阿祖观察了这么久,在去中心化存储这块,很多项目嘴上说自己“安全、可靠、容错高”,真正落到工程方案上,基本就两招——要么粗暴全量多备份,要么简单纠删码撑一撑,看上去都能用,但只要节点一多、churn 一高,要么成本炸裂,要么恢复拖成蜗牛,最后谁都不想真把关键业务放上去。Walrus 敢在白皮书里明说自己是在“成本 + 可用性 + 安全性”三角里找到了新平衡,底气就来自那套 Red Stuff 协议和它背后定义的 ACDS 问题。
先把背景讲清楚。传统全量复制的思路很直觉:一份数据复制十份、二十份,理论上某些节点掉线没关系,剩下节点还能顶上。这种方式的问题也同样直觉——你数据一旦上 TB、PB 级别,冗余一倍是钱,冗余十倍是命。另一类常见做法是简单纠删码,把文件切片成若干数据块和校验块,丢失一部分还能从剩下的重建回来,确实能把成本压下来一点,但在高 churn 的异步网络里,一旦恢复,就会发现自己要在海量节点之间、对着整份 blob 做高带宽重传,工程上非常折磨。Walrus 在论文里直接把这个现实点出来:之前的方案不是成本太高,就是恢复效率在大规模节点掉线下完全扛不住。
那 Walrus 想解决的核心问题到底是什么?他们给了一个正式的名字:ACDS,全称 Asynchronous Complete Data Sharing,也就是“异步完备数据分享问题”。你可以把它想象成这样一个场景:一开始有一组存储节点,大家需要在一个完全异步(延迟未知、消息可乱序)的网络里,共同可靠地持有一份大文件;过程中又会不断有节点加入、离开、宕机,甚至作恶,但协议必须保证两件事不变:一是数据总是完整可恢复,二是你随时可以对这些节点发起挑战,证明他们真的在老老实实存这份数据,而不是骗奖励。Walrus 的论文里写得很明确:他们先定义了 ACDS 这个问题,再提出 Red Stuff 作为第一个在拜占庭环境下高效解决它的协议。
