晚上好啊,各位。阿祖觉得2026 年还在聊“哪条存储链更便宜”的,其实已经有点跑题了。AI 真正在卷的,不是谁硬盘打折打得狠,而是谁能把数据这件事变成一套完整的市场基础设施——能定价、能治理、能验真、还能被智能体直接拿来用。
Walrus 就是我最近在研究的一条“被很多人误解”的协议。很多人第一眼看到它,“哦,又一条去中心化存储,可能是 Sui 版 Arweave 吧?”但你去打开官网和 Docs,项目方自己写得非常直接:Walrus 是一个专为 AI 时代数据市场设计的去中心化存储协议,要让数据变得可靠、可定价、可治理,而不是单纯帮你便宜地堆文件。
为什么要这么强调“数据市场”?因为在 AI 叙事下,算力已经能在各大云厂商和专用芯片里卷个你死我活,真正被严重低估的是高质量数据本身。大模型要持续迭代,需要的是可验证来源、可追溯授权、可清算分润的数据流,而不是一堆不知道版权归属、风控风险的“野数据”。你把这个问题想明白了,就能理解 Walrus 为什么一上来就把自己定位成“为 AI 时代数据市场服务的底层协议”。
所以我更愿意把 Walrus 理解成“可编程数据底座”,而不是“便宜存储盘”。这也是它和传统存储项目最大的分野:它不是帮你在某条链上塞个文件哈希了事,而是把每一个存进去的大文件(blob),在 Sui 上变成一个可以被 Move 智能合约直接操作的对象。换句话说,你在 Walrus 上存的不是“死文件”,而是可以被合约管理生命周期、计费、授权、拆分组合的“数据资产”。
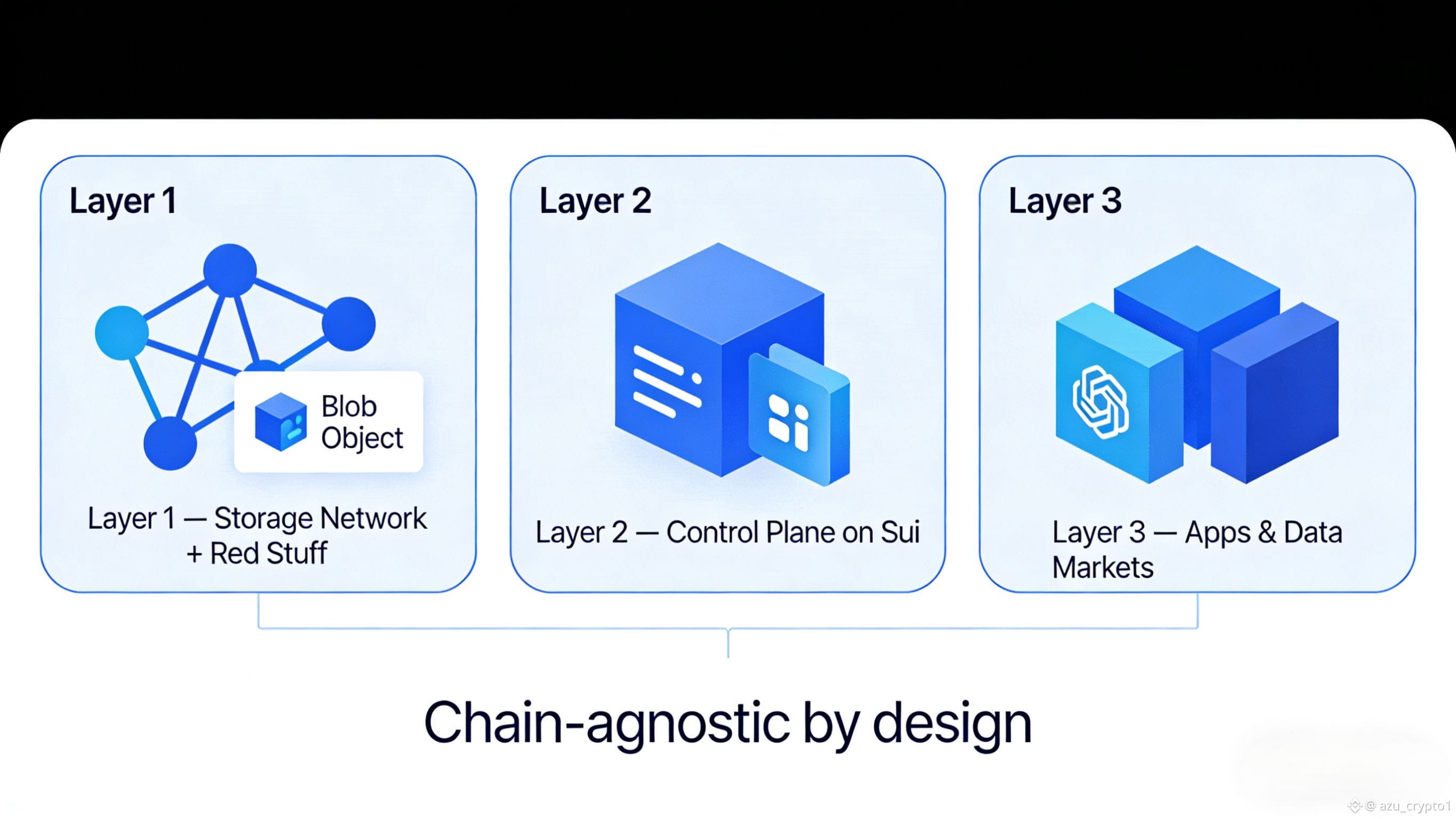
具体怎么做到的?可以简单粗暴地把 Walrus 想成三层。
