
@Walrus 🦭/acc Decentralized storage has always felt like an easy win: spread your data out, and suddenly it’s tougher to knock offline, harder to censor, and not dependent on one fragile ‘main’ server. Then the network gets noisy. Nodes go offline, links get congested, and latency stops looking like a nuisance and starts looking like a loophole. The uncomfortable question becomes very plain, very fast: how do you know a storage node still holds what it’s paid to hold, especially when “no response” could mean “I’m slow” or “I’m faking it”?
Walrus sits right on that fault line. It’s designed as a decentralized blob storage system, and it treats verification under messy network conditions as a first-class requirement rather than a footnote. The project’s public mainnet launch in March 2025 also matters because designs stop being theory once real users and real incentives show up. When a protocol is live, “edge cases” stop being edges.
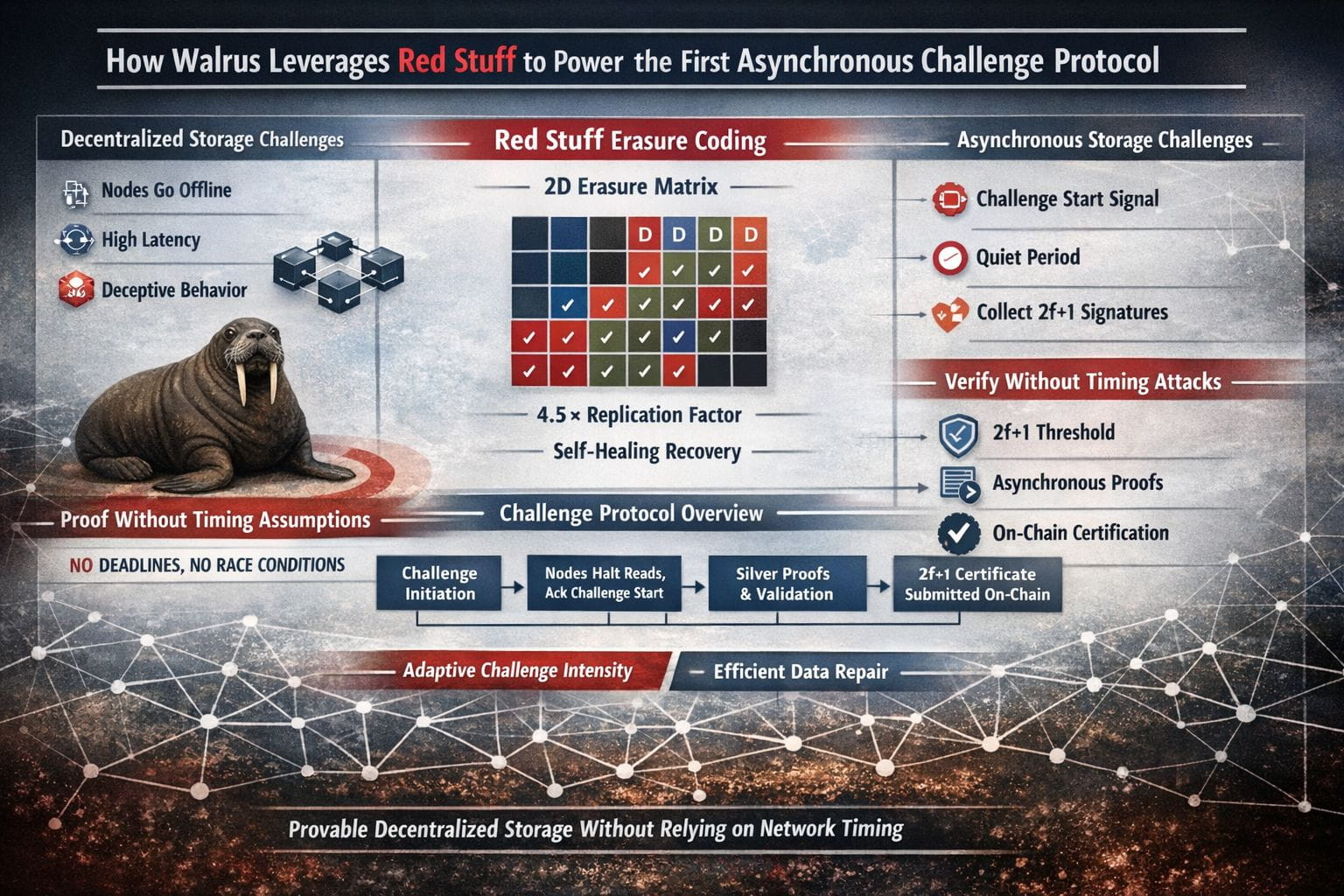
The core technical move in Walrus is Red Stuff (often written RedStuff), a two-dimensional erasure-coding scheme that changes how redundancy is paid for. Rather than making many full copies of a blob, Red Stuff breaks data into smaller pieces (“slivers”) and adds coded pieces so the original can be reconstructed even when a large portion of nodes are missing. The Walrus authors emphasize that this approach targets strong security with roughly a 4.5× replication factor and “self-healing” recovery where repair bandwidth is proportional to the data actually lost, not the entire blob. That last point sounds like an optimization until you think about long-running networks. Churn is normal, not exceptional, and repair costs compound. A design that assumes constant re-downloads quietly taxes everyone forever.