说人话就是:在一个节点经常上下线、延迟不可预测、还有坏人混在里面“薅羊毛”的开放网络里,你要保证数据既不丢,又能随时通过挑战机制抓住装死的节点,而且这一切不能以“十几二十倍冗余”为代价。Red Stuff 的思路非常有意思,它用的是二维纠删编码,而不是传统的一维切片。你可以脑补一张矩阵,把一个大 blob 按照行和列两种维度切成很多“碎片块”(Walrus 里叫 slivers),每个单元格都是一小块编码后的数据。一旦这么排好,你就可以在“行方向”和“列方向”分别做不同门槛的编码:某一维的阈值设置得相对低一点,方便恢复;另一维的阈值设置得更高,提供更强的安全冗余。
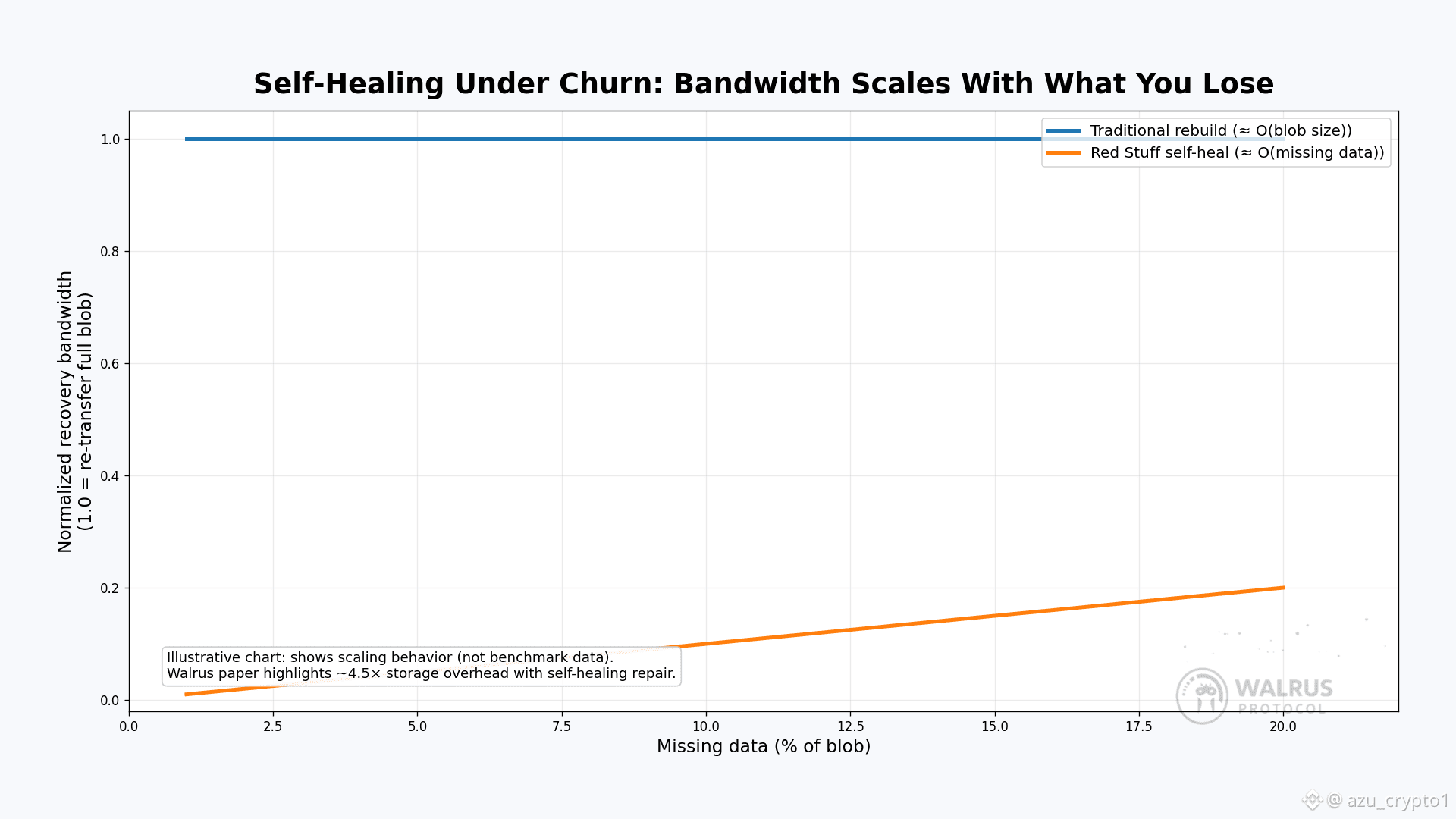
Red Stuff 的精髓就在于:把这两个方向用不同的阈值服务于不同的目标——一边偏恢复效率,一边偏安全性。从算法层面看,它让 Walrus 在只大约 4.5 倍存储开销的情况下,就能获得非常强的容错和恢复能力,这个数字在去中心化场景里是非常激进的,要知道很多保守做法动不动就是十几倍冗余。论文摘要里也是直接点名:Red Stuff 是一个二维纠删编码协议,以大约 4.5× replication factor 换来了高安全性,并且可以做到“自愈恢复”——恢复所需带宽只与丢失的数据量成正比,而不是和整个 blob 大小线性挂钩。
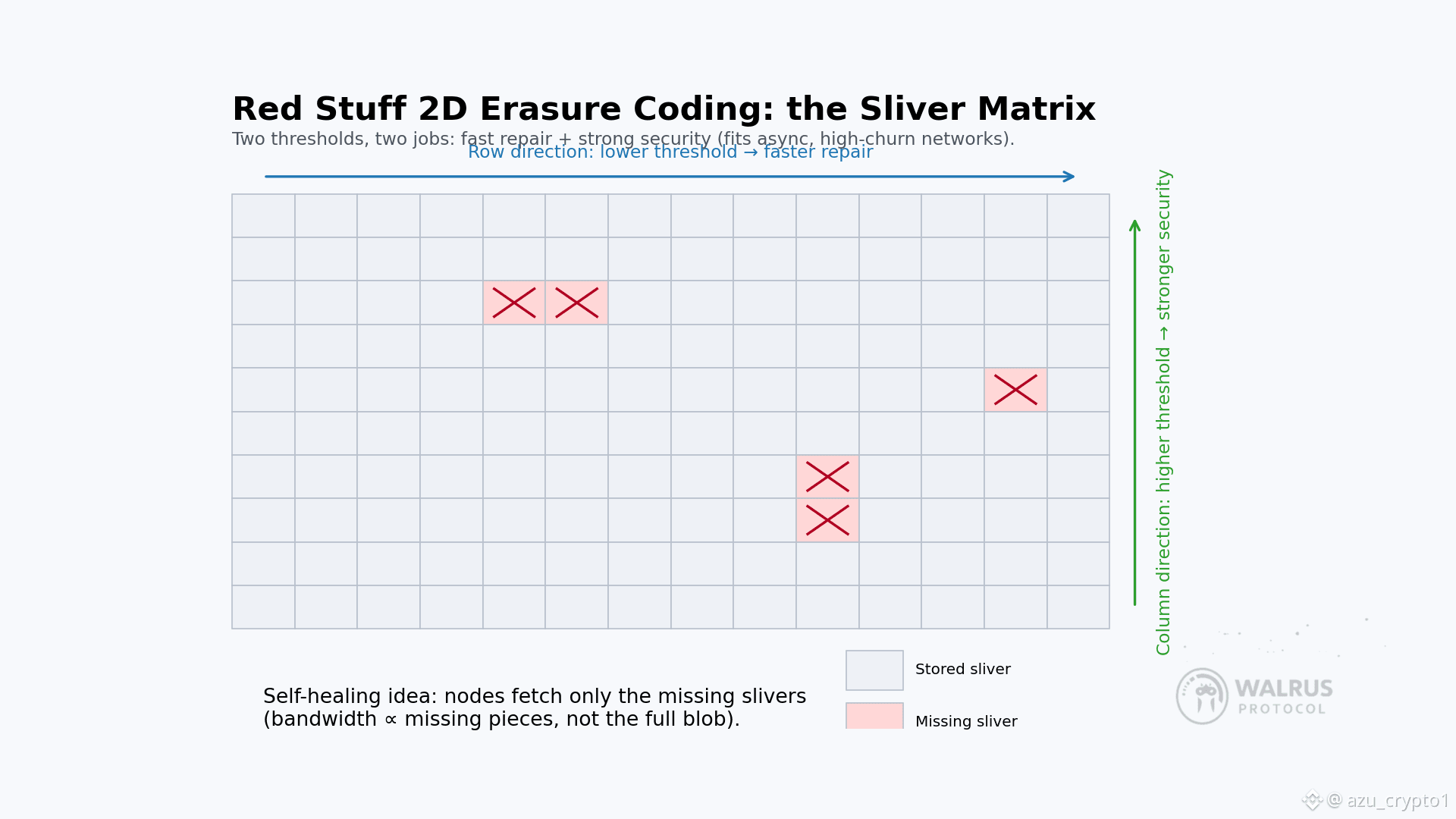
为什么“自愈”这么重要?对真实网络来说,最难受的不是某个节点挂了,而是“经常有人掉线、偶尔有人丢块”。在很多系统里,只要元数据检测到“这份数据会不会不安全了”,就会触发一次大规模重编码或者全量复制,工程成本极高。