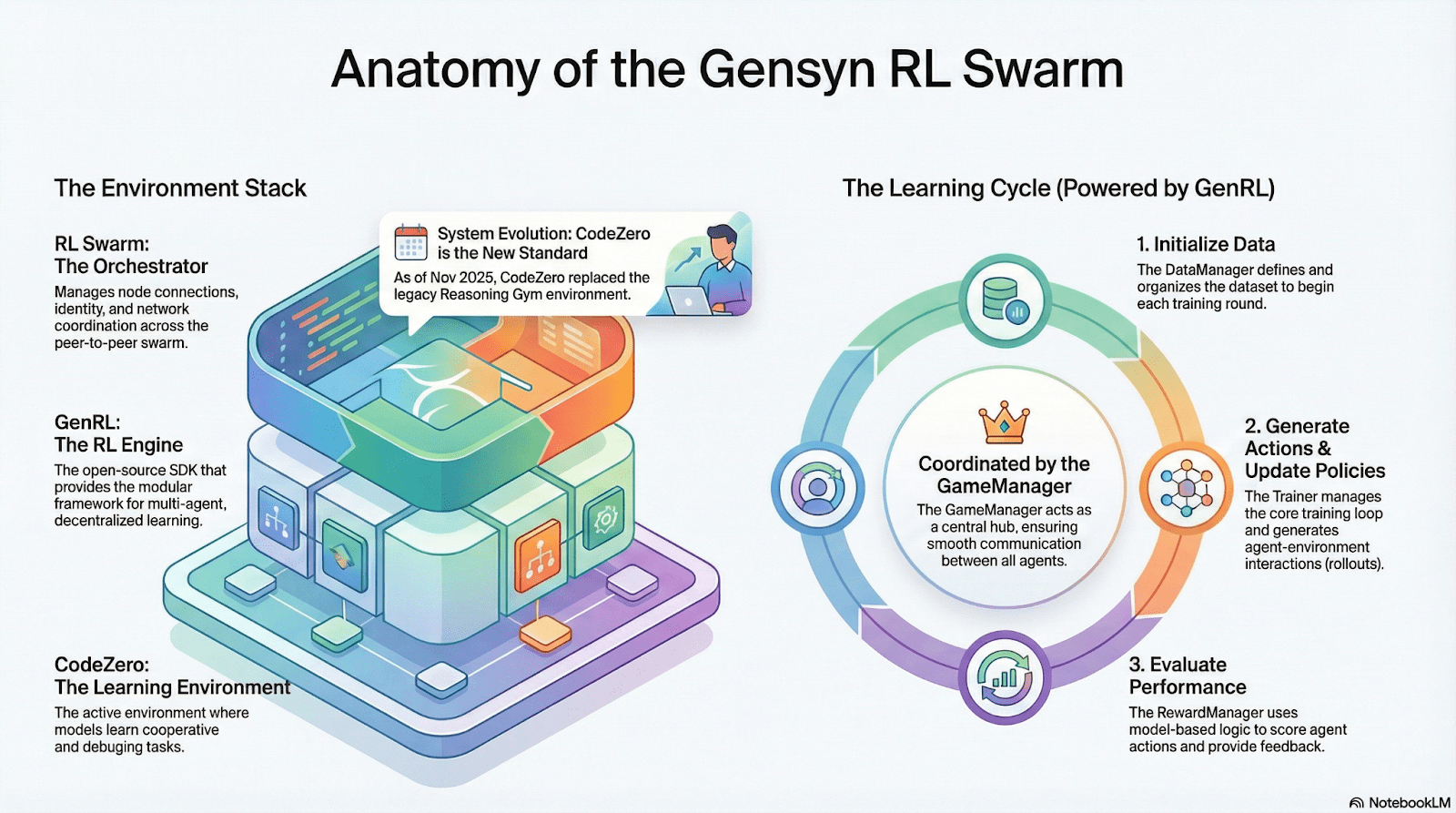
SAPO: algoritmo di ottimizzazione delle politiche ricostruito per la decentralizzazione: SAPO (Swarm Sampling Policy Optimization) si concentra su "campionamento di Rollout condiviso e filtraggio di campioni di segnali senza gradiente, piuttosto che condivisione di gradienti", mantenendo una convergenza stabile in ambienti decentralizzati senza coordinamento centrale e con differenze di latenza tra nodi, attraverso campionamenti rollout decentralizzati su larga scala e considerando i rollout ricevuti come generati localmente. Rispetto a PPO, che dipende dalla rete Critic e ha costi computazionali elevati, o a GRPO, che si basa sulla stima dei vantaggi all'interno del gruppo, SAPO consente anche a GPU di consumo di partecipare efficacemente all'ottimizzazione dell'apprendimento rinforzato su larga scala con una larghezza di banda estremamente bassa.
