Es turpinu domāt par kredītreitingiem nedaudz neērtā veidā. Nevis tāpēc, ka tie ir perfekti, tie nav, bet tāpēc, ka tie pārvērš nekārtīgu uzvedību kaut kādā citā sistēmā, kas var rīkoties. Bankai nav jāzina visi detaļas par personas dzīvi, pirms nolēmj, vai piešķirt kredītu. Tā skatās uz strukturētu ierakstu, neperfektu un dažreiz negodīgu, bet atkārtoti izmantojamu. Šī maza ideja turpina atgriezties, kad es skatos uz OpenLedger un $OPEN. Sākumā es skatījos uz projektu galvenokārt caur parasto AI-datu objektīvu: dalībnieki sniedz datus, modeļi tos izmanto, atlīdzības plūst atpakaļ. Pietiekami skaidrs. Bet jo vairāk es sēžu ar to, jo vairāk es jautāju, vai šī ietvara ir pārāk plakans.
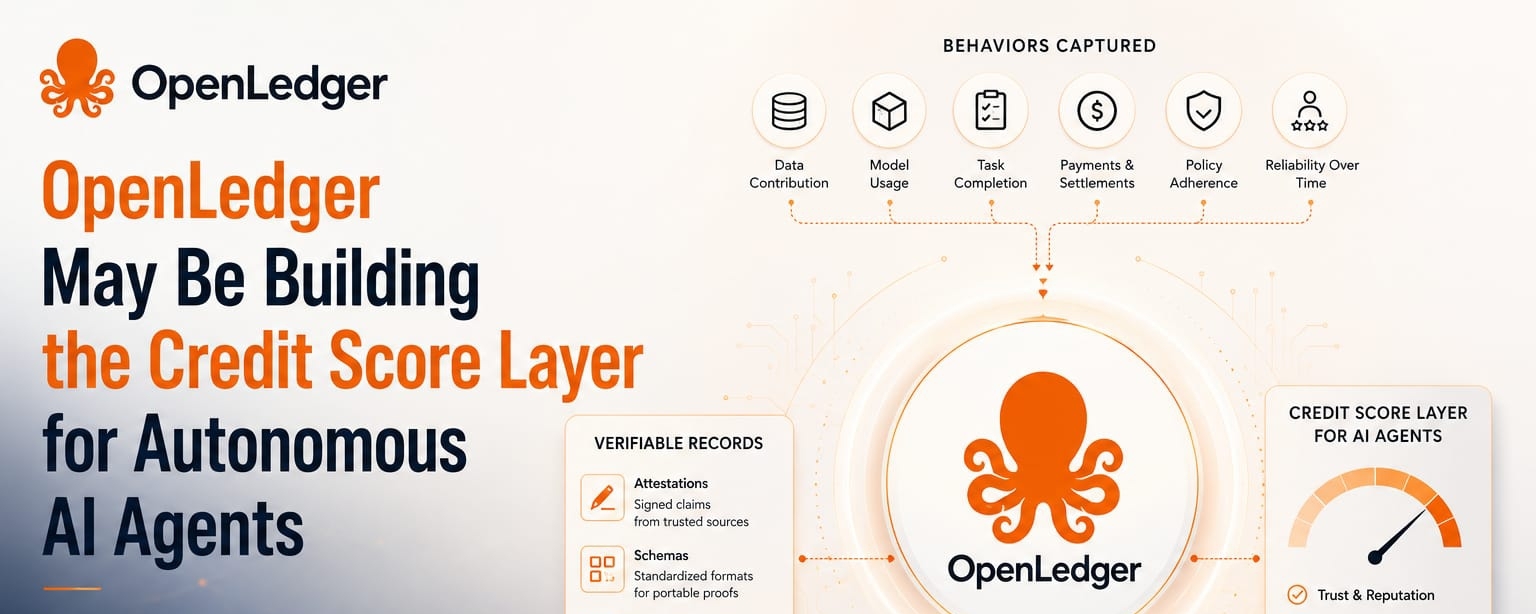
Autonomi AI aģenti rada savādāku problēmu nekā parastie lietotāji. Cilvēks var veidot reputāciju sociāli. Uzņēmums var iesniegt dokumentus, parakstīt līgumus, uzturēt kontus un uzkrāt publisku darbības vēsturi. Bet AI aģents, kas darbojas pāri tīkliem, rīkiem, makiem, API un tirgiem, automātiski nenes uzticamu identitāti no vienas vietas uz citu. Tas var izpildīt uzdevumus, bet izpilde nav tas pats, kas ticamība. Tas var bieži mijiedarboties, bet aktivitāte nav tas pats, kas uzticamība. Šeit OpenLedger sāk izskatīties mazāk kā vienkāršs ieguldījumu reģistrs un vairāk kā agrīna mēģinājuma strukturēt uzvedības atmiņu.
Kredītreitinga slānis AI aģentiem nenozīmētu tieši kopēt patērētāju kredītu sistēmu. Tas būtu pārāk rupjš. Svarīgi ir funkcija. Sistēmai ir jāatceras, vai aģents ir godīgi izpildījis darbu, pareizi izmantojis datus, ievērojis atļaujas, apmaksājis līdzdalībniekus, izvairījies no manipulācijām un uzvedies konsekventi, kad stimulu mainījās. Kripto terminos tas varētu būt atkarīgs no apliecinājumiem, kas ir vienkārši parakstītas prasības, ka kaut kas notika. Datu avots sniedza šo. Modelis izmantoja to. Aģents izpildīja uzdevumu šajos noteikumos. Punkts nav atklāšana pašas dēļ. Punkts ir atkārtoti izmantojams pierādījums.
