Been going through openledger’s architecture and token/incentive docs in parallel, and i keep alternating between “ok, i see the shape of this” and “wait, who is enforcing the hard parts?” what caught my attention is that openledger’s core bet isn’t really decentralized storage (that’s the easy checkbox). it’s the idea that data + model usage can be turned into on-chain economic coordination: you contribute data, a model uses it, usage gets attributed, and the protocol settles rewards without a single platform acting as the accountant.
most people think openledger is just another ai + crypto token where you upload a dataset and earn emissions. honestly, that’s a reasonable default assumption given how many data marketplaces never pull real demand. but if openledger works, it’s because attribution becomes the durable primitive, not because the token pumps or because the dataset list grows.
the way i’m currently decomposing it:
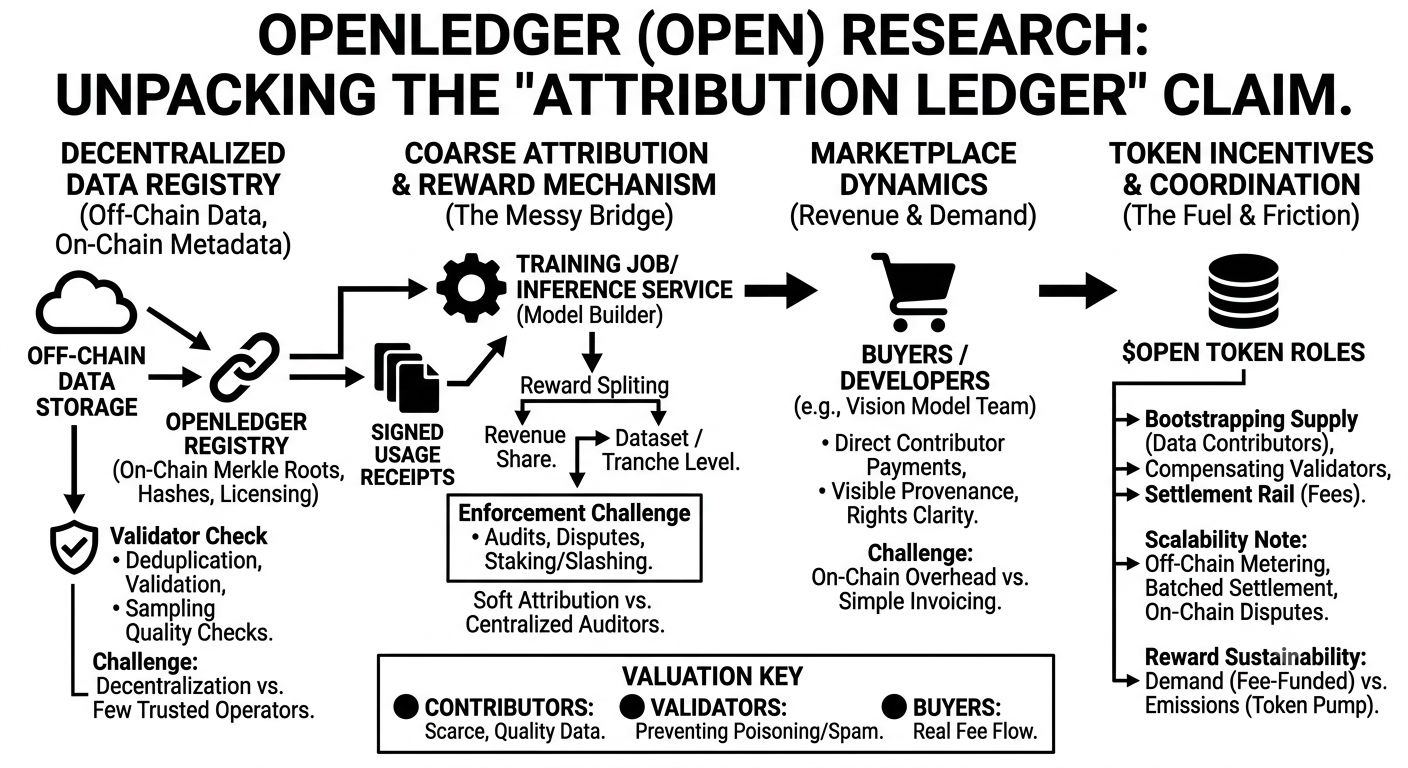
1) decentralized data contribution system (data plane vs registry plane)
it seems like the protocol is more of a registry + rules engine than a place where the bytes live. data sits off-chain; on-chain you anchor hashes/merkle roots, metadata, schema ids, and licensing terms. that’s practical. the long-term question is how “open” ingestion can be without drowning in junk. you can do dedup, schema validation, and sampling-based quality checks, but those checks are run by someone. so you end up with curators/validators as an economic role, and then decentralization depends on whether that role stays competitive or ossifies into a small set of “trusted operators.”
