I keep seeing the same old scene in crypto AI. Big claims. Big charts. Big words. Then you look under the hood and the engine is choking. That’s where @OpenLedger , OPEN, gets more fun to study. Not because it screams louder than the room. It doesn’t need to. The real story sits in a dry place most traders skip, the cost of knowing what changed inside a small AI model while it learns. Sounds boring. It isn’t.
Think of a chef tasting a soup after every spice drop. That’s fine in a home kitchen. Now picture a huge kitchen with a thousand pots, each one being changed each second. If the chef has to taste every pot, write notes, clean the spoon, and do the math by hand, dinner never comes out. That’s the old problem.
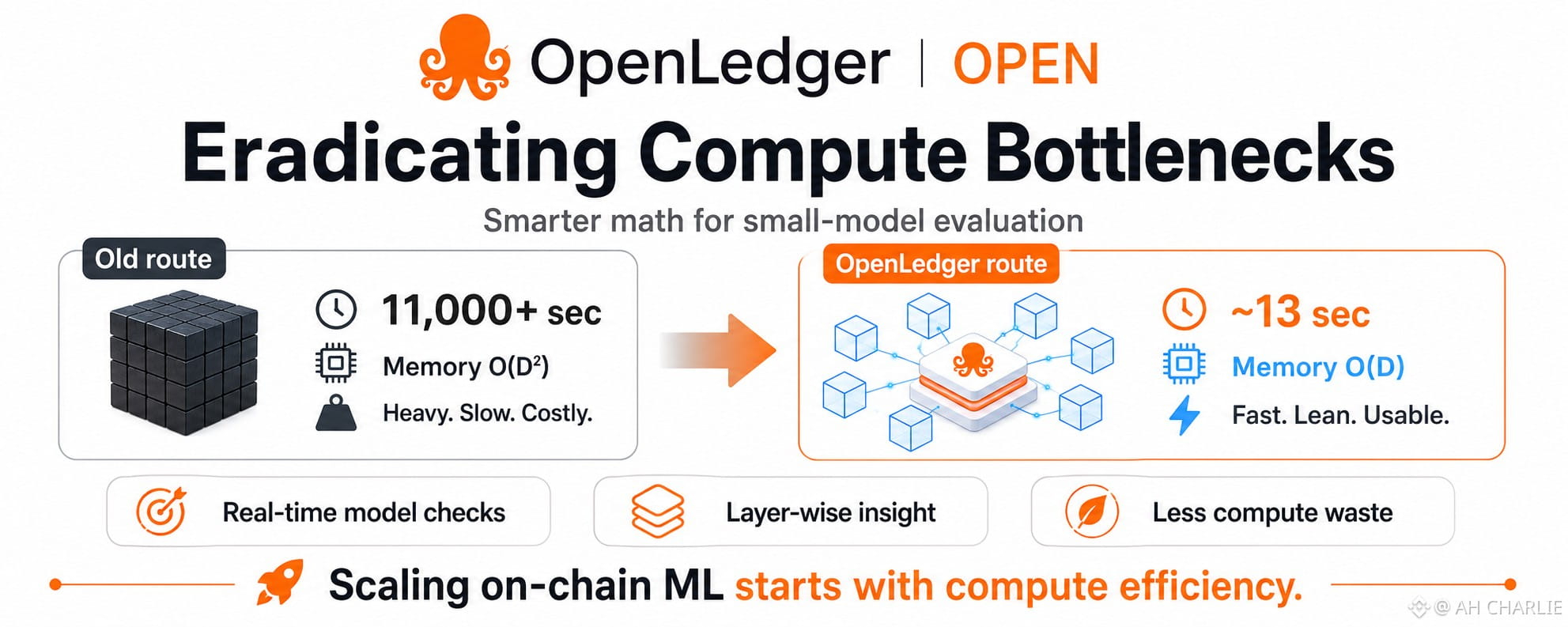
When a model learns, people want to know which part of the data moved the model, where it moved, and how much it mattered. The classic way tries to check the deep inner pull of the model with a giant math map. That map is heavy. Too heavy. It acts like a grand piano in a lift with weak cables.
I’ve watched this kind of math kill good ideas before. The idea works in a paper. It breaks when real users, real data, and real cost show up. The chart looks clean. The bill does not. OpenLedger takes a more hard-nosed path.

Instead of forcing one huge map to be flipped over, it takes many small views and turns them into a fast read. It’s like checking each receipt in a stack, then adding the result, not building a whole tax court for every coffee run. The standard way burns memory like a bad trade burns ego. As the model gets wider, the cost grows fast. It doesn’t just rise. It swells. It becomes the kind of hidden drag that makes a system sound smart in a pitch and feel dead in real use.

OpenLedger has been working around that drag with a closed form path made for small tuned models. In plain talk, it uses a math shortcut that avoids the worst part of the job. It keeps the useful view of what each layer is doing, but it cuts the grind down hard.
On a task like GLUE-QQP, the old route can take over 11,000 seconds. The faster route lands near 13 seconds. I don’t treat that as magic. I treat it as a smell test. If a system can turn a slow lab act into something close to real time, then it has moved from theory land into work land. And that’s where traders should pay attention.

Retail traders often chase the loud part of a story. Smart money tends to ask a colder thing, what breaks first at scale? In AI tied to chain use, compute breaks first. Then cost breaks. Then user trust breaks. It’s a row of glass doors, and the first crack spreads.
OpenLedger’s thesis, as I see it, is that you can’t scale model checks if the check itself costs too much. That sounds simple, but most projects dodge it. They talk like math is free. It isn’t. Every extra step has a cost. Every slow step adds delay. Every heavy step shuts out real use. This is why the small model angle is not small at all.
Small models are the dirt roads of AI. Not fancy. Not wide. But they get used. They can run closer to the user. They can be tuned for real work. They don’t always need a monster machine in the sky. Yet if you can’t track how they learn, you’re still driving with fog on the glass. OPEN tries to clear that glass.
I’m not here to call it clean or perfect. That would be lazy. The market doesn’t pay for nice words. It tests every claim with stress, time, and user demand. OpenLedger still has to prove that this math edge holds up outside neat test beds. It has to show that speed does not turn into blind spots. Faster is good only if the view stays sharp.
It feels less like a poster and more like a wrench. A tool. A thing made because someone hit the wall and got tired of walking around it.
Most people see AI and think bigger. Bigger data. Bigger model. Bigger machine. OpenLedger asks a more brutal question. What if the win is not bigger, but less dumb work. That is not a soft point. That is the whole point.
In markets, waste hides until stress finds it. In tech, waste hides until users arrive. In AI systems, waste hides inside math until the bill comes due. OPEN’s most real edge is not the theme. It is the cut. The cut in time. The cut in memory. The cut in dead weight. If that keeps holding, it gives OpenLedger a path that feels more grounded than most AI names that float on vibes.

I don’t care how elegant an AI system sounds if it can’t run without choking. OpenLedger is interesting because it attacks the choke point first. That is rare. That is practical. And in a market full of story dust, practical can age better than hype.
So the question I keep coming back to is this... If intelligence keeps getting cheaper, faster, and closer to the edge, who owns the future, the ones with the biggest machines, or the ones who waste the least? Study OPEN through the lens of compute, not noise. What do you think about the efficiency of this?
