阿祖来了,兄弟们,这两年看 L1 项目有一个非常直观的变化:以前大家卷 TPS,现在大家卷 AI。白皮书里不是“AI 公链”,就是“AI 模型链”,再不济也要贴个 “agent ready”。但你真把这些项目摊开看,十个里面有九个还是老配方——一条普通 L1,加几条 RPC,把大模型接成小组件,就开始到处喊自己 “AI-ready”。
问题是,AI 真的上链,难道只需要一个更快的 EVM 和几行 API 吗?在我眼里,所谓 “AI-ready”,至少要回答四个问题:你的记忆在哪、你的推理在哪、你的自动化在哪、你的结算在哪。这四块如果都还停留在“链外一坨云服务,链上只记一行哈希”,那你顶多只是把 Web2 的 AI 搬了个壳,而不是在做新的基础设施。
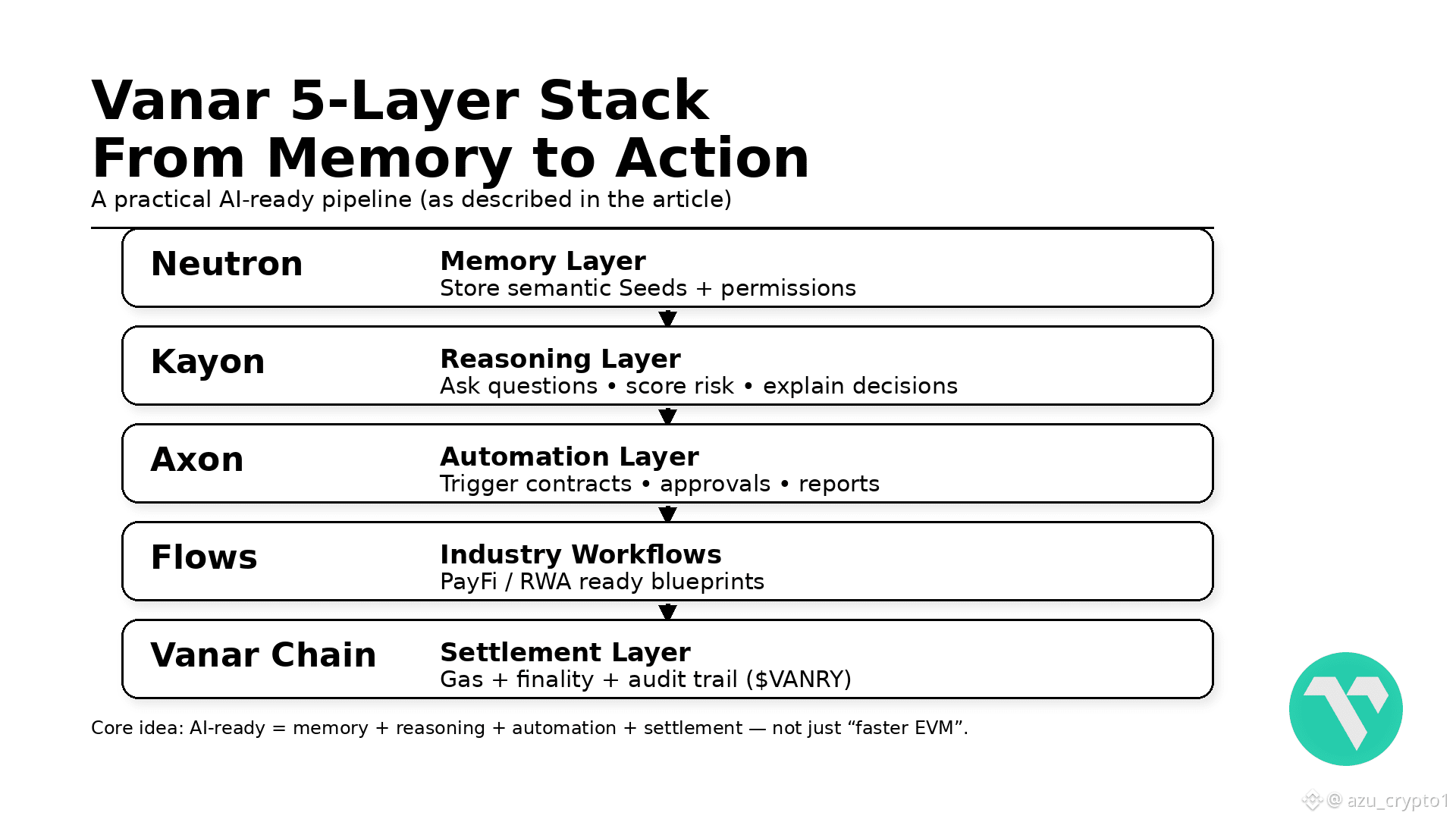
Vanar 比较有意思的地方,就在于它从一开始就把这四件事写进了架构图。官网直接把自己定义成 “THE AI INFRASTRUCTURE FOR WEB3”“The Chain That Thinks”,不是一句空 slogan,而是挂了一整套五层栈出来:Vanar Chain(L1)+ Neutron(语义记忆)+ Kayon(推理)+ Axon(自动化)+ Flows(行业应用)。官方的意思很明确:这不是给 dApp 贴个聊天机器人,而是给 Web3 做一套 原生服务 AI 工作负载、PayFi 和 tokenized RWA 的底层操作系统。
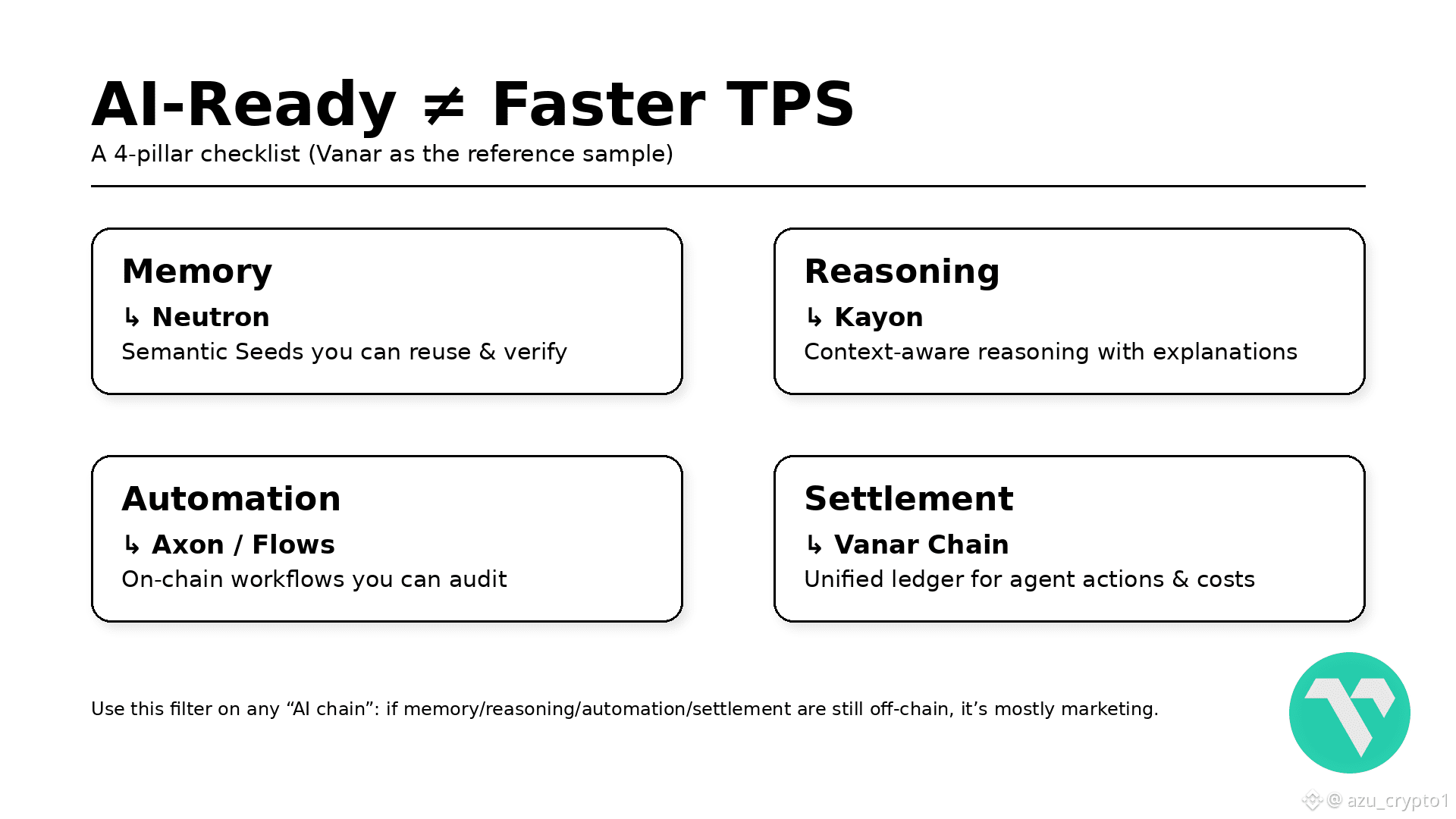
如果把视角从 “TPS 排行榜” 拉回到 “AI 真实用法”,你会发现这五层和我前面说的那四件事,是可以一一对上的:
Neutron = 记忆(Memory)