Attraverso RL Swarm e SAPO, Gensyn ha dimostrato che l'apprendimento rinforzato (soprattutto la fase di post-addestramento RLVR) si adatta naturalmente a un'architettura decentralizzata - perché dipende maggiormente da esplorazioni su larga scala e diversificate (Rollout), piuttosto che da sincronizzazioni di parametri ad alta frequenza. Combinando PoL e il sistema di verifica di Verde, Gensyn offre un percorso alternativo per l'addestramento di modelli con trilioni di parametri che non dipende più da un singolo gigante tecnologico: una rete di super intelligenza auto-evolutiva composta da milioni di GPU eterogenee in tutto il mondo.
Nous Research: ambiente di apprendimento rinforzato verificabile Atropos
Nous Research sta costruendo un'infrastruttura cognitiva decentralizzata e auto-evolutiva. I suoi componenti principali - Hermes, Atropos, DisTrO, Psyche e World Sim - sono organizzati in un sistema di evoluzione intelligente a ciclo chiuso continuo. Diversamente dal tradizionale processo lineare di "pre-addestramento - post-addestramento - inferenza", Nous utilizza tecniche di apprendimento rinforzato come DPO, GRPO e campionamento per rifiuto, unificando la generazione di dati, la verifica, l'apprendimento e l'inferenza in un ciclo di feedback continuo, creando un ecosistema AI a ciclo chiuso in continua auto-miglioramento.
Panoramica dei componenti di Nous Research

Livello del modello: evoluzione di Hermes e capacità inferenziali
La serie Hermes è l'interfaccia principale dei modelli di Nous Research orientata all'utente, la sua evoluzione mostra chiaramente il passaggio del settore dal tradizionale allineamento SFT/DPO all'apprendimento rinforzato per l'inferenza (Reasoning RL):
Hermes 1-3: allineamento delle istruzioni e capacità di agenti precoci: Hermes 1-3 completa un robusto allineamento delle istruzioni tramite un DPO a basso costo, e in Hermes 3 si avvale di dati sintetici e della meccanica di verifica di Atropos per la prima volta.
Hermes 4 / DeepHermes: scrive il ragionamento System-2 nei pesi attraverso catene di pensiero, migliorando le prestazioni matematiche e di codice con Test-Time Scaling, e si basa su "campionamento di rifiuto + verifica di Atropos" per costruire dati di inferenza ad alta purezza.
DeepHermes adotta ulteriormente GRPO al posto di PPO, difficile da implementare in modo distribuito, consentendo all'RL di ragionamento di funzionare nella rete GPU decentralizzata di Psyche, ponendo le basi ingegneristiche per la scalabilità dell'RL di ragionamento open source.
Atropos: Ambiente di apprendimento rinforzato guidato da ricompense verificabili
Atropos è il vero fulcro del sistema RL di Nous. Incapsula suggerimenti, chiamate a strumenti, esecuzione di codice e interazioni multiple in un ambiente RL standardizzato, consentendo la verifica diretta della correttezza dell'output, fornendo così segnali di ricompensa deterministici, in sostituzione di annotazioni umane costose e non scalabili. Più importante, nella rete di addestramento decentralizzata Psyche, Atropos funge da "giudice" per verificare se i nodi stanno realmente migliorando le politiche, supportando una prova di apprendimento auditabile, risolvendo fondamentalmente il problema della credibilità delle ricompense nell'RL distribuito.