最底下一层,是那套分布式存储节点网络和 Red Stuff 编码机制,负责把你的大文件切成碎片、在节点之间分发、冗余备份、容错恢复。这一层更偏密码学和分布式系统工程,白皮书里写得非常硬核,我们留到后面的系列再拆。
中间这一层,是整套“可编程”的关键:Walrus 用 Sui 做控制平面,把每一个 blob 映射成 Sui 上的一个资源对象,存放它的元数据、存储期限、所有权、访问策略等。Move 合约可以像操作普通链上资产一样,去控制这些 blob:谁能读、什么时候过期、要不要续费、读写要不要收费,甚至可以构造更复杂的逻辑,比如按使用次数结算收入、按访问频率动态调价等等。
最上面这一层,才是普通用户真正感知到的地方:AI 数据市场、内容平台、身份协议、DeFi 应用……它们把 Walrus 提供的数据能力,当成一个“链下大文件 + 链上规则”的组合来消费。官方在 Binance Square 里也反复强调:Walrus 是基于 Sui 的去中心化数据可用性和存储协议,允许应用通过 Move 合约发布、读取、编程操作大体量二进制文件,让存储本身变成一个可交互的资源,而不是冷冰冰的仓库。
这里还有一个经常被忽略的点:Walrus 虽然用 Sui 做控制层,但它从第一天就设计成“chain-agnostic”。什么意思?简单说,就是只要你那条链上的应用愿意和 Walrus 的 SDK、工具链打交道,不管是 EVM、Solana 还是别的什么,都可以把 Walrus 当成自己的数据层,业务逻辑留在原生态,存储和数据管理丢给 Walrus。这一点在官方文档和生态介绍里写得很清楚:协调在 Sui 上做,但服务的对象是整个多链世界。