Red Stuff 的设计让 Walrus 的节点可以更细粒度地“打补丁”:如果某个节点发现自己错过了部分 sliver,或者某些 sliver 在当前集合里已经不足安全阈值,它只需要从其他节点拉取相应的那一小部分编码片段,不需要重新把整份文件拖回来。这就是论文里提到的带宽复杂度差异:在传统做法下,你的恢复操作大致是 O(|blob|),而在 Red Stuff 里可以做到 O(|blob|/n),n 是切片的维度规模。
这也解释了为什么 Walrus 敢说自己是“自愈系统”:协议本身就鼓励并驱动节点在背后不断把局部缺失补齐,直到每个正确节点都重新完整持有它应有的 sliver 集合,而不用依赖某个中心化协调者来下命令。当你把这个过程放到一个长时间运行的存储网络里,就会发现它在不断自动找平网络里的“小坑”,而不是等出事再来一次“大手术”。
再往下一层,是“异步挑战”这件事。之前很多存储协议在做证明时,会默认网络是相对同步的:你发出一个 challenge,在合理时间内收不到回应就当对方作弊。但在真正开放的异步网络里,攻击者可以玩一个很老套的花活——利用延迟、拥塞、选择性转发来“装死”,在不真正存数据的前提下,依旧撞上某些挑战窗口、偶尔混过几次验证。Walrus 在论文里强调,基于 Red Stuff,它实现了第一个适用于异步网络的存储挑战协议:挑战的设计结合了那张二维编码矩阵的结构,即使在消息延迟和乱序的情况下,也很难被攻击者通过简单的“时间差”骗过去。
简单理解就是:异步挑战把“我真的存着你要的那块数据”这件事,从“你信我网速会正常”升级成了“你必须在编码结构允许的范围内给出正确响应,否则数学本身会暴露你”。这对一个想要靠 PoS/质押激励来长期运转的存储网络非常关键,因为一旦挑战机制可以被“演戏”绕过,整个经济模型就会崩塌——节点可以拿着奖励不干活,对真正老老实实存数据的节点形成严重的负激励。
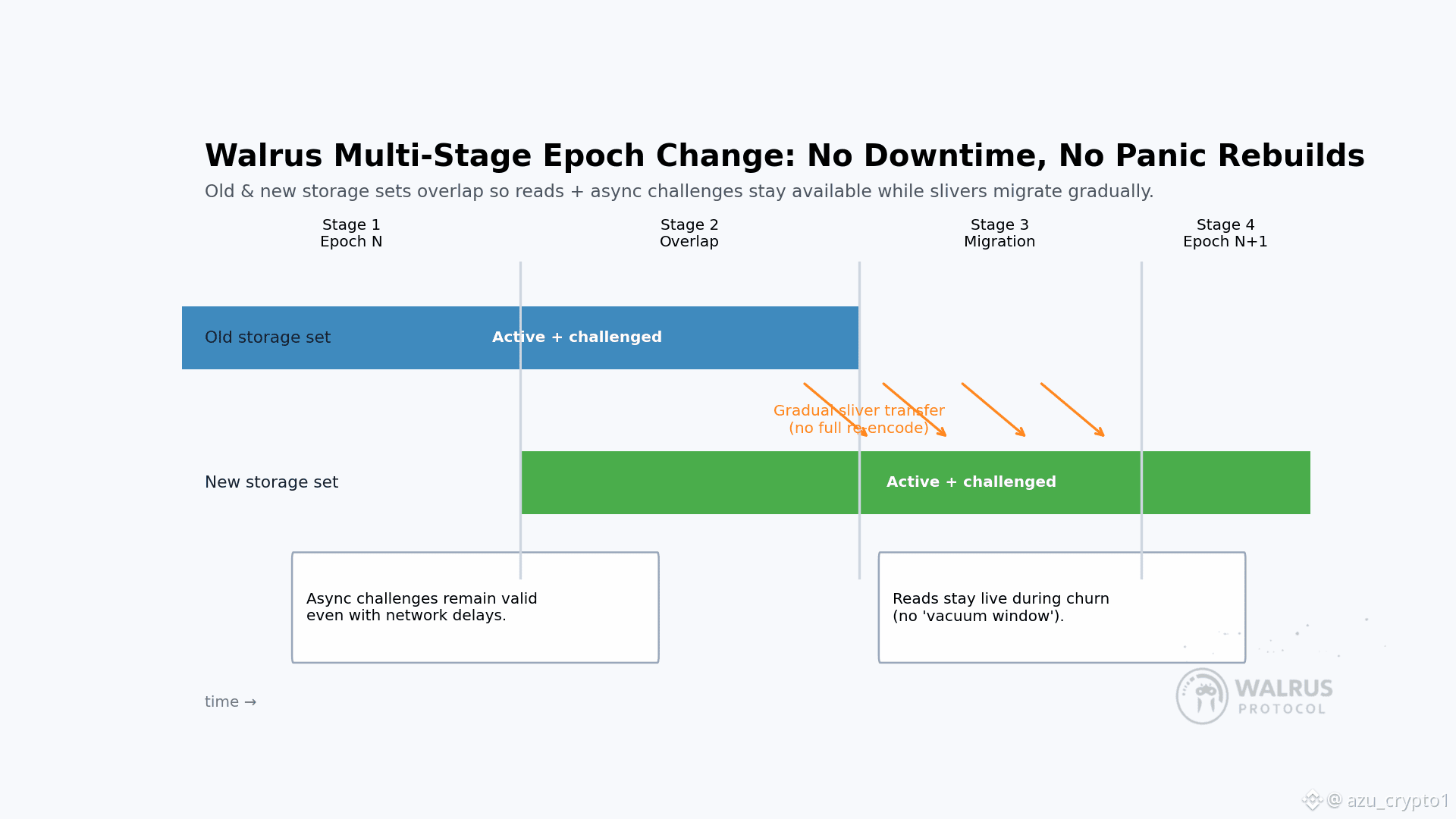