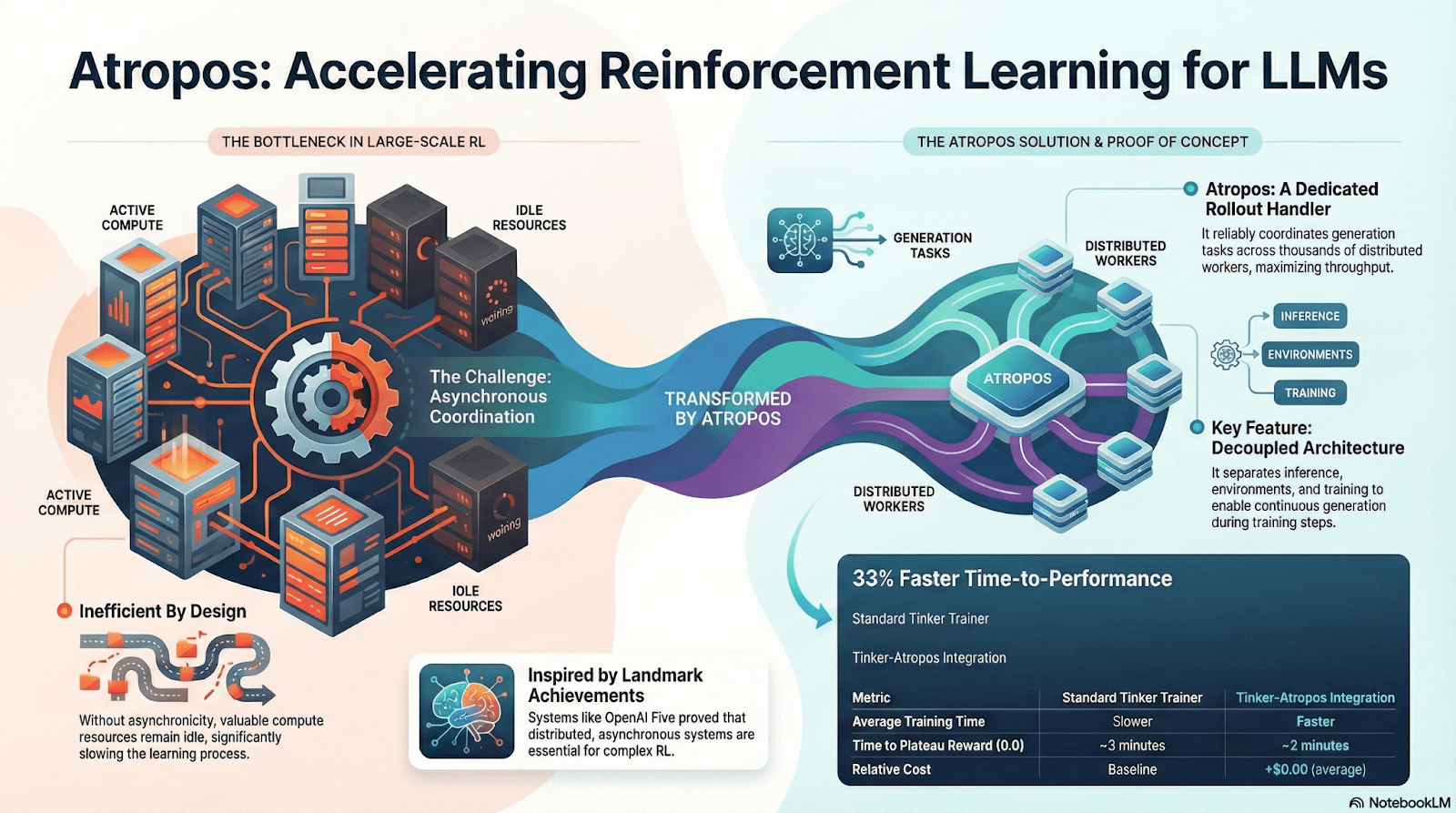
DisTrO e Psyche: il livello di ottimizzazione dell'apprendimento rinforzato decentralizzato
Il tradizionale addestramento RLF (RLHF/RLAIF) dipende da cluster centralizzati ad alta larghezza di banda, una barriera centrale che l'open source non può replicare. DisTrO abbassa i costi di comunicazione dell'RL di diversi ordini di grandezza attraverso il decoupling del momento e la compressione dei gradienti, consentendo l'addestramento su larghezza di banda di internet; Psyche implementa questo meccanismo di addestramento su reti on-chain, consentendo ai nodi di completare localmente inferenze, verifiche, valutazioni di ricompensa e aggiornamenti dei pesi, formando un ciclo RL completo.
