Autore: 0xjacobzhao | https://linktr.ee/0xjacobzhao
Questo rapporto di ricerca indipendente è supportato da IOSG Ventures. Il processo di ricerca e scrittura è stato ispirato dal lavoro di Sam Lehman (Pantera Capital) sul reinforcement learning. Grazie a Ben Fielding (Gensyn.ai), Gao Yuan (Gradient), Samuel Dare & Erfan Miahi (Covenant AI), Shashank Yadav (Fraction AI), Chao Wang per i loro preziosi suggerimenti su questo articolo. Questo articolo mira all'oggettività e all'accuratezza, ma alcune opinioni comportano un giudizio soggettivo e possono contenere pregiudizi. Apprezziamo la comprensione dei lettori.
L'intelligenza artificiale sta passando dall'apprendimento statistico basato su schemi verso sistemi di ragionamento strutturati, con l'addestramento post-allenamento—soprattutto l'apprendimento per rinforzo—che diventa centrale per la scalabilità delle capacità. DeepSeek-R1 segna un cambiamento di paradigma: l'apprendimento per rinforzo ora migliora dimostrabilmente la profondità del ragionamento e il processo decisionale complesso, evolvendo da un semplice strumento di allineamento a un percorso continuo di potenziamento dell'intelligenza.
In parallelo, Web3 sta trasformando la produzione di AI attraverso il calcolo decentralizzato e incentivi crittografici, la cui verificabilità e coordinazione si allineano naturalmente con le esigenze dell'apprendimento per rinforzo. Questo rapporto esamina i paradigmi di addestramento AI e i fondamenti dell'apprendimento per rinforzo, evidenzia i vantaggi strutturali di “Apprendimento per Rinforzo × Web3” e analizza Prime Intellect, Gensyn, Nous Research, Gradient, Grail e Fraction AI.
I. Tre Fasi di Addestramento AI
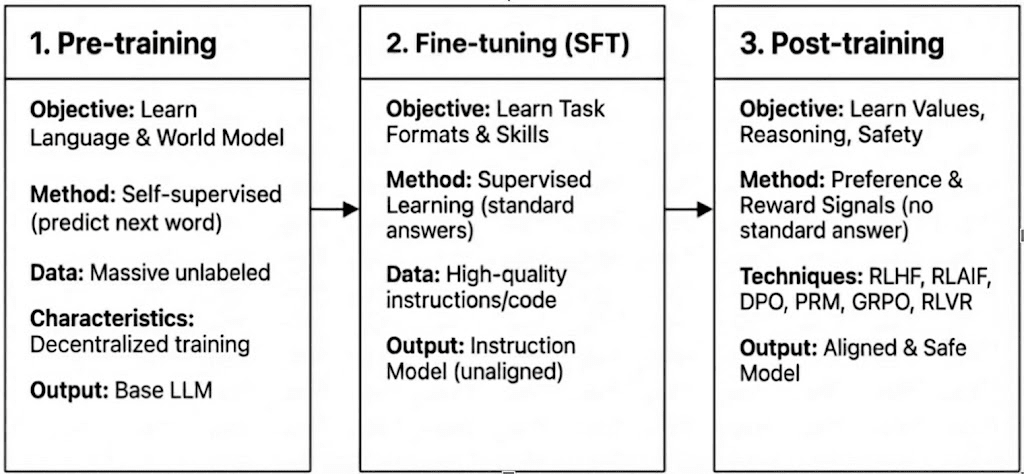
L'addestramento moderno degli LLM si suddivide in tre fasi—pre-addestramento, fine-tuning supervisionato (SFT) e post-addestramento/apprendimento per rinforzo—corrispondenti alla costruzione di un modello del mondo, all'iniezione di capacità di compito e alla formazione del ragionamento e dei valori. Le loro caratteristiche computazionali e di verifica determinano quanto siano compatibili con la decentralizzazione.
Pre-addestramento: stabilisce le fondamenta statistiche e multimodali principali attraverso un massiccio apprendimento auto-supervisionato, consumando l'80-95% del costo totale e richiedendo cluster GPU omogenei e ad alta larghezza di banda fortemente sincronizzati, rendendolo intrinsecamente centralizzato.
Fine-tuning Supervisionato (SFT): aggiunge capacità di compito e istruzione con set di dati più piccoli e costi inferiori (5-15%), utilizzando spesso metodi PEFT come LoRA o Q-LoRA, ma dipende ancora dalla sincronizzazione dei gradienti, limitando la decentralizzazione.
Post-addestramento: Il post-addestramento è composto da più fasi iterative che modellano la capacità di ragionamento di un modello, i valori e i confini di sicurezza. Include approcci basati su RL (ad es. RLHF, RLAIF, GRPO), ottimizzazione delle preferenze non-RL (ad es. DPO) e modelli di ricompensa di processo (PRM). Con requisiti di dati e costi inferiori (circa 5-10%), il calcolo si concentra su rollout e aggiornamenti della politica. Il suo supporto nativo per l'esecuzione distribuita e asincrona—spesso senza richiedere pesi di modello completi—rende il post-addestramento la fase meglio adatta per reti di addestramento decentralizzate basate su Web3 quando combinato con computazione verificabile e incentivi on-chain.
II. Paesaggio Tecnologico dell'Apprendimento per Rinforzo
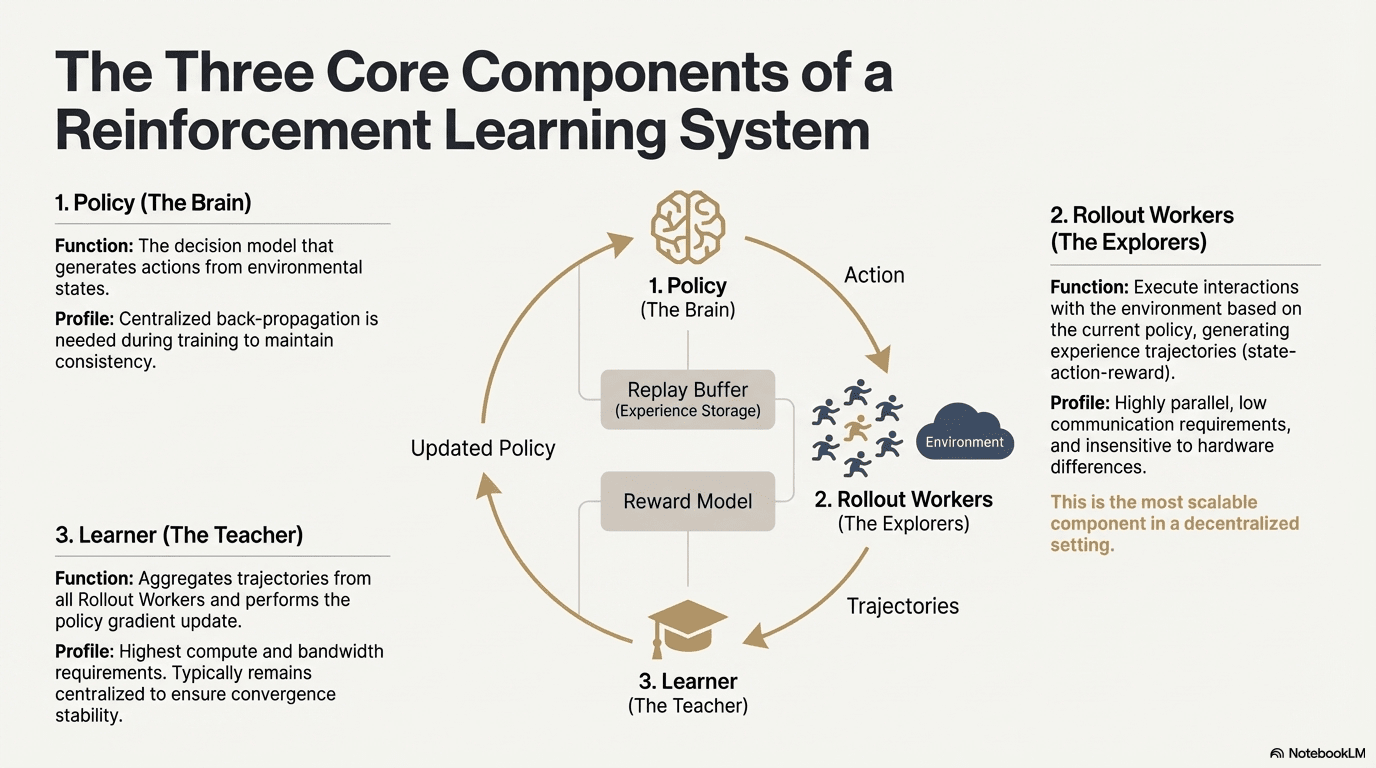
2.1 Architettura di Sistema dell'Apprendimento per Rinforzo
L'apprendimento per rinforzo consente ai modelli di migliorare la presa di decisioni attraverso un ciclo di feedback di interazione con l'ambiente, segnali di ricompensa e aggiornamenti della politica. Strutturalmente, un sistema RL è composto da tre componenti principali: la rete politica, il rollout per il campionamento dell'esperienza e il learner per l'ottimizzazione della politica. La politica genera traiettorie attraverso l'interazione con l'ambiente, mentre il learner aggiorna la politica in base alle ricompense, formando un processo di apprendimento iterativo continuo.