Šī atšķirība ir svarīga. Liela daļa kripto infrastruktūras joprojām uztver pierādījumus kā kvīti. Kaut kas notika, tāpēc tas jāpieraksta. Bet tirgi parasti vairāk rūpējas par to, ko ieraksts ļauj vēlāk. Kvalifikācija, piekļuve, cenas, reputācija, ierobežojumi, maršrutēšana. Ja OpenLedger var palīdzēt pārvērst AI dalību strukturētos ierakstos, tad $OPEN mēdz sēdēt tuvāk interesantākai kārtai nekā pamata atlīdzībām. Tas var palīdzēt izlemt, kuri aģenti tiek uzskatīti par uzticamiem dalībniekiem un kuri paliek anonīmi ar nevienu uzkrāto svaru.
Es esmu piesardzīgs šeit, jo tirgus bieži pārspīlē jebko, kas izklausās kā identitāte. Mēs to esam redzējuši iepriekš. Maku reitingi, dvēseles piesaistīti tokeni, reputācijas paneļi, ieguldījumu nozīmītes. Daudzas izskatījās noderīgas, līdz stimulu zuda un lietotāji pārstāja rūpēties. Grūtais jautājums ir, vai uzvedība turpinās dabiski atkārtoties. Vai aģentiem ir nepieciešams šis ieraksts, jo tas samazina berzi, atslēdz darbu, samazina risku vai uzlabo piekļuvi? Vai tas ir tikai vēl viens metriks, kas radīts, jo sistēma vēlas kaut ko izmērām? Tās atšķirības starp lietošanu un reālo pieprasījumu ir vieta, kur lielākā daļa token naratīvu tiek atklāti.
Tomēr AI aģenti padara jautājumu asāku. Ja aģenti kļūst par ekonomiskiem aktoriem, viņiem būs nepieciešams kaut kas starp maka adresi un juridisku entītiju. Maku var turēt aktīvus, bet tas nevar izskaidrot uzticību. Juridiska entītija var uzņemties atbildību, bet daudzas AI darba plūsmas pārvietosies ātrāk, mazākas un modulārākas nekā tradicionālās uzņēmējdarbības struktūras. Tāpēc trūkstošā kārta var būt operatīvā uzticamība. Ne identitāte kā biogrāfija. Identitāte kā uzkrāta uzvedība. Tas ir vēsāks jēdziens, bet droši vien noderīgāks.
OpenLedger iespējams loma ir interesanta, jo atribūcija atrodas tuvu šim uzticamības slānim. Ja aģents izmanto datus, maksā par piekļuvi, ģenerē izejas un rada apakšējo vērtību, tad sistēmai ir jāseko ne tikai tam, kas piedalījās, bet arī tam, cik uzticama šī dalība kļuva laika gaitā. Shēmas var būt svarīgas šeit. Shēma ir vienkārši standarta formāts, lai aprakstītu ierakstus, lai dažādas sistēmas varētu saprast to pašu pierādījuma veidu. Bez shēmām reputācija kļūst par nekārtīgu stāstījumu. Ar shēmām tā var kļūt par pārnēsājamu loģiku.
Ir arī selektīvas atklāšanas aspekts, taču es to negribētu pārvērtēt. Selektīva atklāšana nozīmē rādīt tikai nepieciešamo ieraksta daļu, nevis atklāt visu. Aģents var pierādīt, ka tam ir tīrs uzdevumu vēsture, neizpaužot katru klientu, datu kopu vai darba plūsmu. Nulles-zināšanu pierādījumi var to atbalstīt, pierādot, ka nosacījums ir patiess, neizpaužot pamatinformāciju. Atkal, vienkāršā versija ir šāda: uzticība var prasīt privātumu, jo pilnīga caurredzamība var kļūt par risku.
Attiecībā uz $OPEN dziļāks jautājums ir, vai tokens uztver atkarību vai tikai aktivitāti. Aktivitāti var audzēt. Atkarība ir grūtāka. Ja aģenti, izstrādātāji, datu sniedzēji un lietojumprogrammas atkārtoti nepieciešami OpenLedger ierakstus, lai pieņemtu lēmumus, tad tokena nozīme kļūst saistīta ar sistēmas atmiņu. Ja nē, tas riskē kļūt par vēl vienu atlīdzības aktīvu, kas klejo ap naratīvu, kas izklausās spēcīgāks nekā uzvedība, kas tam pamatā.
Es nedomāju, ka tas ir atrisināts. Varbūt OpenLedger paliek galvenokārt atribūtu un datu ekonomikas slānis. Varbūt aģenta kredītreitinga ietvars ir pārāk agrs. Bet es arvien atgriežos pie tā paša tirgus modeļa: vērtīgais slānis bieži nav tas, kas izskatās visaktīvākais. Tas ir tas, no kura citas sistēmas klusi pārtrauc atkārtoti sākt no nulles.