Nel sistema di Nous, Atropos verifica la catena di pensiero; DisTrO comprime le comunicazioni di addestramento; Psyche gestisce i cicli RL; World Sim fornisce ambienti complessi; Forge raccoglie ragionamenti reali; Hermes scrive tutto l'apprendimento nei pesi. L'apprendimento rinforzato non è solo una fase di addestramento, ma è il protocollo centrale che connette dati, ambienti, modelli e infrastrutture nell'architettura di Nous, rendendo Hermes un sistema vivente in grado di migliorarsi continuamente su una rete di calcolo open source.
Rete Gradient: architettura di apprendimento rinforzato Echo
La visione centrale della Gradient Network è ricostruire il paradigma di calcolo dell'AI attraverso un "stack di protocolli intelligenti aperti" (Open Intelligence Stack). Lo stack tecnologico di Gradient è composto da un insieme di protocolli chiave che possono evolversi indipendentemente e cooperare in modo eterogeneo. Il suo sistema include dalla comunicazione di base alla collaborazione intelligente a livelli superiori: Parallax (inferenza distribuita), Echo (addestramento decentralizzato RL), Lattica (rete P2P), SEDM / Massgen / Symphony / CUAHarm (memoria, collaborazione, sicurezza), VeriLLM (verifica affidabile), Mirage (simulazione ad alta fedeltà), formando insieme un'infrastruttura intelligente decentralizzata in continua evoluzione.

Echo - architettura di addestramento per l'apprendimento rinforzato
Echo è il framework di apprendimento rinforzato di Gradient, la sua idea centrale è decouplare i percorsi di addestramento, inferenza e dati (ricompensa) nell'apprendimento rinforzato, consentendo a generazione di rollout, ottimizzazione delle politiche e valutazione delle ricompense di espandersi e programmarsi in modo indipendente in ambienti eterogenei. Funziona in modo sinergico in una rete eterogenea composta da nodi di inferenza e addestramento, mantenendo la stabilità di addestramento in ambienti ampi e eterogenei attraverso meccanismi di sincronizzazione leggeri, alleviando efficacemente l'inefficienza di SPMD e i colli di bottiglia dell'utilizzo delle GPU causati dal miscelamento di inferenza e addestramento nei tradizionali DeepSpeed RLHF / VERL.