Rete Politica (Politica): Genera azioni dagli stati ambientali ed è il nucleo decisionale del sistema. Richiede retropropagazione centralizzata per mantenere la coerenza durante l'addestramento; durante l'inferenza, può essere distribuita a nodi diversi per operazione parallela.
Campionamento dell'Esperienza (Rollout): I nodi eseguono interazioni con l'ambiente in base alla politica, generando traiettorie stato-azione-ricompensa. Questo processo è altamente parallelo, ha comunicazione estremamente bassa, è insensibile alle differenze hardware, ed è il componente più adatto per l'espansione nella decentralizzazione.
Learner: Aggrega tutte le traiettorie di Rollout ed esegue aggiornamenti del gradiente della politica. È l'unico modulo con i requisiti più elevati di potenza di calcolo e larghezza di banda, quindi di solito è mantenuto centralizzato o leggermente centralizzato per garantire la stabilità della convergenza.
2.2 Quadro Fase dell'Apprendimento per Rinforzo
L'apprendimento per rinforzo può di solito essere diviso in cinque fasi, e il processo complessivo è il seguente:
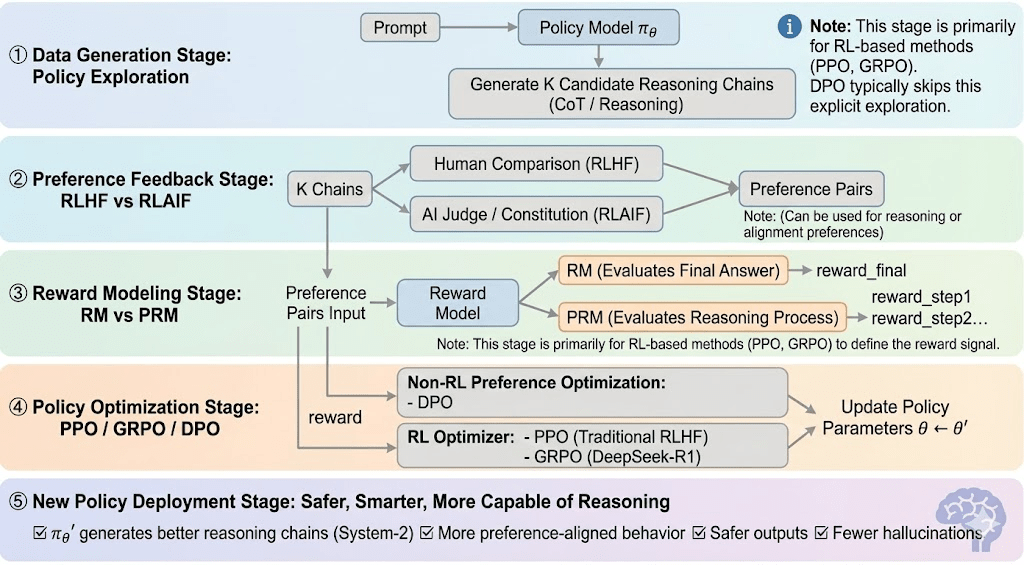
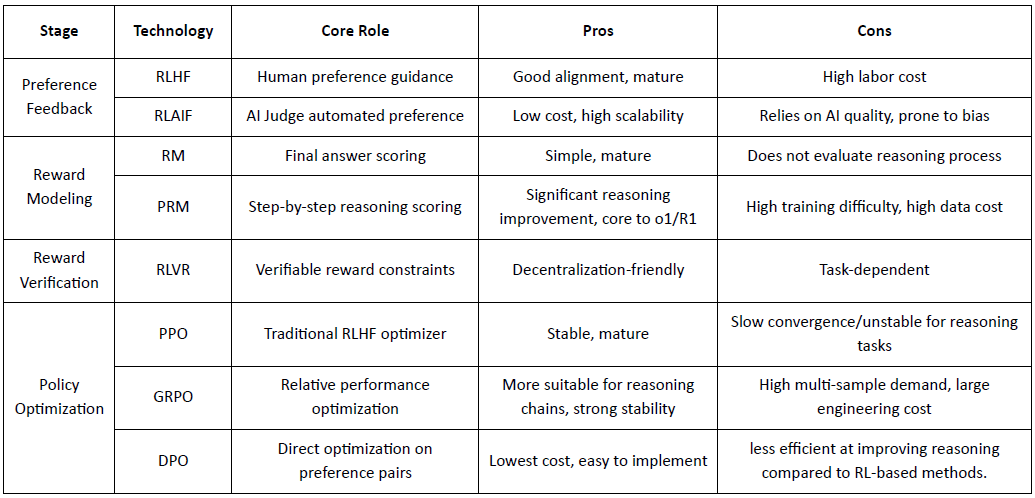
Fase di Generazione Dati (Esplorazione della Politica): Data un prompt, la politica campiona più catene di ragionamento o traiettorie, fornendo i candidati per la valutazione delle preferenze e la modellazione delle ricompense e definendo l'ambito dell'esplorazione della politica.
Fase di Feedback sulle Preferenze (RLHF / RLAIF):
RLHF (Apprendimento per Rinforzo da Feedback Umano): allena un modello di ricompensa dalle preferenze umane e poi utilizza RL (tipicamente PPO) per ottimizzare la politica in base a quel segnale di ricompensa.
RLAIF (Apprendimento per Rinforzo da Feedback AI): sostituisce gli esseri umani con giudici AI o regole costituzionali, riducendo i costi e scalando l'allineamento—ora l'approccio dominante per Anthropic, OpenAI e DeepSeek.
Fase di Modellazione della Ricompensa (Modellazione della Ricompensa): Impara a mappare gli output alle ricompense in base a coppie di preferenze. RM insegna al modello "qual è la risposta corretta," mentre PRM insegna al modello "come ragionare correttamente."
RM (Modello di Ricompensa): Usato per valutare la qualità della risposta finale, valutando solo l'output.
Process Reward Model (PRM): valuta il ragionamento passo dopo passo, addestrando efficacemente il processo di ragionamento del modello (ad es. in o1 e DeepSeek-R1).
Verifica della Ricompensa (RLVR / Verificabilità della Ricompensa): Uno strato di verifica della ricompensa vincola i segnali di ricompensa a essere derivati da regole riproducibili, fatti di verità assoluta o meccanismi di consenso. Questo riduce il hacking delle ricompense e il bias sistemico, e migliora l'auditabilità e la robustezza in ambienti di addestramento aperti e distribuiti.
Fase di Ottimizzazione della Politica (Ottimizzazione della Politica): Aggiorna i parametri della politica $\theta$ sotto la guida dei segnali forniti dal modello di ricompensa per ottenere una politica $\pi_{\theta'}$ con capacità di ragionamento più forti, maggiore sicurezza e modelli comportamentali più stabili. I metodi di ottimizzazione mainstream includono:
PPO (Ottimizzazione della Politica Prossimale): l'ottimizzatore RLHF standard, apprezzato per la stabilità ma limitato da una lenta convergenza nel ragionamento complesso.
GRPO (Ottimizzazione della Politica Relativa di Gruppo): introdotto da DeepSeek-R1, ottimizza le politiche utilizzando stime di vantaggio a livello di gruppo piuttosto che semplici classifiche, preservando l'ampiezza del valore e consentendo un'ottimizzazione della catena di ragionamento più stabile.
DPO (Ottimizzazione Diretta delle Preferenze): bypassa il RL ottimizzando direttamente su coppie di preferenze—economico e stabile per l'allineamento, ma inefficace nel migliorare il ragionamento.
Fase di Implementazione della Nuova Politica (Implementazione della Nuova Politica): il modello aggiornato mostra un ragionamento di Sistema-2 più forte, un migliore allineamento delle preferenze, meno allucinazioni e maggiore sicurezza, e continua a migliorare attraverso feedback iterativi.
