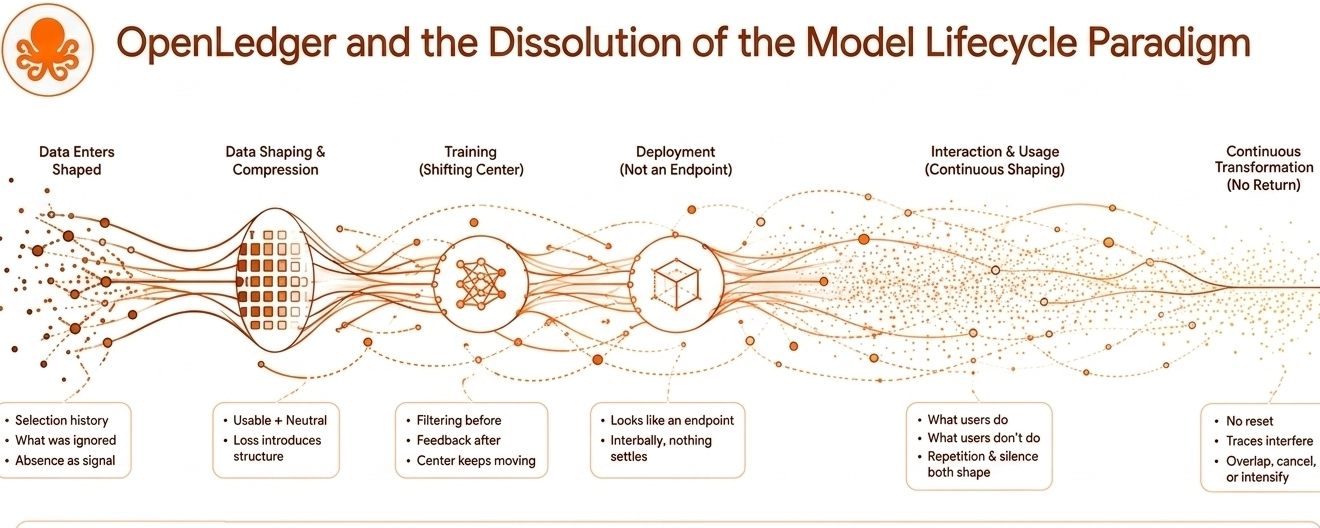

There’s a quiet assumption behind the way model lifecycles are usually described. As if systems move in steps that can be cleanly separated. Build, train, deploy. Then improvement. Then repetition. But when you look at infrastructures like OpenLedger for long enough, that sequence doesn’t stay intact. It starts breaking in small, almost unnoticeable ways. Not dramatic. Just enough that the structure stops feeling reliable.
A model is rarely in one condition at any given moment. Not fully training. Not fully deployed. Those labels exist, but the system doesn’t seem to live inside them. It moves across them depending on where pressure is applied.
And pressure is always there.
Data enters already shaped. That part is easy to miss if you assume neutrality at the start. But nothing arrives without history. What was chosen to be collected. What was ignored. What was too expensive or inconvenient to capture. Even absence becomes part of the input profile, just in a different form.
Then it gets compressed into something usable. Usable, not neutral. Those are not the same thing, even if systems sometimes behave as if they are.
Training is often treated like the center of the lifecycle, but that center keeps shifting when you trace what actually affects outcomes. Before training, there is already filtering. After training, there is already feedback. And that feedback does not wait for formal retraining cycles. It leaks back through usage, through repetition, through patterns of interaction that slowly tilt what the system becomes sensitive to.
At some point though even that phrase feels too clean deployment stops behaving like an endpoint. It looks like one from the outside, but inside the system nothing really settles. Usage becomes another layer of shaping. Not always direct. Sometimes it’s what users don’t do. Sometimes it’s the absence of edge cases. Sometimes it’s repetition narrowing what the system continues to respond to.
It becomes difficult to say where training ends and interaction begins. The separation still exists in design diagrams, but in practice it feels thinner, less useful as an explanation.
Roles inside this structure also don’t stay fixed. Data contributors, model builders, validators, users. The labels remain, but the actual flow doesn’t respect them cleanly. Inputs cross those boundaries constantly. Not in a balanced way. Not in a fair way. Just continuously, without waiting for permission.