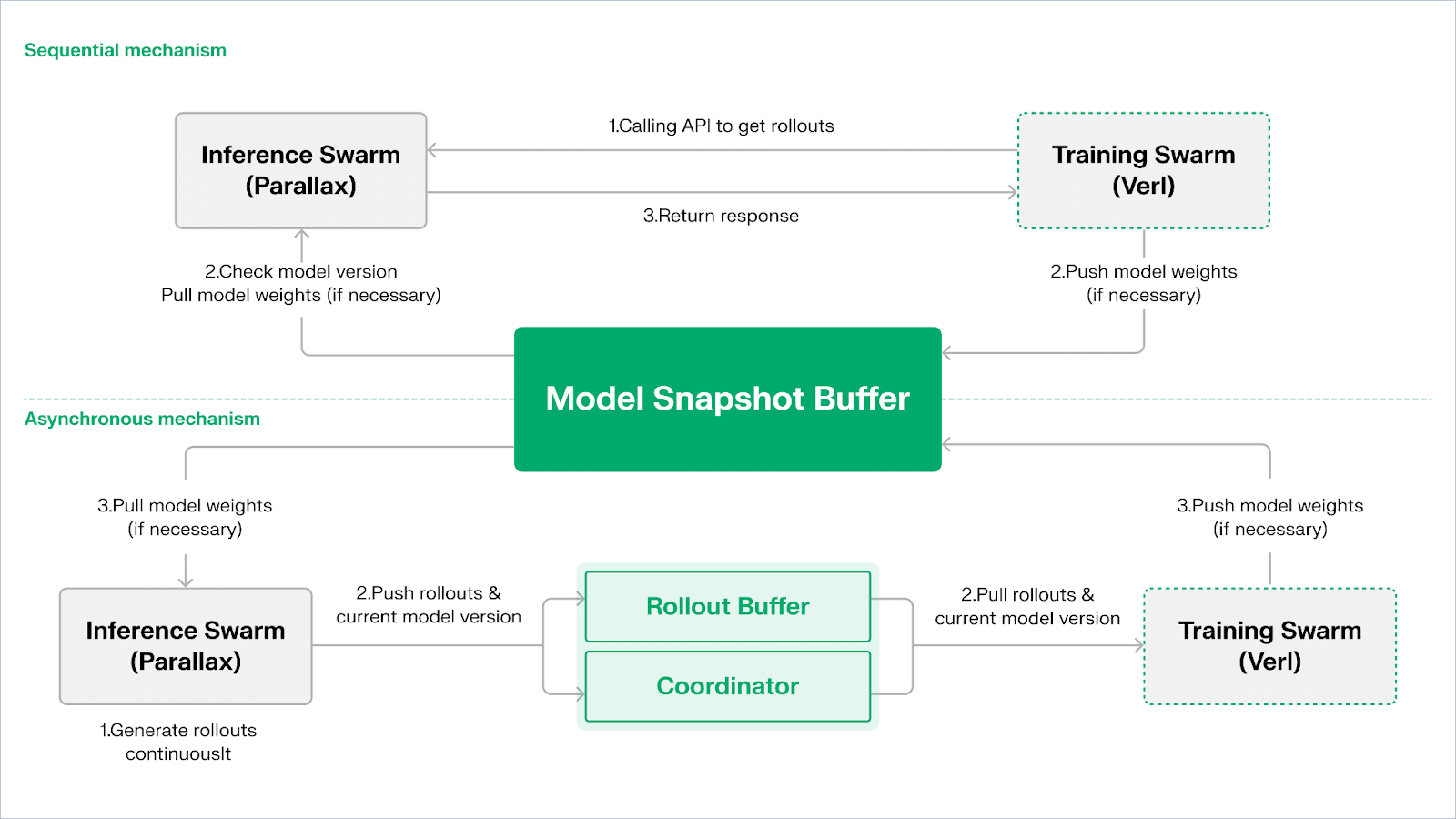
Echo adotta un'architettura a doppio sciame di "inferenza-allenamento" per massimizzare l'utilizzo della potenza di calcolo, con i due sciami che operano in modo indipendente, senza bloccarsi a vicenda:
Massimizzare il throughput dei campionamenti: lo sciame di inferenza (Inference Swarm) è composto da GPU di consumo e dispositivi edge, costruendo un campionatore ad alta capacità throughput attraverso Parallax in pipeline-parallel, focalizzandosi sulla generazione di traiettorie;
Massimizzare la potenza di calcolo dei gradienti: lo sciame di addestramento (Training Swarm) è costituito da una rete di GPU di consumo in grado di funzionare su cluster centralizzati o in diverse località globali, responsabile dell'aggiornamento dei gradienti, della sincronizzazione dei parametri e del fine-tuning di LoRA, focalizzandosi sul processo di apprendimento.
Per mantenere la coerenza tra politiche e dati, Echo fornisce protocolli di sincronizzazione leggeri di tipo sequenziale (Sequential) e asincrono (Asynchronous), realizzando una gestione bidirezionale della coerenza dei pesi delle politiche e delle traiettorie:
Modalità di estrazione sequenziale (Pull) | Priorità di precisione: il lato di addestramento costringe il nodo di inferenza a aggiornare la versione del modello prima di estrarre nuove traiettorie, assicurando così la freschezza delle traiettorie, adatta per compiti altamente sensibili alle strategie obsolete;
Modalità push-pull asincrona (Push–Pull) | Efficienza prioritaria: il lato di inferenza continua a generare traiettorie etichettate con versioni, il lato di addestramento consuma secondo il proprio ritmo, il coordinatore monitora le deviazioni di versione e attiva l'aggiornamento dei pesi, massimizzando l'utilizzo delle apparecchiature.
A livello di base, Echo è costruito su Parallax (inferenza eterogenea in ambienti a bassa larghezza di banda) e componenti di addestramento distribuiti leggeri (come VERL), facendo affidamento su LoRA per ridurre i costi di sincronizzazione tra nodi, in modo che l'apprendimento rinforzato possa funzionare stabilmente su reti eterogenee globali.