说完架构,咱们回到一个更接地气的问题:这个“可编程数据底座”,到底能被拿来干什么?先举三个我觉得最典型的场景。
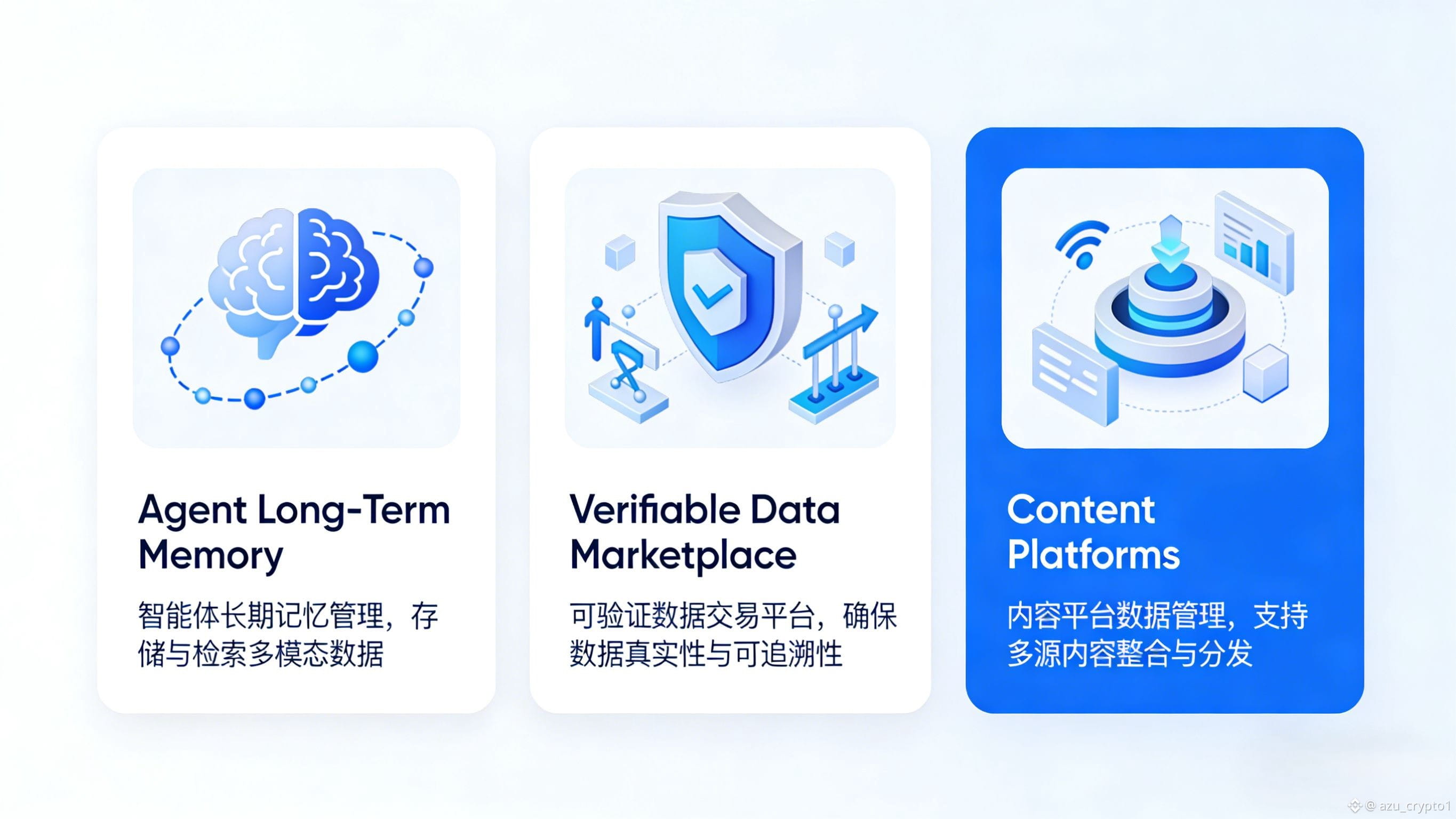
第一个是 AI agent 的“长时记忆”。现在大家用各种智能体,最大痛点之一就是“每次见面都要从头讲故事”:上下文记不了太久,换一个模型、换一个平台,之前的交互和数据基本是断档的。如果你用 Walrus 这套组合,你可以把 agent 的结构化记忆(分析结果、总结后的用户画像、偏好向量等)以及必要的原始片段,以 blob 的形式丢到 Walrus,然后在 Sui 上用 Move 合约维护一张“谁可以访问这些记忆、在什么条件下可以读写”的表。AI agent 自己可以通过合约接口调这些数据,不同 agent 之间也能够在明确授权和付费的前提下共享记忆,这就把“AI 的记忆层”从应用里拆出来,变成一个独立运作的数据资产层。
第二个则是数据市场本身。我们经常听到“要建立开放数据市场”,但真到了落地层面,问题特别多:谁在出售什么数据、有没有合法授权、买家到底拿到了什么版本、后续如果数据更新怎么处理、收益如何自动分配?Walrus 给出的思路是,把数据集本身作为 blob 存起来,把权限、计费、收益分配写进 Move 智能合约。数据提供方可以发行针对某个 blob 的访问凭证 NFT 或访问权 token,买家通过这些凭证调用 Walrus 节点访问真实数据,所有的“谁访问了、付了多少钱、这些钱怎么按比例拆给贡献者”都由合约结算。你会发现,这时候数据不再是“放在某个云盘里给人发链接”,而是真正变成了一种可组合的链上资产。
