
I've been in this space long enough to watch dozens of projects promise the perfect balance between openness and protection. You see the same cycle: a new chain launches with grand ideas about fixing what's broken in blockchain, raises some money, gets listed, and then... well, reality sets in. Users trickle in during the hype, developers poke around, and eventually many of them drift away when the day-to-day friction becomes too much. OpenLedger and its $OPEN N token sit in that familiar territory right now, especially with Phase 1 underway. I'm not here to cheer or dismiss it outright. I'm just turning it over in my mind, the way you do after seeing too many experiments play out.
Most blockchains start from a place of radical transparency. Every wallet address, every transaction, every smart contract interaction sits there forever, visible to anyone with a block explorer. That was the point in the beginning trust through openness, no single party controlling the ledger. It worked beautifully for early Bitcoin and Ethereum use cases where the goal was censorship resistance and verifiable scarcity. But as crypto moved toward more serious applications, that default visibility started showing its cracks.
Think about institutions or even regular people trying to do meaningful work. If you're handling real capital, sensitive datasets, or proprietary models, broadcasting every detail creates real problems. Competitors can watch your moves. Regulators or adversaries gain easy access to patterns. Personal or corporate privacy erodes in ways that feel permanent. We've seen it in DeFi exploits where on-chain history made attacks easier to plan. We've seen users hesitate to engage because their financial footprint becomes a public biography. For mainstream adoption, this exposure isn't just inconvenient it's a structural barrier. Serious money, whether from traditional finance or big AI labs, doesn't like living in glass houses.
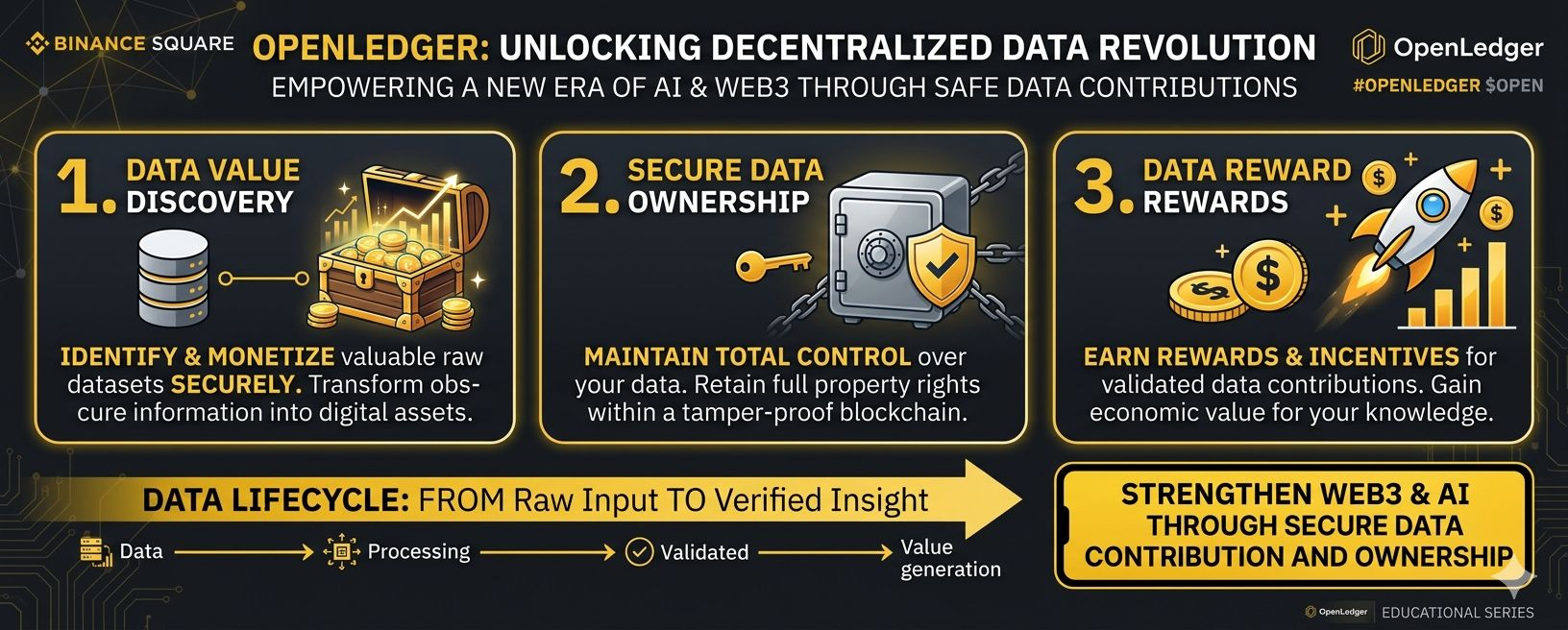
This is where projects like OpenLedger try to carve out something different. From what I've observed, it's built as an AI-focused infrastructure layer, using on-chain mechanisms like Proof of Attribution to track data contributions, model training steps, and usage. The idea isn't pure secrecy but a middle path: verifiability without full exposure. There are mentions of selective privacy tools and integrations with zero-knowledge approaches through partners, allowing proof that something happened (a dataset was used, a model performed as claimed) without revealing all the underlying details. In theory, this could let developers and users operate in regulated environments while still participating in decentralized networks.