然后是很多人一眼看过去容易忽略,但对工程师来说非常致命的那块:epoch 切换。任何一个长期运行的去中心化网络,都不可能让“谁在负责存这批数据”永远不变,节点会加入,会退出,会失联,会被惩罚,会被替换。如果你没在协议层好好设计这一步,最容易出现的问题有两个:一是每次委员会或节点集变更时,全网读写服务出现“真空期”;二是为了迁移数据,你只能硬着头皮在短时间内触发大规模重分发,拉满网络带宽。
Walrus 的做法是引入一个多阶段的 epoch change 协议,把这件事拆成几个交叠的阶段来做。白皮书里给的描述是:这套多阶段的 epoch 变更机制天然适用于去中心化存储系统,能在节点 churn 的情况下保持高可用性。具体来说,新旧两套节点集在一段时间内会并行承担一部分职责,Red Stuff 那层二维编码让数据可以在两套集合之间渐进式迁移,期间对外提供的读取和挑战能力不至于中断或者明显劣化。
讲到这里,你大概能看出来,Red Stuff + ACDS 并不是孤立存在的“数学花式”,而是 Walrus 整套工程方案的“底层内核”:二维编码负责在成本和恢复效率之间找到新平衡,自愈恢复负责在日常节点 churn 里填坑,异步挑战保证激励和惩罚不被网络延迟玩坏,多阶段 epoch 切换则让整个网络能在长期运转中平滑更新节点集。论文在总结部分也正是这么归纳的:定义了 ACDS,提出 Red Stuff,设计了异步挑战和多阶段 epoch 变更,从而让 Walrus 这条网络在真实环境里保持高完整性、高可用性和合理成本。
如果我们把视角拉回开发者,这些“看上去很学术”的东西,最后落到的其实是三个很朴素的问题:第一,我敢不敢把真正重要的大文件放上去?第二,万一节点经常掉线,我会不会被恢复逻辑拖死?第三,当网络升级、节点轮换的时候,我的应用会不会突然读取不到数据?Red Stuff 和整套 ACDS 设计,其实就是把这三个问题的答案尽可能变成“你可以不用太操心”:协议层已经内建了以 4.5× 开销换来自愈能力和异步挑战的机制,你不需要在应用里再用奇奇怪怪的多云备份、定时冷备来自己兜底。