Kayon = 推理(Reasoning)
Axon / Flows = 自动化(Automation)
Vanar Chain 本身 = 结算(Settlement)
所以今天这篇,我干脆不谈别的,就聊一件事:在 Vanar 的世界里,什么才叫 AI-ready?
先讲“记忆”。你现在用的大部分 AI 产品,最大的问题不是模型不够聪明,而是记忆完全断片。你在一个产品里导入了公司文档、财报、合同,模型勉强懂了你是谁;换一个产品、换一个界面,你又得重头来一遍。而这些记忆本身是没人管的——散落在不同厂商的数据库里,很难复用,更谈不上在链上形成“可验证资产”。
Neutron 想做的,就是把这件事重写一遍。它不是简单提供一个“上传文件”接口,而是把文件压成一种叫 Seed 的语义胶囊:官方给的例子是,一个 25MB 的文档,可以通过语义压缩、嵌入和结构处理,被压缩到大约 50KB 的 Seed,上链存储。这个 Seed 不是 IPFS 那种“我给你一个哈希,至于文件哪天丢了我也不知道”,而是本身就带有语义向量、索引、元数据和权限控制,可以被链上的 AI 直接查询、推理和重组。
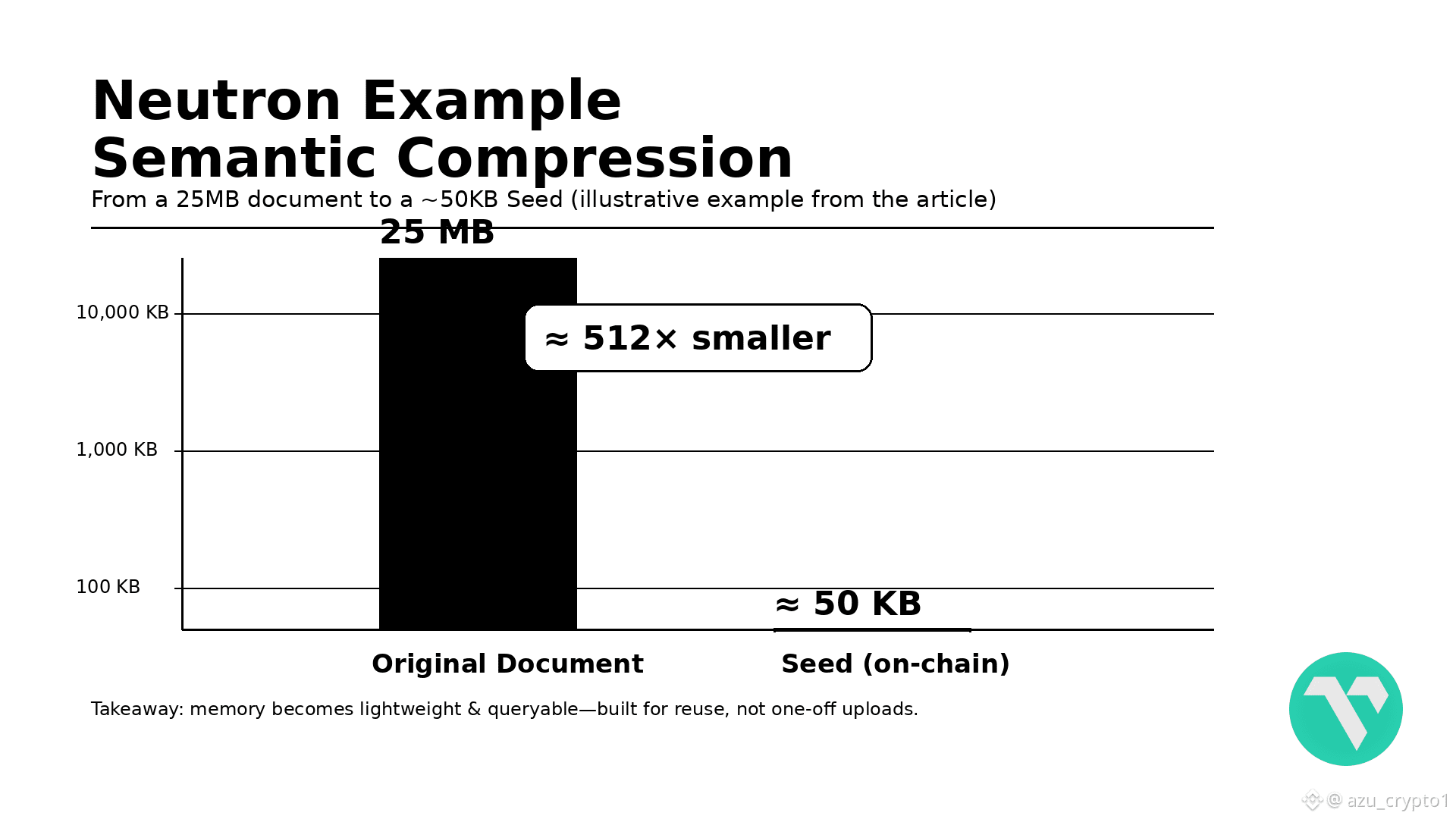
对我这种老用户来说,这是第一次有人认真把“AI 记忆”当作链上资源来设计:
一方面,记忆是持久的。你不用每次换工具重喂一遍上下文,Neutron 可以通过 myNeutron 这类产品,把 Seeds 作为个人 / 企业级记忆层,在不同平台之间共享;
另一方面,记忆是可验证的。你不是把隐私文档随便扔在哪个云厂商里,而是用链做完整性证明,用语义层做索引与访问控制。
这时候,“AI-ready” 这个词,才第一次和“原生 memory” 绑定起来,而不仅仅是“我支持长上下文窗口”。