It's an appealing middle ground on paper. Privacy by selective design rather than blanket transparency or total opacity. For AI specifically, where data provenance matters hugely both for fairness in rewarding contributors and for compliance it feels relevant. You can imagine a future where enterprises contribute to shared data pools without leaking competitive edges, or where individual creators get credited for their work without exposing their entire portfolio. Phase 1 seems focused on getting these foundational pieces live: mainnet stability, early developer tools, and testing how attribution flows in practice.
Yet here's where my skepticism kicks in, the kind that comes from watching elegant architectures meet messy reality. I've seen teams with strong technical designs and thoughtful tokenomics launch to initial excitement, only to struggle with actual usage. Complexity is often the silent killer. Zero-knowledge proofs and attribution systems sound clean in whitepapers, but they can introduce latency, higher costs, or learning curves that drive away all but the most dedicated builders. Will developers actually choose OpenLedger's environment over simpler, more established chains when deadlines loom? Or will they fall back to what they already know, even if it's imperfect?
Human behavior rarely matches the optimistic assumptions in roadmaps. Early curiosity brings testnet activity and some genuine experimentation, especially around AI agents and data monetization. But retention demands something deeper: seamless integration into real workflows, clear value that outweighs the risks, and enough network effects to make switching worthwhile. Many projects fade not because the core idea was wrong, but because the day-to-day experience felt awkward or the incentives didn't hold once the airdrop or listing hype cooled.
OpenLedger positions itself as infrastructure rather than another flashy narrative token. That's refreshing in a way. The focus on community-owned datasets ("Datanets") and payable AI through verifiable attribution shows they're thinking about sustainability beyond speculation. Backing from funds like Polychain and integrations with other protocols suggest some seriousness. Still, the deeper question lingers: does this privacy verifiability balance actually drive long-term adoption, or does it remain an appealing story that struggles when real economic pressure arrives?
Regulators continue tightening rules around data and AI. Enterprises demand auditability but also protection. Retail users want simplicity. In that environment, a chain that tries to thread the needle could carve out a meaningful nicheor it could get pulled in too many directions, satisfying no one fully. Phase 1 will tell us something about technical delivery, but the real test comes later, when usage patterns solidify and the initial participants decide whether to stay or move on.
I'm watching with cautious interest, the same way I've watched many others. OpenLedger and OPEN might represent a more grounded attempt at solving persistent tensions in blockchain, particularly for AI. Whether it leads to genuine retention and adoption remains an open question—one that time, actual usage, and market conditions will answer more honestly than any launch announcement ever could.