Grail: apprendimento rinforzato nell'ecosistema Bittensor
Bittensor ha costruito una vasta, sparsa e non stazionaria rete di funzioni di ricompensa attraverso il suo meccanismo di consenso unico Yuma.
Covenant AI nell'ecosistema Bittensor ha costruito una pipeline verticalmente integrata dal pre-addestramento al post-addestramento RL attraverso SN3 Templar, SN39 Basilica e SN81 Grail. In questo, SN3 Templar si occupa del pre-addestramento dei modelli di base, SN39 Basilica fornisce un mercato di calcolo distribuito, mentre SN81 Grail funge da "livello di inferenza verificabile" per il post-addestramento RL, completando l'ottimizzazione del ciclo chiuso dal modello di base alla strategia allineata.

L'obiettivo di GRAIL è dimostrare in modo crittografico la veridicità di ogni rollout di apprendimento rinforzato e legare l'identità del modello, garantendo che RLHF possa essere eseguito in modo sicuro in ambienti senza fiducia. Il protocollo stabilisce una catena di fiducia attraverso tre meccanismi:
Generazione di sfide deterministiche: utilizzando beacon casuali drand e hash di blocco per generare compiti imprevedibili ma riproducibili (come SAT, GSM8K), eliminando le frodi di pre-calcolo;
Attraverso il campionamento di indici PRF e impegni di sketch, i verificatori possono controllare a bassissimo costo il logprob a livello di token e la catena di inferenza, confermando che il rollout sia stato generato dal modello dichiarato.
Identità del modello: legare il processo di inferenza alle impronte strutturali dei pesi del modello e alla distribuzione del token, assicurando che la sostituzione del modello o la ripetizione dei risultati siano immediatamente riconosciute. Ciò fornisce una base di verità per le traiettorie di inferenza (rollout) nell'RL.
Su questa meccanica, la sottorete Grail ha realizzato un processo di post-addestramento verificabile in stile GRPO: i miner generano più percorsi inferenziali per lo stesso argomento, i verificatori valutano in base alla correttezza, alla qualità della catena inferenziale e al punteggio di soddisfacimento SAT, e scrivono i risultati normalizzati sulla catena, come pesi TAO. Esperimenti pubblici mostrano che questo framework ha aumentato la precisione MATH di Qwen2.5-1.5B dal 12.7% al 47.6%, dimostrando che può prevenire le frodi e migliorare significativamente le capacità del modello. Nel stack di addestramento di Covenant AI, Grail è la base di fiducia e esecuzione per RLVR/RLAIF decentralizzati e non è ancora stato ufficialmente lanciato sulla mainnet.
Fraction AI: apprendimento rinforzato basato sulla competizione RLFC
L'architettura di Fraction AI è chiaramente costruita attorno all'apprendimento rinforzato dalla competizione (Reinforcement Learning from Competition, RLFC) e all'annotazione dei dati gamificata, sostituendo le ricompense statiche e l'annotazione umana tradizionali con un ambiente competitivo aperto e dinamico. Gli agenti competono in diversi Spaces, la loro classifica relativa e il punteggio del giudice AI costituiscono insieme ricompense in tempo reale, trasformando il processo di allineamento in un sistema di gioco multi-agente online continuo.
Differenze fondamentali tra RLHF tradizionale e RLFC di Fraction AI:

Il valore centrale di RLFC è che le ricompense non provengono più da un singolo modello, ma da avversari e valutatori in continua evoluzione, evitando che il modello di ricompensa venga sfruttato e prevenendo l'ecologia dall'entrata in ottimizzazione locale attraverso la diversità delle politiche. La struttura di Spaces determina la natura del gioco (zero-sum o somma positiva), promuovendo l'emergere di comportamenti complessi attraverso antagonismo e collaborazione.