有了记忆,还需要“会想”的那一层——否则你再多种子,最多也只是一个巨大的向量数据库。Vanar 在第三层给了一个名字:Kayon。官方对它的定义是 “Contextual AI Reasoning Layer”,我的理解就是:它负责把 Neutron Seeds + 链上账本 + 企业数据库 + 合规规则,拧成一台可以回答问题、解释决策的 AI 引擎。
你可以想象这样一个场景:
一个 RWA 协议,底层用 Vanar 做结算。项目方想知道,“过去一周,谁在跨多个司法辖区频繁移动超过 100 万美元,还顺带跟几个高风险地址互动过?这些资金路径有没有合规红线风险?” 传统做法是,找链上分析公司、做批处理、出一堆报表,延迟巨大。
在 Kayon 的视角里,这就是一个可以被自然语言表达的查询:
“基于 Neutron 存的合约文档、地址标签和合规规则,帮我筛出这类钱包,并按风险打分,给出理由。”
Kayon 用来干的就是这件事:它不是单纯跑一个黑盒的风险模型,而是把所有上下文都拉进来——你的 Seeds 里是什么,你链上的资金轨迹怎么走,你绑定的合规规则怎么写——最后给出一个可以被审计、被追溯的结论。对需要做合规的 DeFi、PayFi 或 RWA 平台来说,这种“可解释推理”,才有机会走进牌照框架,而不是停在“娱乐性风控”。
说到这里,你应该能感受到:在 Vanar 的设计里,AI-ready 不是“我有个模型可以叫”,而是“我有一整套让模型有记忆、有脑子、有上下文的基础设施”。
但光会想还不够,链上世界最怕的是“懂很多,却什么都不做”。这一块,就轮到 Axon 和 Flows 了。Axon 是第四层,官方用的是 “Intelligent Automation” 这种描述——我更愿意把它理解成“链上中枢神经”:
它接收 Kayon 的推理结果,