2.3 Applicazioni Industriali dell'Apprendimento per Rinforzo
L'Apprendimento per Rinforzo (RL) è evoluto da una prima intelligenza di gioco a un framework centrale per il processo decisionale autonomo intersettoriale. I suoi scenari applicativi, basati sulla maturità tecnologica e sull'implementazione industriale, possono essere riassunti in cinque categorie principali:
Gioco & Strategia: La prima direzione in cui è stato verificato il RL. In ambienti con "informazioni perfette + ricompense chiare" come AlphaGo, AlphaZero, AlphaStar e OpenAI Five, il RL ha dimostrato un'intelligenza decisionale comparabile o superiore a quella degli esperti umani, ponendo le basi per gli algoritmi RL moderni.
Robotica & AI Incarnata: Attraverso il controllo continuo, la modellazione delle dinamiche e l'interazione ambientale, il RL consente ai robot di apprendere manipolazione, controllo del movimento e compiti cross-modali (ad es. RT-2, RT-X). Si sta rapidamente muovendo verso l'industrializzazione ed è una strada tecnica chiave per il dispiegamento di robot nel mondo reale.
Ragionamento Digitale / Sistema-2 LLM: RL + PRM guida modelli grandi da "imitazione del linguaggio" a "ragionamento strutturato." I risultati rappresentativi includono DeepSeek-R1, OpenAI o1/o3, Anthropic Claude e AlphaGeometry. Essenzialmente, esegue l'ottimizzazione della ricompensa a livello della catena di ragionamento piuttosto che limitarsi a valutare la risposta finale.
Scoperta Scientifica & Ottimizzazione Matematica: RL trova strutture o strategie ottimali in spazi di ricerca complessi, senza etichette e con ricompense enormi. Ha raggiunto importanti traguardi nei progetti AlphaTensor, AlphaDev e Fusion RL, mostrando capacità di esplorazione oltre l'intuizione umana.
Decisioni Economiche & Trading: RL è utilizzato per l'ottimizzazione delle strategie, controllo del rischio ad alta dimensione e generazione di sistemi di trading adattivi. Rispetto ai modelli quantitativi tradizionali, può apprendere continuamente in ambienti incerti ed è un componente importante della finanza intelligente.
III. Corrispondenza Naturale Tra Apprendimento per Rinforzo e Web3
L'apprendimento per rinforzo e Web3 sono naturalmente allineati come sistemi guidati da incentivi: il RL ottimizza il comportamento attraverso ricompense, mentre le blockchain coordinano i partecipanti attraverso incentivi economici. Le esigenze fondamentali del RL—rollout eterogenei su larga scala, distribuzione delle ricompense ed esecuzione verificabile—si mappano direttamente sui punti di forza strutturali di Web3.
Decoupling del Ragionamento e dell'Addestramento: L'apprendimento per rinforzo si separa in fasi di rollout e aggiornamento: i rollout sono pesanti in calcolo ma leggeri in comunicazione e possono funzionare in parallelo su GPU di consumo distribuite, mentre gli aggiornamenti richiedono risorse centralizzate ad alta larghezza di banda. Questo decoupling consente alle reti aperte di gestire i rollout con incentivi token, mentre gli aggiornamenti centralizzati mantengono la stabilità dell'addestramento.
Verificabilità: ZK (Zero-Knowledge) e Proof-of-Learning forniscono mezzi per verificare se i nodi hanno realmente eseguito il ragionamento, risolvendo il problema dell'onestà nelle reti aperte. In compiti deterministici come ragionamento su codice e matematica, i verificatori devono solo controllare la risposta per confermare il carico di lavoro, migliorando significativamente la credibilità dei sistemi RL decentralizzati.
Strato di Incentivo, Meccanismo di Produzione di Feedback Basato su Token Economy: Gli incentivi token di Web3 possono premiare direttamente i contributori di feedback RLHF/RLAIF, consentendo una generazione di preferenze trasparente e senza permesso, con staking e slashing che impongono la qualità in modo più efficiente rispetto al tradizionale crowdsourcing.
Potenziale per l'Apprendimento per Rinforzo Multi-Agente (MARL): Le blockchain formano ambienti multi-agente aperti e guidati da incentivi con stato pubblico, esecuzione verificabile e incentivi programmabili, rendendoli un banco di prova naturale per il MARL su larga scala nonostante il campo sia ancora agli inizi.
IV. Analisi dei Progetti Web3 + Apprendimento per Rinforzo
Basato sul quadro teorico sopra, analizzeremo brevemente i progetti più rappresentativi nell'ecosistema attuale:
Prime Intellect: Apprendimento per Rinforzo Asincrono prime-rl
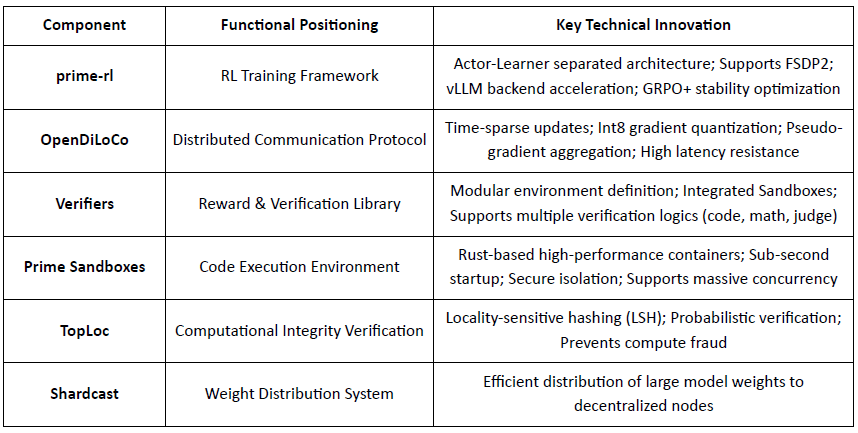
Prime Intellect mira a costruire un mercato globale di calcolo aperto e uno stack di superintelligenza open-source, che spazia da Prime Compute, alla famiglia di modelli INTELLECT, agli ambienti RL open, e motori di dati sintetici su larga scala. Il suo framework core prime-rl è progettato appositamente per RL decentralizzato asincrono, completato da OpenDiLoCo per un'istruzione efficiente in larghezza di banda e TopLoc per la verifica.
Panoramica dei Componenti dell'Infrastruttura Core di Prime Intellect
Pietra Angolare Tecnica: prime-rl Framework di Apprendimento per Rinforzo Asincrono
prime-rl è il motore di addestramento centrale di Prime Intellect, progettato per ambienti decentralizzati asincroni su larga scala. Raggiunge un'inferenza ad alto throughput e aggiornamenti stabili attraverso un completo disaccoppiamento Actor-Learner. Esecutori (Lavoratori Rollout) e Learners (Formatori) non bloccano sincronicamente. I nodi possono unirsi o lasciare in qualsiasi momento, avendo solo bisogno di estrarre continuamente l'ultima politica e caricare i dati generati.
