Have been going through openledger’s architecture bits (docs, diagrams, a couple interviews), mostly trying to understand how they expect data to move from “someone uploaded a dataset” to “a model used it” to “money flows back on-chain.” what caught my attention is they’re trying to turn that messy path into something ledger-like: a chain of custody for data + usage receipts + rewards. honestly that’s the only reason this is interesting; decentralized storage alone isn’t a moat.
Most people think openledger is just another ai + crypto token: contribute data, earn tokens, repeat. but that narrative skips the hard part, which is: can you make attribution credible enough that builders will pay, and can you do it without recreating a centralized gatekeeper (just with extra steps)?
the components I'm currently using to reason about it:
Decentralized data contribution system
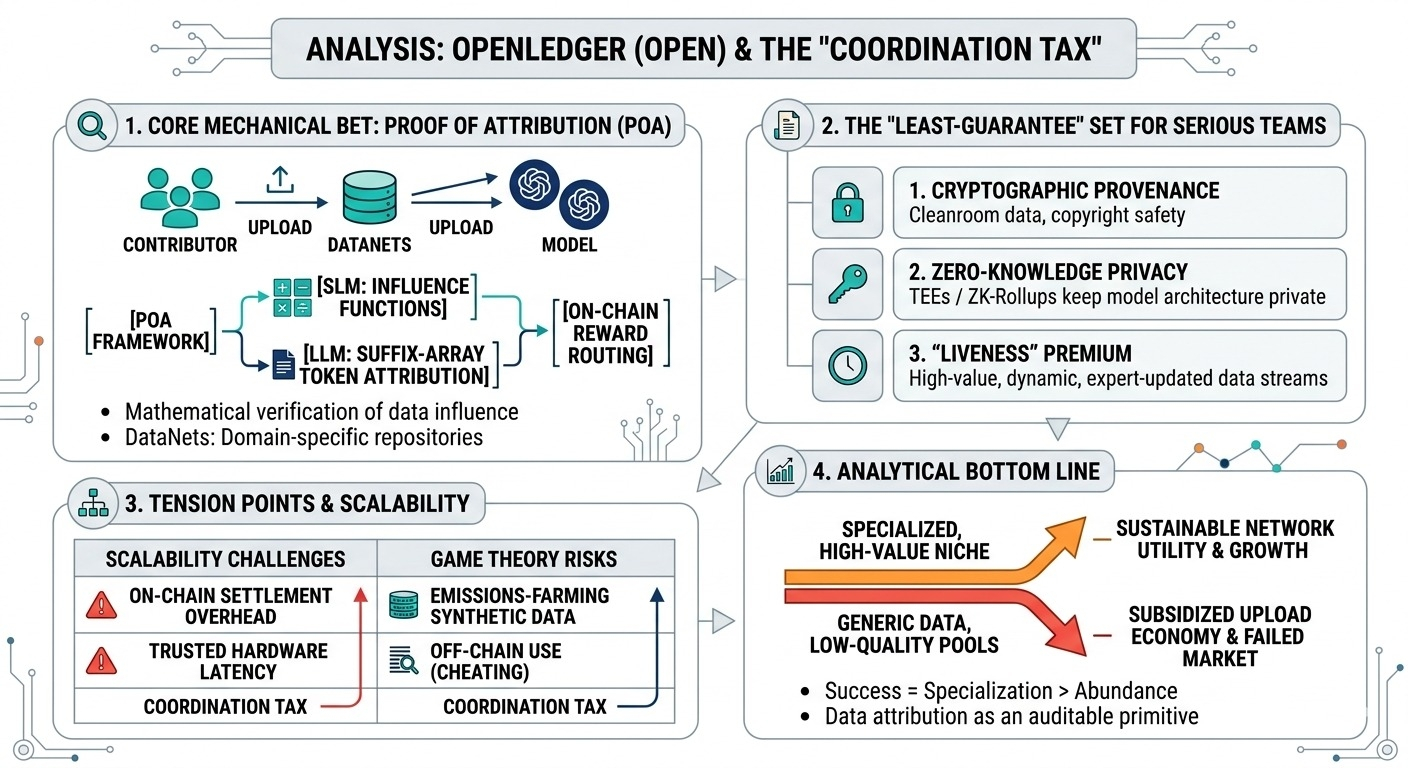
the core looks like a pipeline where contributors publish datasets with standardized metadata and content hashes (so you can reference the same artifact across participants). the network design question isn’t “can you store files,” it’s “can you keep the dataset layer clean.” permission less uploads are great until you have 10 million near-duplicates, poisoned data, or label noise that’s impossible to detect cheaply. so either openledger leans on curation (humans, committees, reputation) or on automated validation (which tends to be shallow). I'm not sure yet where they land, but the tradeoff feels unavoidable.Attribution + reward mechanism
openledger’s bet is that contributions can be tracked and paid based on downstream usage. and this is the part i keep thinking about… training attribution is not naturally auditable. even if a model builder includes dataset hashes in a training manifest, someone has to trust the manifest. you can imagine attestations from model runners, or some “verifier set” that checks logs, or trusted hardware proofs, but every option introduces overhead and new failure modes. if attribution is too weak, the rewards become vibes-based. if it’s too strict, it slows everything down and model builders just won’t bother.Marketplace dynamics (data ↔ models ↔ apps)
the implied market is: data suppliers list assets, model builders buy or subscribe, apps pay for inference, revenue gets routed back. in centralized setups, the “market” is often a contract + support + quality guarantees. openledger has to replace that with protocol guarantees, or at least credible reputation. I suspect the first viable niche is not generic pretraining data (too abundant), but high-value, regularly updated datasets and eval sets. those have repeat purchase behavior, which is what you need for sustainability.Token incentives + coordination / scalability layer