对投资者来说,这些细节又意味着什么?很简单:这就是技术壁垒。存储协议很容易被表面叙事迷惑——大家都说自己“性能更好、成本更低、安全更强”,但真有人把白皮书摊开,你会发现不少项目在工程层面的创新几乎为零,更多是改改经济模型、换个共识名字。Walrus 这一套明确定义问题(ACDS)、提出新协议(Red Stuff)、在异步环境里把挑战和 epoch 切换都重新设计一遍的做法,客观上提高了“想抄作业”的门槛。你可以 fork 它的代码,但要在真实开放网络里跑出一样稳定的表现,绝不是“抄代码 + 发币”这么简单。
更重要的是,这些工程能力跟 Walrus 想做的 AI 数据层愿景是强绑定的。AI 时代你期待的是一种什么样的数据基础设施?应该是在大规模节点 churn 下依然稳定,在异步网络里依然可验证,在长期节点轮换里依然可用的系统,而不是一条“能跑 demo、不能扛生产”的链。Red Stuff 和 ACDS 把这套“可靠性基准线”往前推了一大步,让一个 DePIN/存储协议有机会真正进入“给 AI 和关键业务做底座”的行列,而不是停留在“备份冷数据”的边缘位置。
阿祖这一篇算是把 Walrus 背后的核心工程底牌先翻了一面:Red Stuff 这套二维编码 + 自愈恢复 + 异步挑战 + epoch 切换,是它敢谈“低复制开销、高可用、高安全”的根本原因。接下来我会继续写 Walrus 的开发者工具链、真实采用数据和 $WAL 的代币经济,把这条链到底值不值得长期盯盘、值不值得开发者上去搬业务好好掰开聊。你现在要做的,就是先把一句老观念扔掉:去中心化存储不是“备份越多越安全”,而是看你在怎样的网络模型里,把成本、恢复和安全重新算清楚。