What’s easy to miss is that Red Stuff isn’t presented as a storage trick. It’s the enabling layer for Walrus’ headline claim: a storage challenge mechanism that does not depend on timing assumptions. The paper states, bluntly, that it presents “the first storage proof protocol to make no assumptions about network synchrony,” and that it leans on Red Stuff’s ability to reconstruct blobs with a 2f+1 threshold. In other words, Walrus tries to avoid the usual trap where “proof” is really “couldn’t fetch missing data fast enough before the deadline.”
That trap is more serious than it sounds. In a world where networks can be delayed on purpose, deadlines become a game. A node that isn’t storing everything might try to look honest by pulling missing pieces from others when challenged, and if the protocol can’t distinguish delay from deception, it ends up rewarding the wrong behavior. This is where the two-dimensional layout does something clever without being flashy: it allows different thresholds in different directions. The arXiv version describes that this property is only possible because 2D encoding allows different encoding thresholds per dimension, which is what lets it work in a network where “when” isn’t reliable.
Walrus’ “fully asynchronous” challenge flow is intentionally direct. Near the end of each epoch, storage nodes observe a “challenge start” event on-chain (the paper gives a concrete example: a specific block height). At that moment they stop serving read and recovery requests and broadcast an acknowledgment; once 2f+1 honest nodes have entered the challenge phase, challenges begin. Challenged nodes send required symbols (with proofs tied to the writer’s commitment), other nodes verify and sign confirmations, and collecting 2f+1 signatures yields a certificate that gets submitted on-chain. Reads and recovery resume after enough valid certificates arrive.
That temporary “quiet period” is the part that feels almost unfashionable—because it’s not trying to be cute about adversaries. The paper explains why it matters: since 2f+1 nodes have entered the challenge phase, at least f+1 honest nodes won’t respond after challenged files are determined, which blocks an attacker from assembling enough symbols and signatures to pass if they didn’t actually store the assigned slivers. It’s not a marketing-friendly idea to say “we pause reads,” but it’s honest engineering. If you allow the network to keep serving everything while also trying to run strict proofs, you may accidentally build a vending machine for attackers: request what you’re missing, then claim you had it all along.
Walrus also sketches a lighter-weight variant meant to reduce the blunt cost of full challenges. The same section describes setting up a “random coin” with a 2f+1 reconstruction threshold, using it to seed a pseudo-random function that selects which blobs are challenged for each storage node, so most blobs can remain directly readable. There’s a nice bit of pragmatism here: if reads start failing even while nodes pass challenges, that’s a signal that the challenge set is too small, and the system can increase challenge intensity up to re-enabling the full protocol. It treats verification as something you tune based on observed reality, not a one-time parameter decision you pretend is timeless.
This is why the title’s claim holds together. Walrus doesn’t just “use” Red Stuff; it depends on it. The encoding scheme isn’t an isolated efficiency gain—it’s the reason the verification story can be framed around thresholds and reconstruction rather than deadlines and hope. And that’s also why people are paying attention now: decentralized apps are moving more media, more training data, more long-lived artifacts off-chain, and the cost of pretending storage is “probably fine” keeps rising. Walrus is betting that storage should be provable even when the network behaves badly. That bet isn’t guaranteed to win. But it’s grounded, and it’s the kind of design choice that tends to matter long after launch announcements fade.