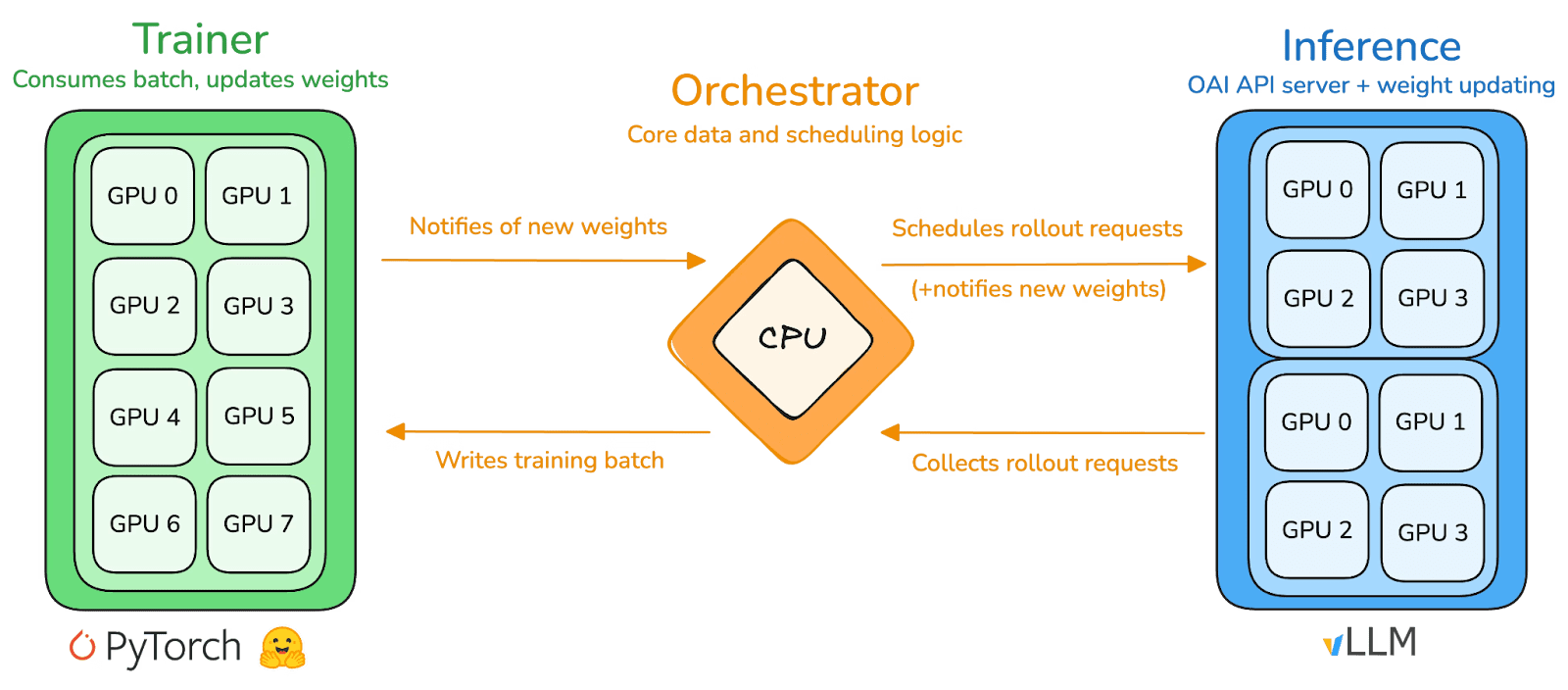
Attore (Lavoratori Rollout): Responsabile dell'inferenza del modello e della generazione di dati. Prime Intellect ha integrato in modo innovativo il motore di inferenza vLLM all'estremità dell'Attore. La tecnologia PagedAttention di vLLM e la capacità di Batch Continuo consentono agli Attori di generare traiettorie di inferenza con un throughput estremamente elevato.
Learner (Formatore): Responsabile per l'ottimizzazione della politica. Il Learner estrae dati in modo asincrono dal Buffer di Esperienza condiviso per aggiornamenti di gradiente senza attendere che tutti gli Attori completino il batch corrente.
Orchestratore: Responsabile della pianificazione dei pesi del modello e del flusso di dati.
Innovazioni Chiave di prime-rl:
Vera Asincronia: prime-rl abbandona il tradizionale paradigma sincrono di PPO, non aspetta nodi lenti e non richiede allineamento dei batch, consentendo a un numero qualsiasi e a prestazioni di GPU di accedere in qualsiasi momento, stabilendo la fattibilità del RL decentralizzato.
Integrazione Profonda di FSDP2 e MoE: Attraverso il partizionamento dei parametri FSDP2 e l'attivazione sparsa MoE, prime-rl consente modelli con decine di miliardi di parametri di essere addestrati in modo efficiente in ambienti distribuiti. Gli attori eseguono solo esperti attivi, riducendo significativamente i costi di VRAM e inferenza.
GRPO+ (Ottimizzazione della Politica Relativa di Gruppo): GRPO elimina la rete Critic, riducendo significativamente i costi di calcolo e l'overhead VRAM, adattandosi naturalmente a ambienti asincroni. il GRPO+ di prime-rl garantisce una convergenza affidabile in condizioni di alta latenza attraverso meccanismi di stabilizzazione.
Famiglia di Modelli INTELLECT: Un Simbolo della Maturità della Tecnologia RL Decentralizzata
INTELLECT-1 (10B, Ott 2024): Ha provato per la prima volta che OpenDiLoCo può allenarsi in modo efficiente in una rete eterogenea su tre continenti (condivisione della comunicazione < 2%, utilizzo del calcolo 98%), rompendo le percezioni fisiche dell'addestramento tra regioni.
INTELLECT-2 (32B, Apr 2025): Come primo modello RL senza permesso, convalida la capacità di convergenza stabile di prime-rl e GRPO+ in ambienti di latenza multi-step e asincroni, realizzando un RL decentralizzato con partecipazione globale al calcolo aperto.
INTELLECT-3 (106B MoE, Nov 2025): Adotta un'architettura sparsa che attiva solo 12B parametri, addestrato su 512×H200 e raggiungendo prestazioni di inferenza di punta (AIME 90.8%, GPQA 74.4%, MMLU-Pro 81.9%, ecc.). Le prestazioni complessive si avvicinano o superano i modelli closed-source centralizzati molto più grandi di esso.
Prime Intellect ha costruito un'intera stack RL decentralizzato: OpenDiLoCo riduce il traffico di addestramento tra regioni di ordini di grandezza mentre mantiene un utilizzo ~98% tra i continenti; TopLoc e i Verificatori garantiscono inferenze e dati di ricompensa affidabili tramite impronte di attivazione e verifica sandbox; e il motore di dati SYNTHETIC genera catene di ragionamento di alta qualità consentendo modelli grandi di funzionare in modo efficiente su GPU di consumo tramite parallelismo a pipeline. Insieme, questi componenti sottendono la generazione di dati scalabile, verifica e inferenza nel RL decentralizzato, con la serie INTELLECT che dimostra che tali sistemi possono offrire modelli di classe mondiale nella pratica.
Gensyn: Stack Core RL Swarm e SAPO
Gensyn cerca di unificare il calcolo globale inattivo in una rete di addestramento AI scalabile e senza fiducia, combinando esecuzione standardizzata, coordinazione P2P e verifica dei compiti on-chain. Attraverso meccanismi come RL Swarm, SAPO e SkipPipe, disaccoppia generazione, valutazione e aggiornamenti attraverso GPU eterogenee, fornendo non solo calcolo, ma intelligenza verificabile.