按照预设策略和风控规则,
去触发合约调用、资金划转、权限更改、报表生成等一系列动作。
举个最简单的例子:
一个做跨境薪资发放的 PayFi 应用,员工数据、合同条款、税务规则都塞进了 Neutron;
Kayon 每月跑一轮“检查哪些人符合发薪条件、应该发多少、要不要预扣税”的推理;
Axon 则根据推理结果,调用链上的合约批量发薪、生成报表、写入审计日志。
在这个流程里,自动化不是中心化后台一段脚本,而是可审计、可追责的链上行为。你可以回溯,是什么 Seeds、什么规则、什么推理让某笔工资被发出或被拦下,这对企业财务和监管机构来说,都比“黑盒 AI 决策”安全多了。
至于第五层 Flows,更像是行业“预制装配线”:把上面的记忆、推理、自动化组合成针对特定行业(比如 PayFi、RWA、链上资管)的标准工作流,给开发者和机构一条现成的路走。你不用从零设计“AI + 区块链 + 合规”的组合拳,而是选一条适合自己业务的 Flow,稍微定制一下就能开跑。
最后一块,是最传统但最容易被忽略的——结算(Settlement)。在 Vanar 的五层架构里,最底下一层的 Vanar Chain,本质上还是一个为智能应用服务的 L1:
它要用 $VANRY 作为 gas,给所有 Neutron/Kayon/Axon/Flows 的调用买单;
它要负责把所有这些“有记忆、有推理的行为”落在一个统一的账本上,
让每一笔 agent 的决策、每一个自动化流程都能被追踪、被核对。
这也是为什么 Vanar 在路线图和代币经济里,一直在强调两件事:
一方面,通过 Neutron、myNeutron 这类产品,把真实的查询和调用量引到链上,让 $VANRY 变成“AI 调用的燃料”;