Nell'architettura di sistema, Fraction AI scompone il processo di addestramento in quattro componenti chiave:
Agenti: unità di strategia leggere basate su LLM open source, ampliate tramite QLoRA con pesi differenziali, aggiornamenti a basso costo;
Spazi: ambienti isolati di dominio compito, gli agenti pagano per entrare e ottengono ricompense in base a vincite o perdite;
Giudici AI: strato di ricompensa immediata costruito con RLAIF, offre valutazioni scalabili e decentralizzate;
Proof-of-Learning: lega l'aggiornamento delle politiche ai risultati competitivi specifici, garantendo che il processo di addestramento sia verificabile e anti-frode.
L'essenza di Fraction AI è costruire un motore evolutivo di collaborazione uomo-macchina. Gli utenti fungono da "meta-ottimizzatori" a livello di politica, guidando la direzione dell'esplorazione tramite ingegneria dei suggerimenti (Prompt Engineering) e configurazione dei superparametri; mentre gli agenti generano automaticamente enormi quantità di dati di preferenza di alta qualità (Preference Pairs) in competizione a livello micro. Questo modello consente all'annotazione dei dati di realizzare un ciclo commerciale attraverso il "fine-tuning senza fiducia" (Trustless Fine-tuning).
Confronto dell'architettura dei progetti di apprendimento rinforzato Web3

5. Riflessioni e prospettive: percorsi e opportunità di RL × Web3
Basato su un'analisi decomposta dei progetti all'avanguardia sopra menzionati, abbiamo osservato che, nonostante i diversi punti di ingresso (algoritmi, ingegneria o mercato) delle varie squadre, quando l'apprendimento rinforzato (RL) si combina con Web3, la logica della sua architettura sottostante converge in un paradigma altamente coerente di "decoupling-verifica-incentivi". Questo non è solo un caso tecnico, ma è anche il risultato inevitabile dell'adattamento delle proprietà uniche dell'apprendimento rinforzato alle reti decentralizzate.
Caratteristiche generali dell'architettura dell'apprendimento rinforzato: risolvere le limitazioni fisiche e di fiducia fondamentali
Separazione fisica di apprendimento e rollout (Decoupling of Rollouts & Learning) - topologia di calcolo predefinita
Rollout a bassa comunicazione e parallelo esternalizzato a GPU di consumo globali, l'aggiornamento dei parametri ad alta larghezza di banda è concentrato su pochi nodi di addestramento, così come da Prime Intellect con il suo attore-learner asincrono e l'architettura a doppio sciame di Gradient.
Livello di fiducia basato sulla verifica (Verification-Driven Trust) - infrastrutturalizzato
Nelle reti senza permessi, la verità computazionale deve essere garantita attraverso design matematici e meccanismi, con rappresentazioni che includono PoL di Gensyn, TOPLOC di Prime Intellect e la verifica crittografica di Grail.
Ciclo di incentivazione tokenizzato (Tokenized Incentive Loop) - auto-regolazione del mercato
L'offerta di calcolo, la generazione di dati, l'ordinamento della verifica e la distribuzione delle ricompense formano un ciclo chiuso, incentivando la partecipazione attraverso ricompense e sopprimendo le frodi attraverso Slash, mantenendo la rete stabile e in continua evoluzione in ambienti aperti.
Percorsi tecnologici differenziati: diversi "punti di rottura" sotto un'architettura coerente
Sebbene le architetture siano simili, ciascun progetto ha scelto diverse "mura tecnologiche" in base ai propri geni:
Gruppo di rottura algoritmica (Nous Research): cerca di risolvere i contrasti fondamentali dell'addestramento distribuito (collo di bottiglia di larghezza di banda) dalla base matematica. Il suo ottimizzatore DisTrO mira a comprimere il volume di comunicazione dei gradienti di migliaia di volte, con l'obiettivo di consentire anche alla banda larga domestica di eseguire l'addestramento di grandi modelli, un "colpo di dimensione" contro le limitazioni fisiche.
Gruppo di ingegneria dei sistemi (Prime Intellect, Gensyn, Gradient): si concentra sulla costruzione della prossima generazione di "sistemi di runtime AI". ShardCast di Prime Intellect e Parallax di Gradient sono progettati per spremere la massima efficienza dei cluster eterogenei nelle attuali condizioni di rete attraverso misure ingegneristiche estreme.
Gruppo di gioco di mercato (Bittensor, Fraction AI): si concentra sulla progettazione della funzione di ricompensa (Reward Function). Progettando meccanismi di punteggio sofisticati, guida i miner a cercare autonomamente le migliori strategie per accelerare l'emergere dell'intelligenza.