Applicazioni RL nello Stack Gensyn
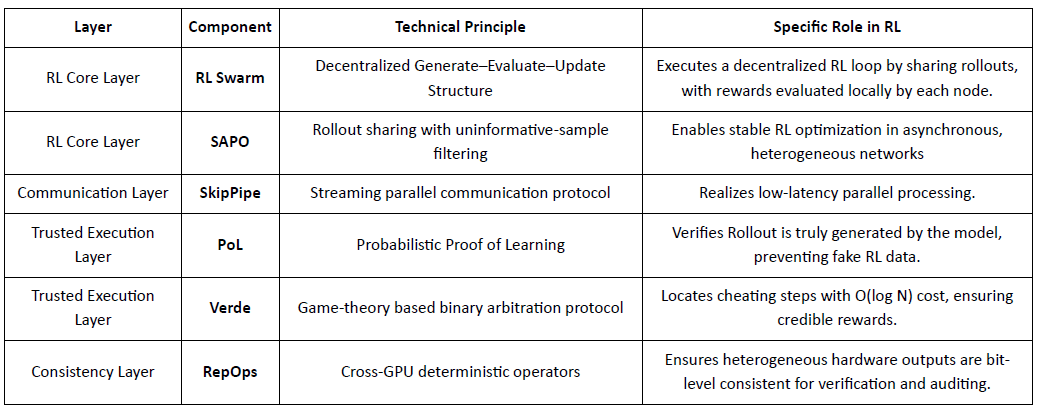
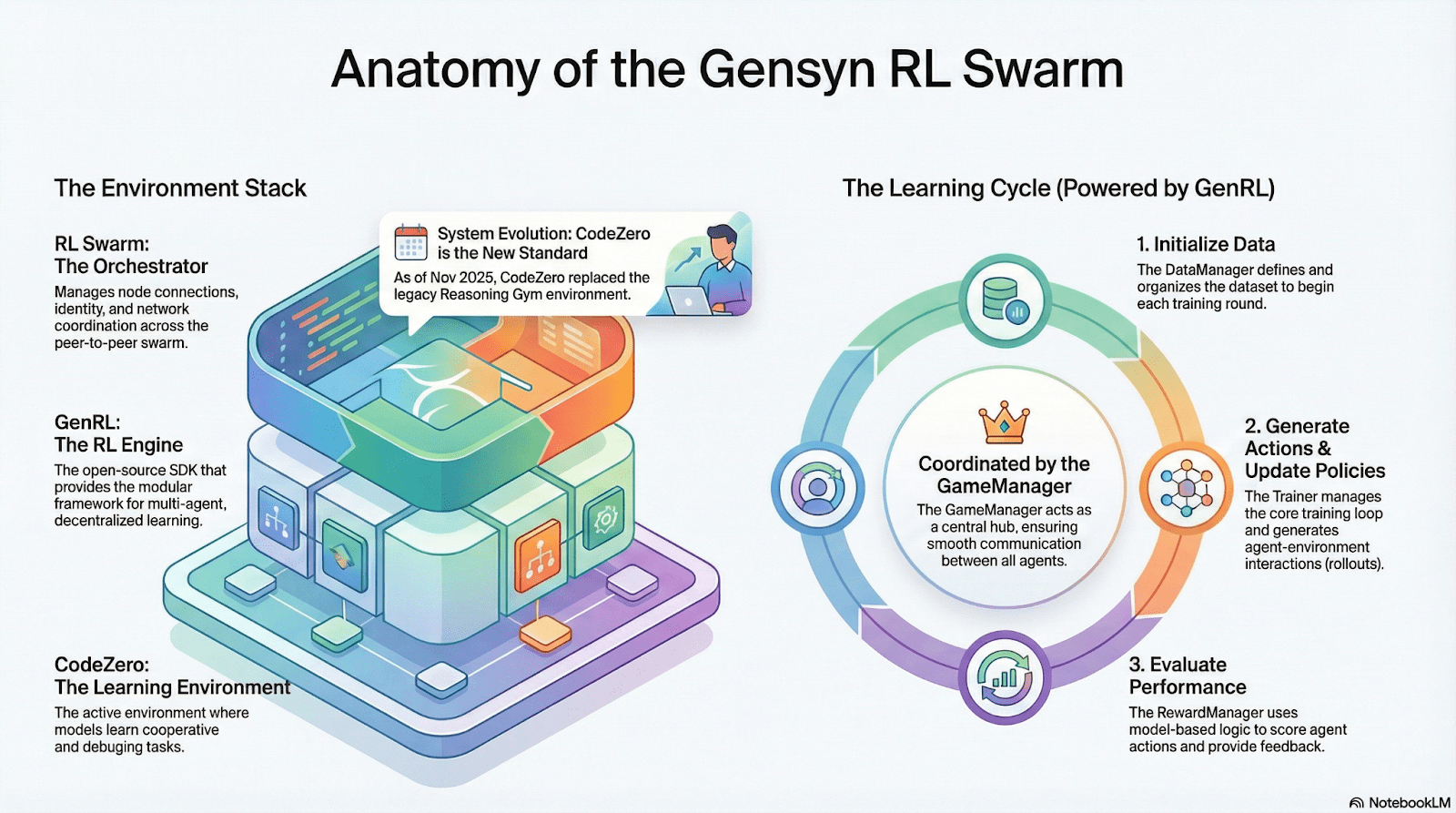
RL Swarm: Motore di Apprendimento per Rinforzo Collaborativo Decentralizzato
RL Swarm dimostra un modo di collaborazione completamente nuovo. Non è più semplice distribuzione di compiti, ma un ciclo infinito di un ciclo decentralizzato di generazione-valutazione-aggiornamento ispirato all'apprendimento collaborativo che simula l'apprendimento sociale umano:
Solutori (Esecutori): Responsabili dell'inferenza locale del modello e della generazione di Rollout, non ostacolati dall'eterogeneità dei nodi. Gensyn integra motori di inferenza ad alto throughput (come CodeZero) localmente per produrre traiettorie complete anziché solo risposte.
Propositori: Generano dinamicamente compiti (problemi matematici, domande di codice, ecc.), consentendo diversità di compiti e adattamento simile a un curriculum per adattare la difficoltà dell'addestramento alle capacità del modello.
Valutatori: Utilizzano "Modelli Giudice" congelati o regole per controllare la qualità dell'output, formando segnali di ricompensa locali valutati indipendentemente da ciascun nodo. Il processo di valutazione può essere auditato, riducendo il margine per la malizia.
I tre formano una struttura organizzativa RL P2P che può completare l'apprendimento collaborativo su larga scala senza pianificazione centralizzata.
SAPO: Algoritmo di Ottimizzazione della Politica Ricostruito per la Decentralizzazione
SAPO (Ottimizzazione della Politica di Campionamento dello Swarm) si concentra sulla condivisione dei rollout filtrando quelli senza segnale di gradiente, piuttosto che condividere i gradienti. Abilitando il campionamento decentralizzato su larga scala dei rollout e trattando i rollout ricevuti come generati localmente, SAPO mantiene una convergenza stabile in ambienti senza coordinamento centrale e con significativa eterogeneità della latenza dei nodi. Rispetto a PPO (che si basa su una rete critic che domina il costo computazionale) o GRPO (che si basa su stime di vantaggio a livello di gruppo piuttosto che su semplici classifiche), SAPO consente alle GPU di consumo di partecipare efficacemente all'ottimizzazione RL su larga scala con requisiti di larghezza di banda estremamente bassi.
Attraverso RL Swarm e SAPO, Gensyn dimostra che l'apprendimento per rinforzo—particolarmente RLVR post-allenamento—si adatta naturalmente ad architetture decentralizzate, poiché dipende maggiormente da esplorazioni diverse tramite rollout piuttosto che da sincronizzazione dei parametri ad alta frequenza. Combinato con PoL e sistemi di verifica Verde, Gensyn offre un percorso alternativo verso l'addestramento di modelli da trilioni di parametri: una rete di superintelligenza auto-evolutiva composta da milioni di GPU eterogenee in tutto il mondo.
Nous Research: Ambiente di Apprendimento per Rinforzo Atropos
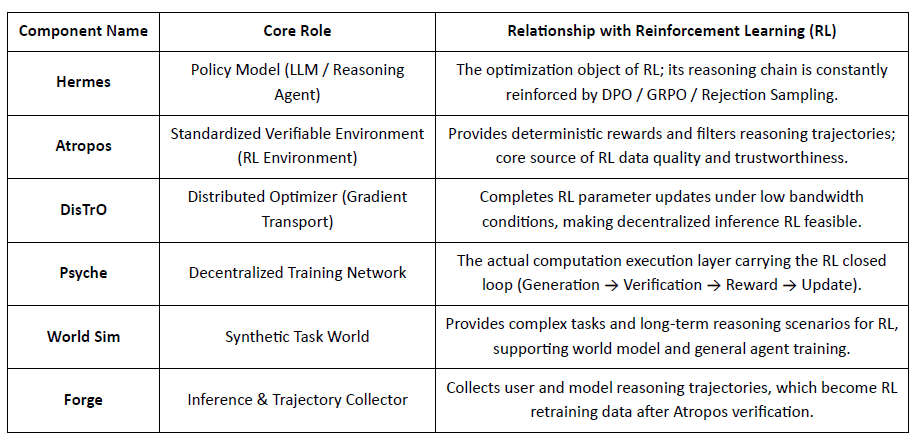
Nous Research sta costruendo uno stack cognitivo decentralizzato e auto-evolutivo, in cui componenti come Hermes, Atropos, DisTrO, Psyche e World Sim formano un sistema di intelligenza a ciclo chiuso. Utilizzando metodi RL come DPO, GRPO e campionamento di rifiuto, sostituisce le pipeline di addestramento lineari con feedback continuo attraverso generazione di dati, apprendimento e inferenza.
Panoramica dei Componenti della Ricerca Nous
Strato Modello: Hermes e l'Evoluzione delle Capacità di Ragionamento
La serie Hermes è l'interfaccia principale del modello di Nous Research rivolta agli utenti. La sua evoluzione dimostra chiaramente il percorso dell'industria che migra dall'allineamento tradizionale SFT/DPO al Ragionamento RL:
Hermes 1-3: Allineamento delle Istruzioni & Capacità Iniziali degli Agenti: Hermes 1-3 si basava su DPO a basso costo per un robusto allineamento delle istruzioni e sfruttava dati sintetici e l'introduzione per la prima volta dei meccanismi di verifica di Atropos in Hermes 3.
Hermes 4 / DeepHermes: Scrive il pensiero lento in stile Sistema-2 nei pesi tramite Chain-of-Thought, migliorando le prestazioni matematiche e di codice con Test-Time Scaling, e facendo affidamento su "Rejection Sampling + Atropos Verification" per costruire dati di ragionamento ad alta purezza.
DeepHermes adotta ulteriormente GRPO per sostituire PPO (che è difficile da implementare principalmente), consentendo al Ragionamento RL di funzionare sulla rete GPU decentralizzata Psyche, ponendo le basi ingegneristiche per la scalabilità del Ragionamento RL open-source.
