很多人看@OpenLedger 只看代币价格,但我觉得这个项目今年最值得说的技术动作是它把数据可用性层接到了EigenDA上。这件事在主流加密媒体里基本没怎么被讨论,因为DA层听起来太底层、太枯燥,但你如果真的想搞清楚 #OpenLedger 能不能撑起它对外讲的那套AI数据基础设施叙事,DA层选哪家几乎决定了它未来三五年能走多远。
先说一下DA层是什么。AI模型训练用的数据动辄几十GB甚至几TB,这种规模的数据如果直接全部上链,成本高到没人用得起,所以所有正经做数据上链的项目都得做一件事,把数据本身放在链下存储,链上只保留一份可验证的索引和承诺。这套设计叫做数据可用性,缩写就是DA。DA层的核心要求是,任何时候有节点想要回查原始数据,都能可靠地把数据取回来,而且能验证它没被篡改过,这件事说起来简单做起来非常难,因为你既要保证存储成本足够低,又要保证可用性足够高,还要保证去中心化程度过得去。
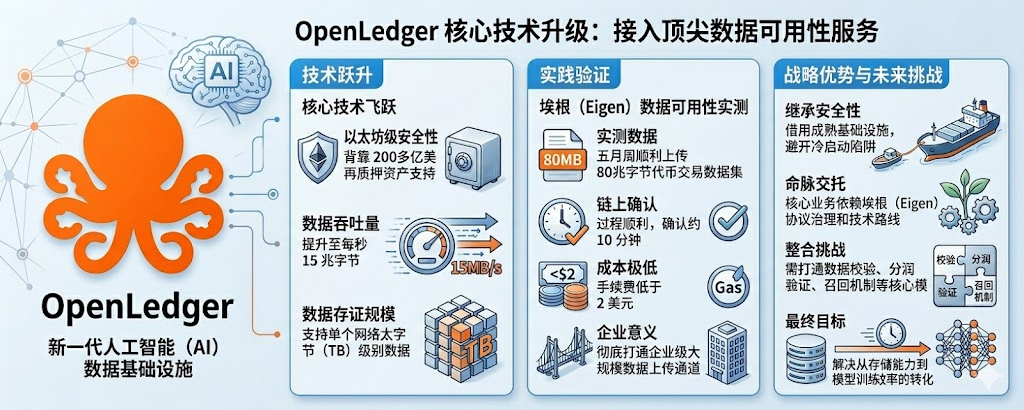
接EigenDA是一个挺关键的技术升级。EigenDA是EigenLayer的数据可用性服务,背靠以太坊主网的安全性和大约两百多亿美元的再质押资产,吞吐量上做到了每秒15MB级别,这个数字看着不大但对DA层来说已经是行业第一梯队了,跟Celestia比高出几倍,跟以太坊原生Calldata比更是差了两个数量级不止。OpenLedger接上EigenDA之后,理论上可以把单个Datanet的数据存证规模从几GB级别拉到几TB级别,这个跃迁直接决定了它能不能服务高质量的AI训练数据。
我五月这周做了一个小尝试,把一个大概80MB的代币交易数据集贡献到了$OPEN 的金融Datanet里,整个上传过程比我预期顺利,链上确认时间大概十分钟,Gas费折合不到两美金,这个体验在接EigenDA之前是做不到的,这是已发生的事实不是推断。这种成本和速度对个人贡献者来说基本无感,但对企业级数据贡献来说意义更大,因为企业一次贡献可能就是几十GB,如果还按以太坊主网的成本算,光Gas费就能把项目方劝退。
更深一层的意义在于安全性继承。EigenDA的安全性来自EigenLayer的再质押机制,本质上是把以太坊主网验证者的经济安全性租给了OpenLedger,这种安全继承的成本远低于OpenLedger自己搭建一套验证者网络。我以前看过几个项目尝试自建DA层最后失败的案例,自建DA最大的问题是冷启动期没有足够多的验证者,安全性根本撑不住,OpenLedger通过接EigenDA绕过了这个冷启动陷阱,等于站在以太坊的安全肩膀上做事。
EigenDA本身还在相对早期,主网上线时间不长,去年才开始承载大规模流量,整个再质押赛道的安全模型在学术圈还有争议,有研究指出再质押会导致以太坊主网的系统性风险增加,如果哪天EigenLayer出现重大安全事件,OpenLedger作为下游会跟着受影响。OpenLedger接入EigenDA之后等于把自己的命脉部分交给了EigenLayer的治理,未来费用调整、节点要求变化、技术路线调整都会直接影响OpenLedger的运营成本和服务质量。还有一点是技术整合的完整度,把DA层接上只是第一步,真正要让它服务于AI数据归因和分润,还需要在DA层之上把数据校验逻辑、Proof of Attribution的链上验证以及数据召回机制这几个模块都打通。
OpenLedger技术选型上做了一个挺聪明的决定,避开了自建DA的陷阱,借用了以太坊行业里最成熟的安全基础设施,这种选择短期内能让OpenLedger把更多资源放在AI数据归因这个核心业务上。OpenLedger接下来要解决的是怎么把EigenDA提供的存储能力转化成实际的AI模型训练效率提升,这件事光靠技术选型解决不了,还得在产品体验、开发者工具、企业BD这几条线上同时发力,缺一个都不行。