Vantaggi, sfide e prospettive future
Nel paradigma di integrazione dell'apprendimento rinforzato e Web3, i vantaggi a livello di sistema si riflettono innanzitutto nella riscrittura della struttura dei costi e di governance.
Ristrutturazione dei costi: la domanda di rollout nel post-addestramento RL è illimitata, Web3 può richiamare potenza di calcolo globale di lungo termine a costi estremamente bassi, un vantaggio di costo difficile da eguagliare per i fornitori di cloud centralizzati.
Allineamento sovrano (Sovereign Alignment): rompere il monopolio delle grandi aziende sui valori dell'AI (Alignment), le comunità possono decidere tramite votazione con token "quali sono le buone risposte", realizzando la democratizzazione della governance dell'AI.
Nel frattempo, questo sistema affronta anche due vincoli strutturali principali.
Bandwidth Wall: nonostante innovazioni come DisTrO, il ritardo fisico limita ancora l'addestramento completo di modelli a parametri enormi (70B+), e attualmente l'AI Web3 è più limitata a fine-tuning e inferenze.
Legge di Goodhart (Reward Hacking): in una rete altamente incentivata, i miner sono molto inclini a "overfittare" le regole di ricompensa (falsificare i punteggi) piuttosto che migliorare l'intelligenza reale. Progettare funzioni di ricompensa robuste anti-frode è un gioco eterno.
Attacco di nodo Byzantine malevolo (BYZANTINE worker): manipolando attivamente i segnali di addestramento e avvelenando, distruggono la convergenza del modello. Il punto chiave non è solo progettare continuamente funzioni di ricompensa anti-frode, ma costruire meccanismi dotati di robustezza antagonista.
L'integrazione dell'apprendimento rinforzato e Web3, in sostanza, sta riscrivendo i meccanismi di "come l'intelligenza viene prodotta, allineata e il valore viene distribuito". Il percorso di evoluzione può essere riassunto in tre direzioni complementari:
Rete di addestramento decentralizzata: da miner di calcolo a rete di politiche, esternalizzando i rollout paralleli e verificabili a GPU globali di lungo termine, focalizzandosi a breve termine sul mercato di inferenza verificabile, evolvendo a medio termine in sottoreti di apprendimento rinforzato raggruppate per compito;
Assetizzazione delle preferenze e delle ricompense: da lavoratori di annotazione a diritti sui dati. Realizzando l'assetizzazione delle preferenze e delle ricompense, collegando feedback di alta qualità e modelli di ricompensa in beni di dati governabili e distribuiti, aggiornando i "lavoratori di annotazione" in "diritti sui dati".
Evoluzione "piccola ma bella" in settori verticali: facendo nascere agenti RL specializzati e potenti in scenari verticali dove i risultati sono verificabili e i guadagni quantificabili, come esecuzione di strategie DeFi e generazione di codice, legando direttamente il miglioramento delle politiche e la cattura del valore, con possibilità di superare modelli chiusi generali.
In generale, la vera opportunità di RL × Web3 non risiede nella replica di una versione decentralizzata di OpenAI, ma nella riscrittura delle "relazioni di produzione intelligente": rendere l'esecuzione dell'addestramento un mercato di potenza di calcolo aperto, rendere le ricompense e le preferenze beni on-chain governabili, ridistribuendo il valore portato dall'intelligenza tra formatori, allineatori e utenti anziché concentrarlo sulla piattaforma.
Dichiarazione di non responsabilità: questo articolo è stato assistito da strumenti AI come ChatGPT-5 e Gemini 3 durante il processo di creazione, l'autore ha fatto del suo meglio per correggere e garantire l'accuratezza delle informazioni, ma non si possono evitare errori, grazie per la comprensione. Si segnala in particolare che nel mercato delle criptovalute esiste generalmente una discrepanza tra le fondamenta di progetto e le performance di prezzo nel mercato secondario. Il contenuto di questo articolo è destinato solo all'integrazione delle informazioni e alla comunicazione accademica/di ricerca, non costituisce alcun consiglio di investimento e non dovrebbe essere interpretato come raccomandazione per la compravendita di alcun token.