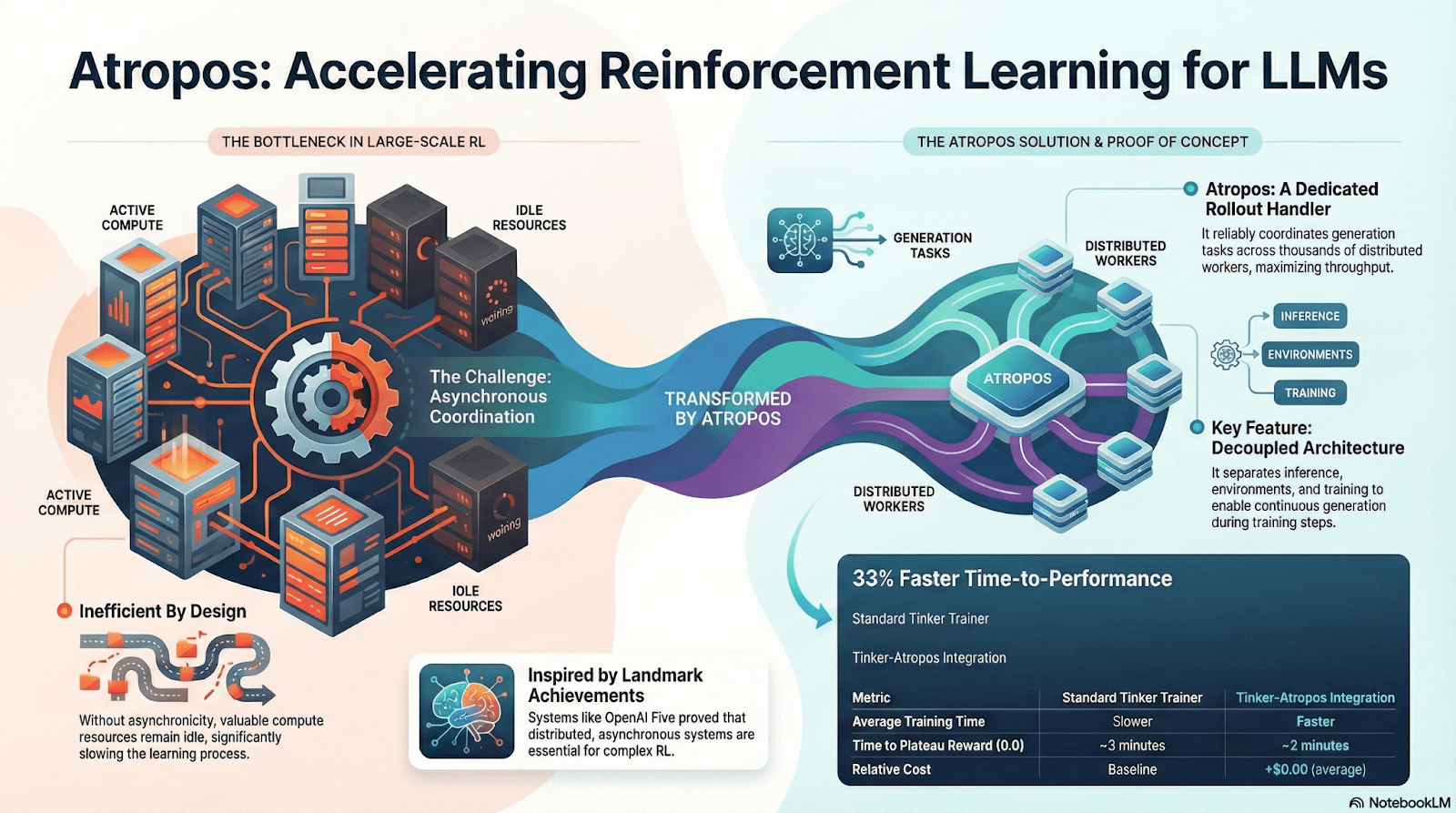
Atropos: Ambiente di Apprendimento per Rinforzo Verificabile e Guidato dalla Ricompensa
Atropos è il vero hub del sistema Nous RL. Incapsula prompt, chiamate agli strumenti, esecuzione del codice e interazioni multi-turno in un ambiente RL standardizzato, verificando direttamente se gli output sono corretti, fornendo così segnali di ricompensa deterministici per sostituire la costosa e non scalabile etichettatura umana. Più importante, nella rete di addestramento decentralizzata Psyche, Atropos funge da "giudice" per verificare se i nodi hanno effettivamente migliorato la politica, supportando prove auditabili di apprendimento, risolvendo fondamentalmente il problema della credibilità della ricompensa nel RL distribuito.
DisTrO e Psyche: Strato di Ottimizzatore per l'Apprendimento per Rinforzo Decentralizzato
L'addestramento RLF tradizionale (RLHF/RLAIF) si basa su cluster centralizzati ad alta larghezza di banda, una barriera centrale che l'open source non può replicare. DisTrO riduce i costi di comunicazione RL di ordini di grandezza attraverso il disaccoppiamento del momento e la compressione del gradiente, consentendo all'addestramento di funzionare sulla larghezza di banda di internet; Psyche distribuisce questo meccanismo di addestramento su una rete on-chain, consentendo ai nodi di completare inferenza, verifica, valutazione delle ricompense e aggiornamenti dei pesi localmente, formando un ciclo RL chiuso completo.
Nel sistema Nous, Atropos verifica le catene di pensiero; DisTrO comprime la comunicazione di addestramento; Psyche esegue il ciclo RL; World Sim fornisce ambienti complessi; Forge raccoglie il vero ragionamento; Hermes scrive tutto l'apprendimento nei pesi. L'apprendimento per rinforzo non è solo una fase di addestramento, ma il protocollo centrale che collega dati, ambiente, modelli e infrastruttura nell'architettura Nous, rendendo Hermes un sistema vivente capace di miglioramento continuo su una rete di calcolo aperta.
Rete Gradient: Architettura di Apprendimento per Rinforzo Echo
La rete Gradient mira a ricostruire il calcolo AI tramite uno Stack di Intelligenza Aperta: un insieme modulare di protocolli interoperabili che spaziano dalla comunicazione P2P (Lattica), inferenza distribuita (Parallax), formazione decentralizzata RL (Echo), verifica (VeriLLM), simulazione (Mirage) e coordinazione di memoria e agenti di livello superiore—formando insieme un'infrastruttura di intelligenza decentralizzata in evoluzione.