第三个例子则更贴近今天很多 Web3 用户:内容平台。像媒体文章、长视频、比赛高光、游戏内资产素材,这些东西天然是“重内容、轻状态”:链上只需要记录版权、分润、访问策略,真正占体积的是原始内容本身。Walrus 的一套做法,就是让媒体、内容平台、游戏工作室,可以把大量视频、图片、文章备份在去中心化网络里,然后用链上对象控制每一块内容的付费访问、订阅解锁、会员专享,甚至可以做到“按观看时长结算创作者收入”等更细粒度的模式。官方案例里已经有媒体和内容方把文章和视频迁到 Walrus 上存储,这类验证其实很有说服力。
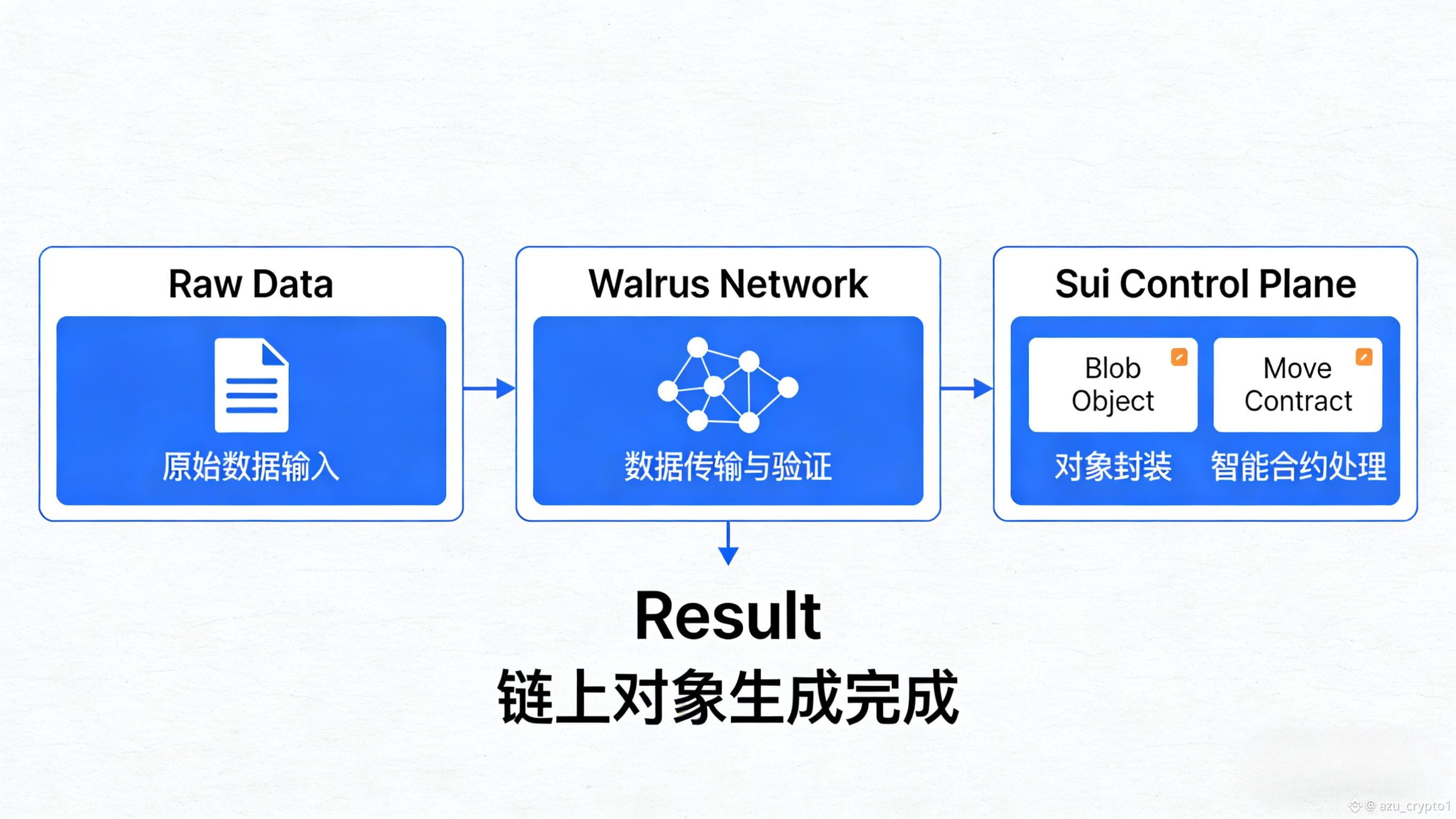
站在开发者视角,我觉得 Walrus 最大的价值,是直接把很多本来要你自己在 Web2 堆栈上拼起来的东西,变成了“链上一站式能力”。传统做法是什么?你要搭一个产品,得先去搞一套对象存储(S3 之类),前面再套一层 CDN,然后自己写一堆服务来做鉴权、签名 URL、计费、审计日志……现在 Walrus 给你的,是“数据 API + 合约逻辑”组合:大文件丢给 Walrus,访问控制交给 Seal 这一类模块,计费和分润逻辑写在 Move 合约里,前端和后端通过 SDK 打通。这种模式下,你的主要心智负担不再是“怎么把存储搞起来”,而是“我要设计一个什么样的经济模型,让数据真的能转起来”。
