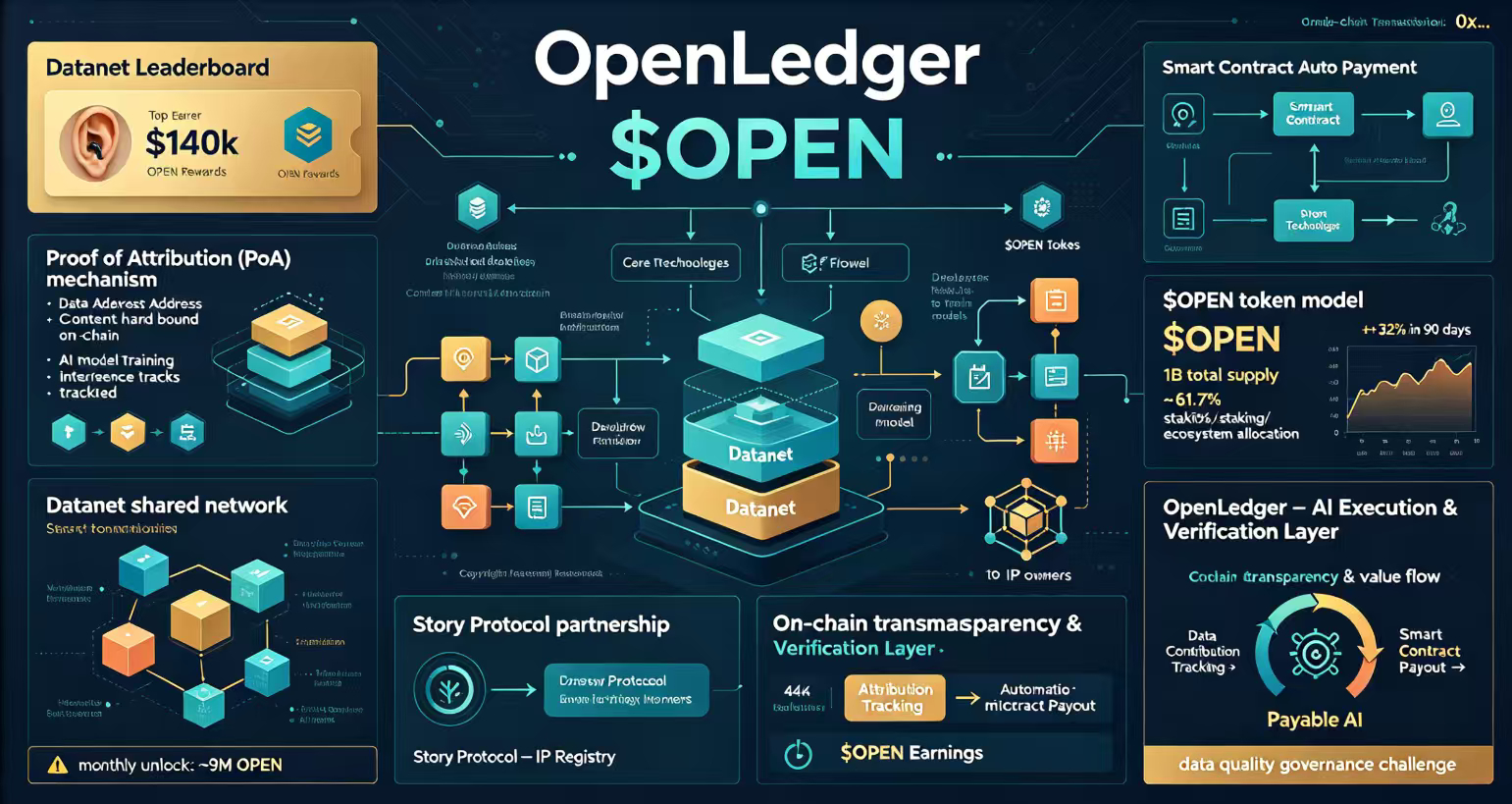
前两天有个链上数据让我盯了大半夜。@OpenLedger 的Datanet Leaderboard上,几个早期数据贡献者已经从$OPEN的自动分配里拿到了实打实的收益,排名靠前的地址累计收益折合下来差不多有14万美金。不是交易所刷量那种虚的,是智能合约按照PoA归属证明自动打过去的,每一笔都能在链上查到来龙去脉。
这事之所以让我上头,是因为它把“数据能赚钱”这句话从一个喊了十年的口号变成了一串看得见摸得着的哈希值。
咱们先把镜头拉远一点。过去两年AI行业卷得要死要活,大模型参数从几十亿干到几万亿,Claude和Codex这些框架把推理能力推到了让人头皮发麻的高度,Agent生态也肉眼可见地越来越能打。但是有个问题一直被压在底下没人愿意正面聊:这些模型是拿谁的数据训练出来的?全球AI公司估值加起来几万亿美金,给数据提供方的回报是多少?说白了就是零,甚至可以说是负数,因为你的数据被拿去训练模型之后转过头来还要替代你的工作。
这事放在2025年之前大家可能还觉得无所谓,但风向已经在变了。2025年针对AI公司的知识产权诉讼成批成批地冒出来,美国公众对AI的信任度过去五年掉了将近一半,监管的绳子越收越紧。OpenAI和Google都在被起诉,核心争议点就是训练数据的来源到底合不合规。说白了市场在逼着整个AI行业回答一个绕不过去的问题:你的数据到底哪来的,用了谁的,该不该付钱?