Echo — Architettura di Addestramento per Apprendimento per Rinforzo
Echo è il framework di apprendimento per rinforzo di Gradient. Il suo principio di design principale risiede nel disaccoppiare i percorsi di addestramento, inferenza e dati (ricompensa) nell'apprendimento per rinforzo, eseguendoli separatamente in Swarm di Inferenza eterogenea e Swarm di Addestramento, mantenendo un comportamento di ottimizzazione stabile attraverso ampi ambienti eterogenei con protocolli di sincronizzazione leggeri. Questo mitiga efficacemente i fallimenti SPMD e i colli di bottiglia dell'utilizzo delle GPU causati dalla miscelazione di inferenza e addestramento nel tradizionale RLHF / VERL di DeepSpeed.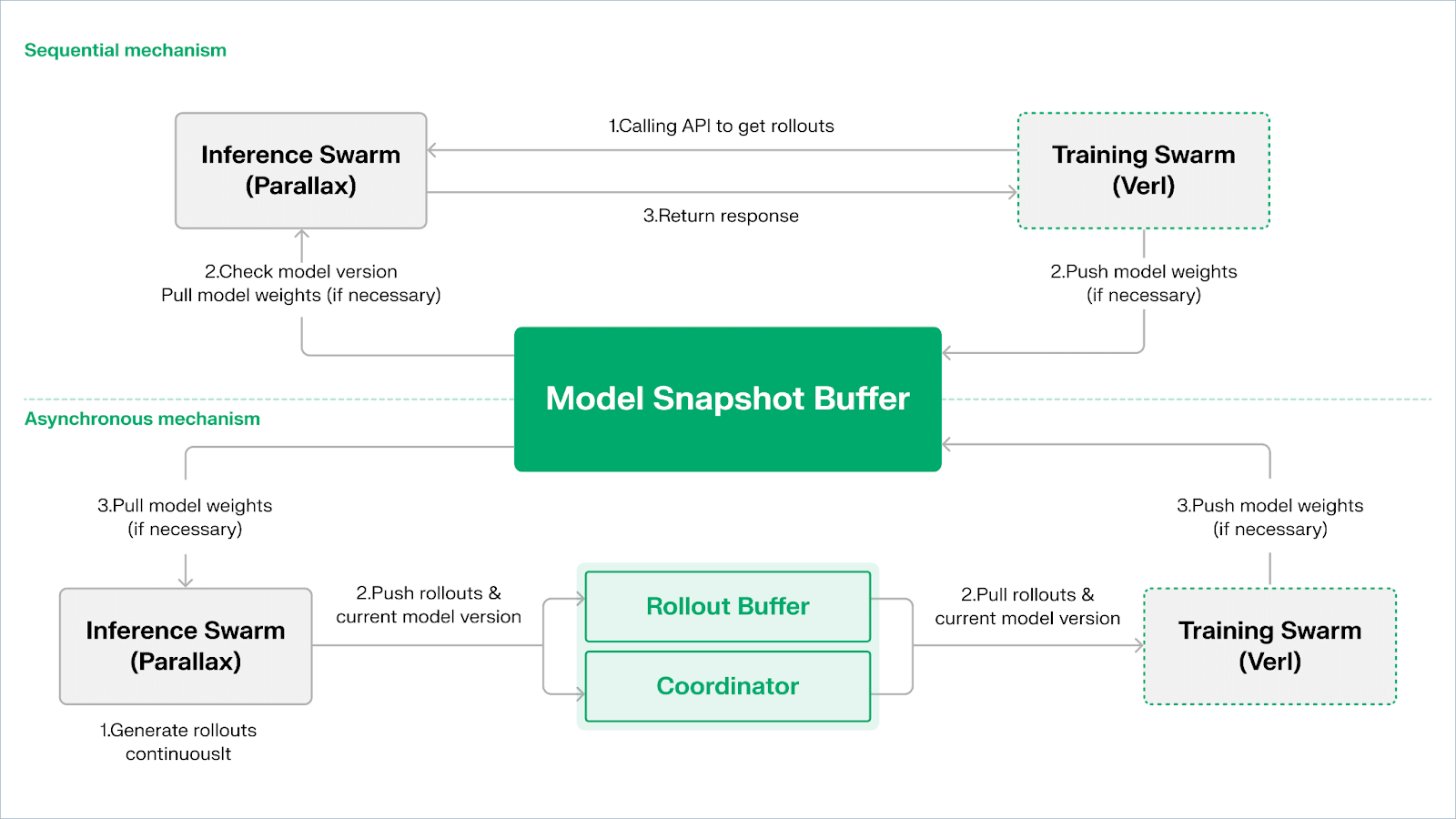
Echo utilizza un "Architettura Dual Swarm di Inferenza-Addestramento" per massimizzare l'utilizzo della potenza di calcolo. I due swarm funzionano indipendentemente senza bloccarsi a vicenda:
Massimizza il Throughput di Campionamento: Lo Swarm di Inferenza è composto da GPU di consumo e dispositivi edge, costruendo campionatori ad alto throughput tramite pipeline-parallelo con Parallax, focalizzandosi sulla generazione di traiettorie.
Massimizza la Potenza di Calcolo del Gradiente: Lo Swarm di Addestramento può funzionare su cluster centralizzati o reti globali di GPU di consumo, responsabile degli aggiornamenti del gradiente, sincronizzazione dei parametri e fine-tuning LoRA, focalizzandosi sul processo di apprendimento.
Per mantenere la coerenza della politica e dei dati, Echo fornisce due tipi di protocolli di sincronizzazione leggeri: Sequenziale e Asincrono, gestendo la coerenza bidirezionale dei pesi della politica e delle traiettorie:
Modalità di Estrazione Sequenziale (Precisione Prima): Il lato di addestramento costringe i nodi di inferenza a rinfrescare la versione del modello prima di estrarre nuove traiettorie per garantire la freschezza delle traiettorie, adatta per compiti altamente sensibili all'obsolescenza della politica.
Modalità Push-Pull Asincrona (Efficienza Prima): Il lato di inferenza genera continuamente traiettorie con tag di versione, e il lato di addestramento le consuma al proprio ritmo. Il coordinatore monitora la deviazione di versione e attiva aggiornamenti di peso, massimizzando l'utilizzo dei dispositivi.
Nello strato inferiore, Echo è costruito su Parallax (inferenza eterogenea in ambienti a bassa larghezza di banda) e componenti di addestramento distribuito leggeri (ad es. VERL), facendo affidamento su LoRA per ridurre i costi di sincronizzazione tra nodi, consentendo all'apprendimento per rinforzo di funzionare stabilmente su reti globali eterogenee.
Grail: Apprendimento per Rinforzo nell'Ecosistema Bittensor
Bittensor costruisce una rete di funzioni di ricompensa enorme, sparsa e non stazionaria attraverso il suo unico meccanismo di consenso Yuma.
Covenant AI nell'ecosistema Bittensor costruisce una pipeline verticalmente integrata dalla pre-istruzione all'addestramento post-RL attraverso SN3 Templar, SN39 Basilica e SN81 Grail. Tra essi, SN3 Templar è responsabile della pre-istruzione del modello di base, SN39 Basilica fornisce un mercato di potenza di calcolo distribuita e SN81 Grail funge da "strato di inferenza verificabile" per l'addestramento post-RL, portando i processi principali di RLHF / RLAIF e completando l'ottimizzazione a ciclo chiuso dal modello di base alla politica allineata.

GRAIL verifica crittograficamente i rollout RL e li lega all'identità del modello, consentendo un RLHF senza fiducia. Utilizza sfide deterministiche per prevenire la pre-computazione, campionamento a basso costo e impegni per verificare i rollout e il fingerprinting del modello per rilevare sostituzioni o replay, stabilendo autenticità end-to-end per le traiettorie di inferenza RL.
Il subnet di Grail implementa un ciclo di post-allenamento in stile GRPO verificabile: i minatori producono più percorsi di ragionamento, i validatori valutano la correttezza e la qualità del ragionamento, e i risultati normalizzati vengono scritti sulla catena. I test pubblici hanno aumentato l'accuratezza di Qwen2.5-1.5B MATH dal 12.7% al 47.6%, mostrando sia resistenza alle frodi che forti guadagni di capacità; in Covenant AI, Grail funge da nucleo di fiducia ed esecuzione per RLVR/RLAIF decentralizzati.
Fraction AI: Apprendimento per Rinforzo Basato sulla Competizione RLFC
Fraction AI riformula l'allineamento come Apprendimento per Rinforzo dalla Competizione, utilizzando etichettatura gamificata e contest tra agenti. Le classifiche relative e i punteggi degli giudici AI sostituiscono le etichette umane statiche, trasformando il RLHF in un gioco continuo e competitivo multi-agente.
Differenze Core Tra RLHF Tradizionale e RLFC di Fraction AI:
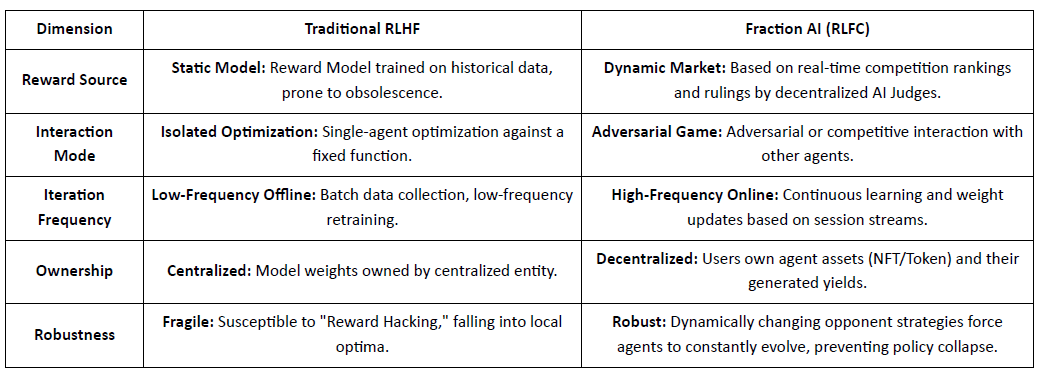
Il valore centrale di RLFC è che le ricompense provengono da avversari ed evaluatori in evoluzione, non da un singolo modello, riducendo il hacking delle ricompense e preservando la diversità della politica. La progettazione dello spazio modella la dinamica del gioco, abilitando comportamenti complessi competitivi e cooperativi.
Nell'architettura di sistema, Fraction AI smantella il processo di addestramento in quattro componenti chiave:
Agenti: Unità di politica leggere basate su LLM open-source, estese tramite QLoRA con pesi differenziali per aggiornamenti a basso costo.