而对投资者来说,故事会更简单粗暴一点:Walrus 押注的是“AI 时代的数据需求会爆炸式增长,而且对可靠性、可验证性、可治理性的要求远高于过去的文件存储”。你可以把它想象成一个随着 AI 数据集规模、AI agent 数量、数据市场成交量一起放大的协议。官方在多处介绍里都强调,“让数据在各个行业变得值得信任、可证明、可变现、同时是安全的”,这其实已经隐含了一个逻辑:只要 AI 和数据经济在往前走,像 Walrus 这种底层“数据铁路”的价值就不会太差。
当然,这些长期价值感知,最终还是要落回非常具体的指标:链上到底有多少真实 TB 在存?每天有多少次访问?有多少应用在用 Walrus 做核心数据层,而不是浅尝辄止?后面我们还会专门写一整篇,用 Team Liquid、Humanity、Tusky 这些案例去拆真实采用。但在这篇里,我更想先帮你完成一件事——把“Walrus = 便宜存储链”的刻板印象,从脑子里彻底删掉。
如果你只是想找一条“手续费更低、空间更大”的存储链,那 Walrus 对你来说可能有点“杀鸡用牛刀”;但如果你开始认真思考:AI 应用、数据市场、内容平台、身份协议,未来到底需要一个什么样的底层数据基础设施?那你多花一点时间读读 Walrus 的官网、Docs 和白皮书,就会发现它真正想占的位置,是“AI 数据层的可编程底座”,而不是“众多存储盘中的一个选项”。
阿祖,接下来几天我会继续用系列的方式,拆 Walrus 背后的 Red Stuff 编码、开发者工具箱、代币经济和生态数据。你现在要做的,只是先记住一句话:在 Walrus 的世界里,数据不再是埋在某个硬盘里的“成本”,而是被合约、市场和智能体一起反复调用的“资产”。至于这条链值不值得长期关注,就看你相不相信这句话会在 AI 时代变成主流共识了。