OpenLoRA: The Gap Between AI Education and Practical Implementation
The AI industry frequently concentrates on developing larger and more intelligent models, but deployment is another issue that affects whether AI can scale in real-world scenarios. If serving a powerful model necessitates costly infrastructure, high latency, and dedicated GPU resources for each specialized task, it is of little use.
This is where OpenLoRA from OpenLedger makes a difference.
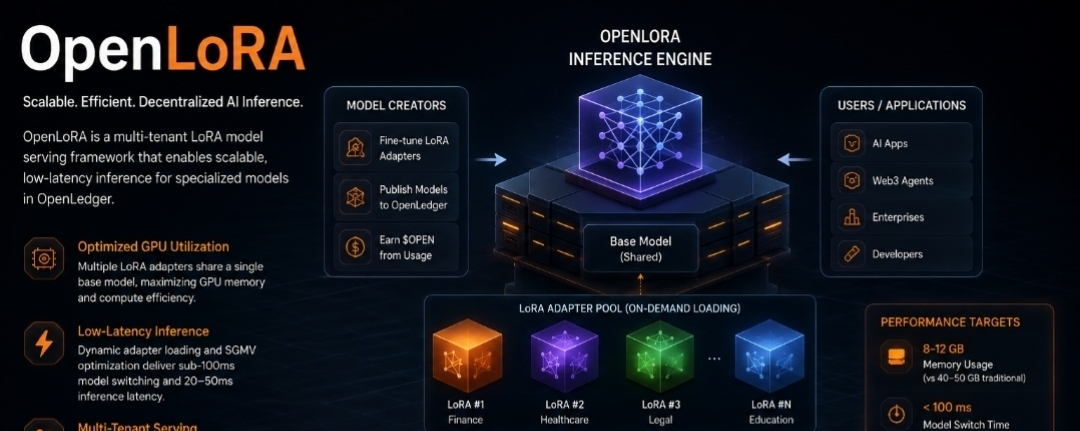
A multi-tenant LoRA model serving framework called OpenLoRA was created to provide low-latency, scalable inference for specialized AI models. OpenLoRA allows thousands of specialized models to share a common backbone model while dynamically loading only the necessary adapters, eliminating the need to deploy separate GPU instances for each refined model. This lowers operating costs and significantly increases efficiency.
The use of traditional AI frequently results in significant inefficiencies:
• Different models use different amounts of GPU memory.
• The cost of infrastructure rises with scale.
• There are delays when switching between specialized models.
• GPU resources are still underutilized.
OpenLoRA uses a number of significant innovations to address these issues:
GPU Infrastructure for Multiple Tenants
Rather than repeatedly loading entire models, multiple LoRA models share a single pre-trained backbone model. This increases computational efficiency while lowering GPU memory overhead.
Dynamic Loading of Adapters
Only when necessary are adapters loaded, and once inference is finished, they are unloaded. Cold-start delays are reduced and quick model switching is made possible by keeping the backbone model in memory.
Optimization of SGMV
For inference workloads, Segmented Gather Matrix-Vector Multiplication maintains optimal memory access patterns while facilitating effective batch execution.
GPU Scheduling with Intelligence
In order to maximize throughput and maintain balanced workloads across resources, requests are dynamically assigned based on available memory and batch requirements.
The performance goals are noteworthy:
• Memory usage: 8–12 GB as opposed to 40–50 GB in conventional deployment methods
• Switching between models takes less than 100 ms.
• Throughput: more than 2000 tokens per second
• Latency: roughly 20–50 ms
The fact that OpenLoRA is more than just an inference framework makes this particularly intriguing for decentralized AI. It creates a system where contributors may be compensated according to model usage and influence by integrating with OpenLedger's larger ecosystem, which includes Datanets and Proof of Attribution.The question "Who has the largest model?" may give way to "Who can deploy intelligence efficiently at scale?" as AI develops.According to OpenLoRA, smarter execution may be just as important to AI's future as smarter models.