Ownership becomes harder to locate in that environment. Not because it disappears, but because it spreads across transformations. A dataset does not remain itself for long. A model does not remain a fixed object either. What matters is what it becomes after passing through enough layers of adjustment that origin stops being the most relevant reference point.
And attribution follows the same drift. It doesn’t vanish it stretches.
Deployment is often described as stability, but stability is not really what appears. Interaction immediately begins reshaping behavior again. Not always through explicit updates. Sometimes through repeated patterns of use. Sometimes through silence. Sometimes through unexpected inputs that slowly recalibrate what “normal” looks like.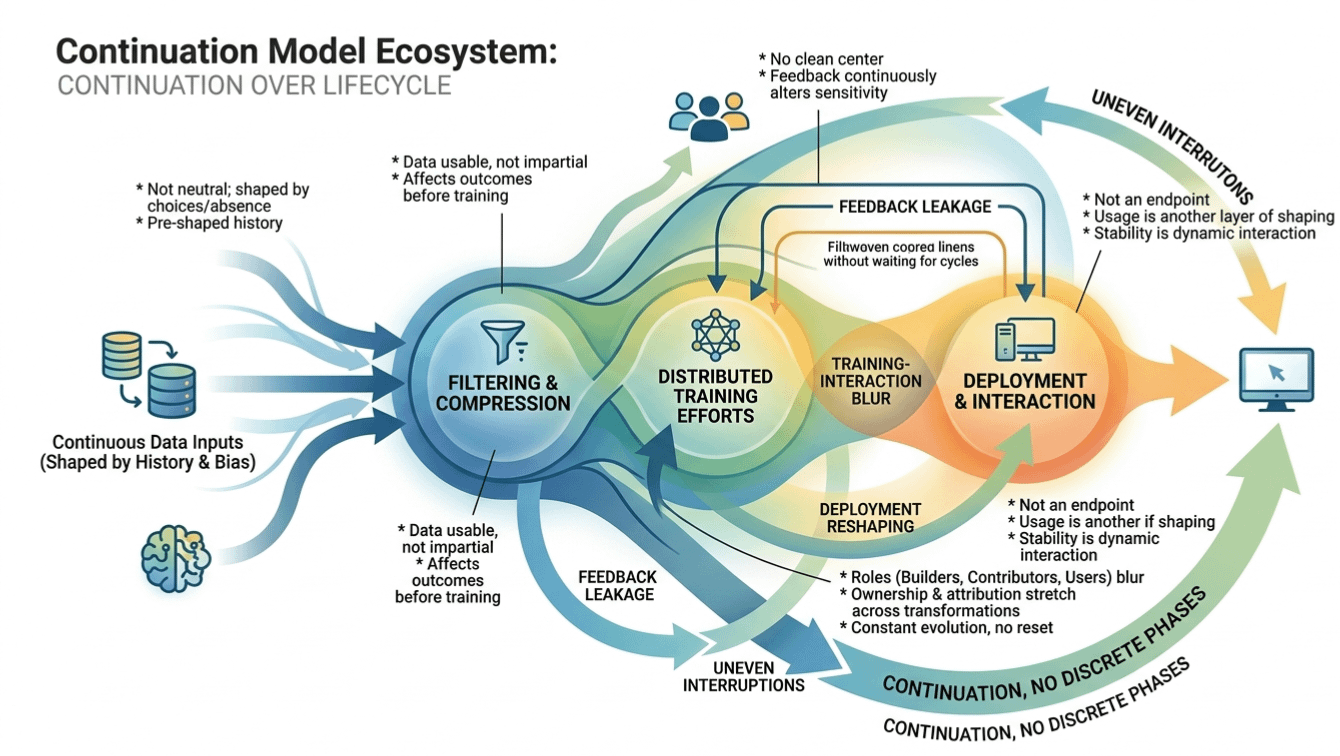
Even absence is not neutral here. What does not happen still leaves structure behind.
There is no return point in this system. No reset where conditions cleanly restore themselves. Each iteration leaves traces, but those traces don’t stack neatly. They interfere. They overlap. Sometimes they cancel out parts of what came before, sometimes they intensify it without intention.
The idea of a lifecycle starts to feel slightly misaligned with what is actually observable. Too orderly for something that doesn’t stay within its own phases.
Maybe it was never a cycle in the first place.
Just continuation, shaped by uneven interruptions, without a stable point where it can be said to have properly started or ended.