2) attribution + reward mechanism (the messy bridge)
and this is the part i keep thinking about. attribution is easy to promise and hard to make credible. i don’t think per-record marginal contribution is realistic anytime soon; it’s too expensive and training pipelines are too variable. so the more believable mechanism is coarse attribution: training jobs/inference services reference dataset ids (or specific versions), produce signed usage receipts, and then rewards get split at the dataset/tranche level. but then enforcement becomes the whole game: what stops a model builder from “forgetting” to reference a dataset, or referencing only the cheapest ones? audits, dispute windows, staking/slashing, and reputational scoring can help, but none of that is truly automatic unless there’s some trusted metering or attestation layer.
3) marketplace dynamics (buyers decide if any of this matters)
openledger’s contributor incentives only become sustainable if there are recurring buyers paying fees. a realistic example: a dev shop fine-tuning a small vision model for retail shelf auditing. they need fresh in-store images + bounding boxes, and they need rights clarity because it goes into a commercial product. today they’d likely contract a labeling vendor and accept opaque provenance. openledger’s pitch is: contributors get paid directly, provenance is visible, and downstream model revenue can route back upstream. i can see the appeal, but i’m unsure how many buyers want the overhead of on-chain settlement vs a single invoice.
4) token incentives + network coordination / scalability
the token is doing multiple jobs: bootstrapping supply, compensating validators, and serving as the settlement rail. that multi-role design is common, but it’s also where incentive misalignment creeps in. if emissions are high, you incentivize “data production” even when demand is low, which tends to create spam, duplicated datasets, and low-effort labeling. scalability-wise, if openledger tries to settle per-inference micro-royalties directly on-chain, it’ll hit throughput/cost ceilings fast. so i assume it’s more like: off-chain metering + batched settlement + on-chain disputes. but then you’re trusting the metering layer (indexers, oracles, tee attestations, whatever they pick).
going deeper: who actually creates value here? contributors do, but only if they produce scarce, usable data with clean rights. validators create value by preventing the dataset layer from becoming a liability (poisoning, copyright messes, synthetic spam). and buyers create value by bringing real fee flow so rewards aren’t just emissions recycled inside the system. openledger’s design seems to assume demand for specialized, continuously-updated datasets stays strong as more teams deploy narrower models. plausible, but not guaranteed—synthetic data and closed partnerships could eat a lot of this market.
the tension i can’t shake is: attribution systems tend to work best when participants already trust each other or when enforcement is strong. open protocols are adversarial by default. if attribution is soft, serious buyers will route around it. if enforcement is hard, you risk centralizing around a few auditors/validators who can actually prove things.
no perfect conclusion. i’m still trying to decide if openledger is building a sustainable coordination layer, or just attaching token incentives to infrastructure before real demand exists.
watching:
- fee-funded payouts vs emission-funded payouts (trendline matters more than absolute)
- validator concentration + dispute frequency (do challenges actually change outcomes?)
- dataset quality signals: dedup rates, rejection rates, independent audits
- repeat buyer retention (same teams paying for multiple cycles, not just pilots)
if openledger had to choose, does it prioritize strict verification (and friction) or easy onboarding (and more trust assumptions)? i’m not sure you get both for free.