Spazi: Ambienti di dominio di compiti isolati in cui gli agenti pagano per entrare e guadagnano ricompense vincendo.
Giudici AI: Strato di ricompensa immediata costruito con RLAIF, fornendo valutazione scalabile e decentralizzata.
Prova di Apprendimento: Lega gli aggiornamenti della politica a risultati di competizione specifici, garantendo che il processo di addestramento sia verificabile e a prova di frode.
Fraction AI funge da motore di co-evoluzione uomo-macchina: gli utenti agiscono come meta-ottimizzatori che guidano l'esplorazione, mentre gli agenti competono per generare dati di preferenza di alta qualità, consentendo un fine-tuning commercializzato e senza fiducia.
Confronto delle Architetture dei Progetti di Apprendimento per Rinforzo Web3
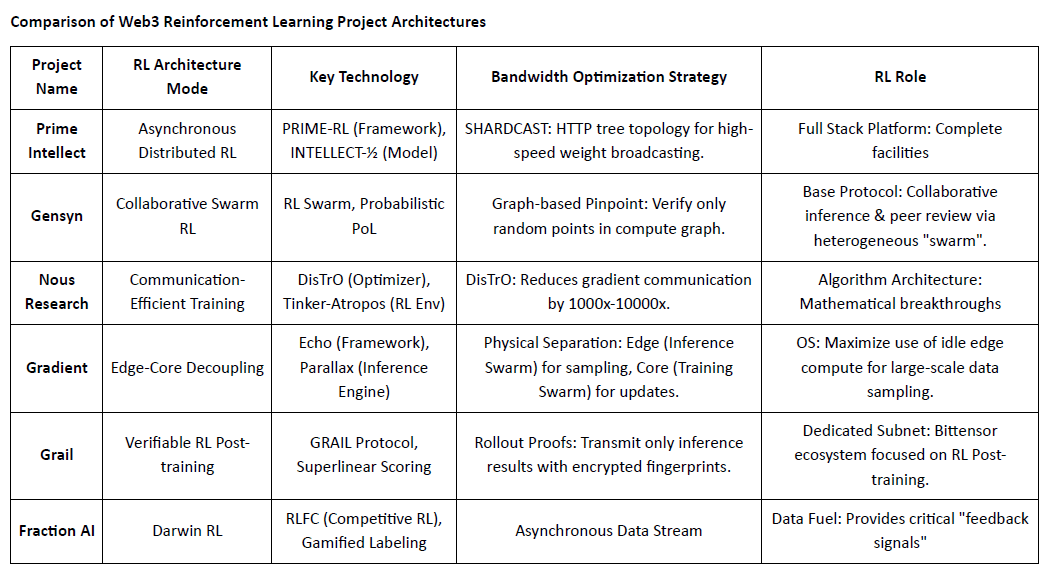
V. Il Percorso e l'Opportunità dell'Apprendimento per Rinforzo × Web3
Tra questi progetti avanguardistici, nonostante i punti di ingresso diversi, il RL combinato con Web3 converge costantemente su un'architettura condivisa “disaccoppiamento–verifica–incentivo”—un risultato inevitabile dell'adattamento dell'apprendimento per rinforzo a reti decentralizzate.
Caratteristiche Architettoniche Generali dell'Apprendimento per Rinforzo: Risolvere Limiti Fisici e Problemi di Fiducia
Decoupling dei Rollout & Apprendimento (Separazione Fisica di Inferenza/Apprendimento) — Topologia di Calcolo Predefinita: I Rollout scarsi nella comunicazione e parallelizzabili sono esternalizzati a GPU di consumo globali, mentre gli aggiornamenti dei parametri ad alta larghezza di banda sono concentrati in pochi nodi di addestramento. Questo è vero dal modello asincrono Actor-Learner di Prime Intellect all'architettura dual-swarm di Gradient Echo.
Fiducia Guidata dalla Verifica — Infrastrutturalizzazione: In reti senza permesso, l'autenticità computazionale deve essere garantita forzatamente attraverso matematica e design meccanico. Le implementazioni rappresentative includono il PoL di Gensyn, il TopLoc di Prime Intellect e la verifica crittografica di Grail.
Loop di Incentivo Tokenizzato — Autoregolazione del Mercato: L'offerta di calcolo, la generazione di dati, la classificazione della verifica e la distribuzione delle ricompense formano un ciclo chiuso. Le ricompense guidano la partecipazione, e il Slashing sopprime le frodi, mantenendo la rete stabile e in continua evoluzione in un ambiente aperto.
Percorsi Tecnici Differenziati: Diversi "Punti di Svolta" Sotto Architettura Coerente
Sebbene le architetture stiano convergendo, i progetti scelgono fossati tecnici diversi in base al loro DNA:
Scuola di Scoperta Scientifica (Nous Research): Affronta il collo di bottiglia della larghezza di banda dell'addestramento distribuito a livello di ottimizzatore—DisTrO comprime la comunicazione del gradiente di ordini di grandezza, mirato a consentire l'addestramento di modelli grandi su broadband domestico.
Scuola di Ingegneria dei Sistemi (Prime Intellect, Gensyn, Gradient): Si concentra sulla costruzione della prossima generazione di "Sistema di Runtime AI." ShardCast di Prime Intellect e Parallax di Gradient sono progettati per spremere la massima efficienza da cluster eterogenei nelle condizioni di rete esistenti attraverso mezzi ingegneristici estremi.
Scuola di Gioco di Mercato (Bittensor, Fraction AI): Si concentra sulla progettazione delle Funzioni di Ricompensa. Progettando meccanismi di punteggio sofisticati, guidano i minatori a trovare spontaneamente strategie ottimali per accelerare l'emergere dell'intelligenza.
Vantaggi, Sfide e Prospettive Finali
Sotto il paradigma dell'Apprendimento per Rinforzo combinato con Web3, i vantaggi a livello di sistema si riflettono prima nella riscrittura delle strutture dei costi e delle strutture di governance.
Ristrutturazione dei Costi: L'addestramento post-RL ha una domanda illimitata di campionamento (Rollout). Web3 può mobilitare potenza di calcolo globale a lungo termine a costi estremamente bassi, un vantaggio di costo difficile da eguagliare per i fornitori di cloud centralizzati.
Allineamento Sovrano: Rompere il monopolio delle grandi tecnologie sui valori dell'AI (Allineamento). La comunità può decidere "qual è una buona risposta" per il modello attraverso il voto con token, realizzando la democratizzazione della governance dell'AI.
Allo stesso tempo, questo sistema affronta due vincoli strutturali:
Wall di Larghezza di Banda: Nonostante innovazioni come DisTrO, la latenza fisica limita ancora l'addestramento completo di modelli a parametri ultra-grandi (70B+). Attualmente, l'AI Web3 è più limitata all'affinamento e all'inferenza.
Manipolazione della Ricompensa (Legge di Goodhart): In reti altamente incentivanti, i minatori sono estremamente inclini a "overfitting" delle regole di ricompensa (manipolando il sistema) piuttosto che a migliorare la vera intelligenza. Progettare funzioni di ricompensa robuste a prova di frode è un gioco eterno.
Lavoratori Byzantine Maligni: si riferiscono alla manipolazione e avvelenamento deliberati dei segnali di addestramento per interrompere la convergenza del modello. La sfida principale non è la continua progettazione di funzioni di ricompensa a prova di frode, ma meccanismi con robustezza avversariale.
RL e Web3 stanno rimodellando l'intelligenza tramite reti di rollout decentralizzate, feedback assetizzati on-chain e agenti RL verticali con cattura del valore diretto. La vera opportunità non è un OpenAI decentralizzato, ma nuove relazioni nella produzione di intelligenza—mercati di calcolo aperti, ricompense e preferenze governabili e valore condiviso tra formatori, allineatori e utenti.
Dichiarazione di Non Responsabilità: Questo articolo è stato completato con l'assistenza degli strumenti AI ChatGPT-5 e Gemini 3. L'autore ha fatto ogni sforzo per correggere e garantire l'autenticità e l'accuratezza delle informazioni, ma potrebbero ancora esistere omissioni. Si prega di comprendere. Va notato in particolare che il mercato degli asset crittografici spesso esperimenta divergenze tra i fondamenti del progetto e le prestazioni del prezzo nel mercato secondario. Il contenuto di questo articolo è per integrazione informativa e scambio accademico/di ricerca solo e non costituisce alcun consiglio di investimento, né deve essere considerato una raccomandazione per acquistare o vendere alcun token.