@OpenLedger 这帮人盯上这个痛点盯得相当早,2024年7月就拿了Polychain Capital和Borderless Capital领投的800万美金种子轮,HashKey Capital、Mask Network这些老牌机构也跟了进来。但真正让我觉得他们不是在卖PPT的节点,是2026年1月那条爆炸性新闻:Story Protocol和OpenLedger联合搞了一套AI版权自动付费的新标准。
这条新闻我当时第一时间就注意到了。世界知识产权组织的数据说全球IP市场规模超过80万亿美金,这个数字大得有点不真实,但它确实说明了一件事:创意和知识的产权本身就是一个比AI大模型大得多的赛道。两家的合作框架听起来其实不复杂:创作者在Story Protocol上把自己的作品注册成IP资产,AI系统通过@OpenLedger 的链上标准来获取授权,训练或者生成内容的过程中自动触发付费,钱直接打到版权持有人手里。OpenLedger的人说得也挺硬气,要把AI从“先训练后诉讼”的老路子拧成“只用能证明有权限使用的内容”。这句话的潜台词其实就是:AI行业靠白嫖数据的日子,已经在倒计时了。
不过版权自动付费只是整个拼图的一部分。真正让OpenLedger跟市面上那些AI概念项目拉开差距的,是它底层的技术逻辑。他们搞了一套叫Proof of Attribution的东西,本质上就是给每一份数据打上链上“身份证”,AI模型用这份数据训练也好推理也好,贡献都能被系统追踪到,然后智能合约自动分配$OPEN作为回报。这套机制跟YouTube的创作者分成在商业逻辑上有点神似,区别在于YouTube分的是广告费,而OpenLedger分的是AI模型消耗数据时产生的价值。
PoA具体怎么跑通的我后来专门去翻了一下他们的技术资料。整个过程拆开来大概是这样:数据贡献者把数据集上传到一个叫Datanet的共享网络里,每条数据都会跟贡献者的链上地址和内容哈希永久绑定-。开发者从Datanet里取数据训练模型或者跑推理,每一次调用都被PoA记录在案,系统根据实际使用情况计算贡献比例,最后通过$OPEN完成支付。不是那种“上传就给你一笔买断费”的一次性买卖,而是“数据被用得越多你赚得越多”的持续分红模式。这也是为什么我觉得Datanet这个概念比看起来要硬核得多,它实际上是在把数据从生产资料升级成了一种可以产生现金流的资产。
OPEN在整个经济模型里的角色也挺有意思。总供应量10亿枚,社区和生态分配占比高达61.71OPEN在整个经济模型里的角色也挺有意思。总供应量10亿枚,社区和生态分配占比高达61.71OPEN价格在0.2美元上下浮动,市值大概4400多万美金,近90天涨了32%左右。实话实说这个盘子放在整个加密市场里不算大,但换个角度想这也意味着生态还处在很早期的阶段,链上活跃度和质押率能不能持续走高才是决定$OPEN长期价值的核心变量,而不是短期的价格波动。
聊到这有个视角我觉得挺值得拿出来说的:很多人还习惯把OpenLedger归类成“AI公链”或者“AI+区块链”这种大而化之的标签,但我越研究越觉得这个归类跑偏了。它真正在干的活不是在跟以太坊或者Solana抢生态,而是要把AI产业链里最不透明的价值分配环节拆开了重新设计。数据谁提供的、模型谁训练的、Agent谁部署的、收益该归谁,这些东西在过去全部锁在中心化公司的黑盒子里,外面的人除了猜什么也做不了。OpenLedger在做的事情相当于给AI行业装了一套透明的账本系统,而且这个账本不是靠某一家公司拍胸脯保证的,是靠链上可验证的记录来支撑的。
当然话说回来,这事儿也不是没有挑战。最现实的一个问题就是解锁抛压:从2026年3月开始投资人每月大概有508万枚$OPEN 解锁,团队那边每月416万枚。每个月加起来接近一千万枚的增量供给,如果生态内的真实需求跟不上,价格肯定要承压。这个问题没有太多花里胡哨的解法,只能看Datanet的规模能不能持续扩大、开发者生态能不能真的跑起来。目前官方说已经有12个开发团队在平台上构建,年底目标是100个,这个数据到今年四季度回头看才知道含金量有多少。
另一个更底层的挑战可能在于数据质量本身。链上能解决归属证明和自动分配的问题,但数据本身是不是高质量的、有没有噪声、会不会被人故意污染,这些还得靠社区治理和经济激励来慢慢磨合。PoA把“谁贡献了”搞清楚了,但“贡献的东西有没有用”这个问题还需要市场来检验。
我把话往回拉拉。14万美金这个数字放在整个加密世界里可能连个水花都算不上,但它的意义在于证明了OpenLedger这套Payable AI的逻辑不是空中楼阁,是真金白银在链上跑了三个多月跑出来的东西。当AI从“黑盒时代”被迫走向“可验证时代”,最先站住脚的那些基础设施,往往就是下一轮周期里最猛的α。
$OPEN 能不能成为那个α的核心标的,我不会下结论。但有一件事我越来越确信:未来五年AI行业最有价值的战场,可能根本不在模型的参数表里,而在谁能把数据的价值归属写进代码里。OpenLedger至少正在试着写第一行。#OpenLedger