另一方面,通过 buybacks & burns 这种机制,让这些产品收入反向作用在代币身上,而不是单纯依赖通胀挖矿堆 TVL。
对我来说,这才是“AI-ready 结算层”应该长的样子:不是只给人刷 NFT 的高 TPS 链,而是一条能顶住高频微交易、Agent 行为、合规审计、RWA 结算压力的底层网络。
所以,当别人还在哄抢“新一代 AI 概念链”、比谁的 TPS 更漂亮的时候,我现在看项目,会先掏出这四个问题来当筛子:
你的 记忆(Memory),是一次性喂模型,还是有原生的、可复用、可验证的记忆层?
你的 推理(Reasoning),是在链下黑盒里跑,还是能结合链上数据、企业数据、规则做可解释推理?
你的 自动化(Automation),是中心化后台脚本,还是链上可审计的工作流和合约组合?
你的 结算(Settlement),是一条随便找的公链,还是底层就为 AI 工作负载和 PayFi / RWA 优化过的执行环境?
Venar 给出的答案,是一个五层栈:Neutron + Kayon + Axon/Flows + Vanar Chain + $VANRY。在这个结构下,“AI-ready” 不再是一句挂在首页的 marketing 文案,而是一个可以拆开、可以验证、可以对照其他 L1 的工程标准。
接下来几天,我会单独拆 Neutron、Kayon、Axon、Flows,分别从“技术原理”和“对用户 / 投资者的实际意义”两个维度继续往下写。如果你已经对 AI、公链、PayFi、RWA 这些叙事有点审美疲劳,不妨用这套四件套框架,先去把市面上那些“AI 概念链”过一遍,再回头看看 Vanar 和 $VANRY 在你心里的排序是不是有点变化。
至少对我阿祖来说,当别人还在拼 Model+UI 的时候,这套从记忆、推理、自动化到结算的五层怪物栈,已经值得我多看几眼了。