the token seems to be doing multiple jobs: bootstrapping contributions, settling payments, and coordinating participants (staking, access, maybe slashing/disputes). multi-purpose tokens can work, but they also blur the line between “people are paid because the network is useful” and “people are paid because emissions exist.” the scalability question is also real: if every micro-usage needs on-chain settlement, costs explode. so you end up with batching, off-chain accounting, periodic settlement, or some hybrid. again, not bad, just means the “decentralization” is partly procedural.
Zooming out: who creates value? contributors only create value if the data is net-new, high-signal, and legally usable. model builders create value if they can measurably improve a model (or reduce training cost) using openledger data. but model builders are also the ones who can most easily game reporting. so the protocol implicitly assumes either (a) builders are honest because reputation matters, or (b) there’s an enforcement layer that makes lying expensive.
A concrete example: imagine a customer-support agent model that needs fresh, labeled transcripts for a specific enterprise domain (say, billing disputes). contributors could upload anonymized conversation snippets with outcome labels; the model builder fine-tunes weekly and sells an API. openledger works if (1) the anonymization/labeling is trusted, (2) the fine-tuner can prove inclusion without leaking proprietary training details, and (3) rewards don’t attract a flood of synthetic “fake transcripts” optimized for farming.
Tension points I can’t shake:
The whole thing depends on future ai demand being willing to externalize data procurement into an open network (many teams still prefer private pipelines)
Incentives might drift toward quantity over quality unless there’s strong filtering
Token emissions can fake traction for a long time, and it’s hard to tell when real utility has arrived
Attribution systems often look clean in diagrams and get weird at scale
watching:
% of contributor rewards funded by actual usage fees vs emissions
Dataset health: duplication rates, dispute rates, curator concentration (if any)
Repeat buyers: are model builders subscribing to updates or doing one-off experiments?
Enforcement signals: real disputes resolved, slashing/penalties, or audited usage receipts
No perfect conclusion yet. I can see a path where openledger becomes a decent coordination layer for specific data markets, but I can also see it turning into a subsidized upload economy. the question I'm left with is pretty basic: what’s the smallest set of guarantees that convinces a serious model team to pay for data here, repeatedly, when they could just keep everything internal?