

I was reading an AI-generated output last week. Standard marketing copy, nothing remarkable. And I kept thinking about the same thing I always think about when I read AI output now:
where did the training data come from?
Who wrote it originally?
Where did that person's compensation go?
Nowhere. Nobody tracked it. There's no ledger. There's no mechanism. The writer got nothing and the model got everything and that's just how it works.
That's the starting problem for OpenLedger. Not the exciting part. The boring part.
Proof of Attribution. That's the layer most people skip in their read-through of the OpenLedger thesis. Payable AI is the concept that gets quoted. Contributors get rewarded when their data influences a model's output. Automatic. On-chain. Clean. That's the pitch. That's the part that fits in a tweet.
But the pitch assumes the attribution layer works. And attribution is deeply unglamorous. It's data provenance. It's lineage tracking. It's asking four uncomfortable questions before you even get to payment. Who contributed what data?
To which model?
When?
And how much did that specific contribution influence the specific output?
Four problems. Each one non-trivial. Most projects never actually solve them. They announce a contributor economy, generate good content about it, and figure out the attribution mechanics later. Or they don't build them at all. Or they hand-wave through the hard parts.
I don't know which category OpenLedger falls into yet. That's not a dismissal. It's just honest.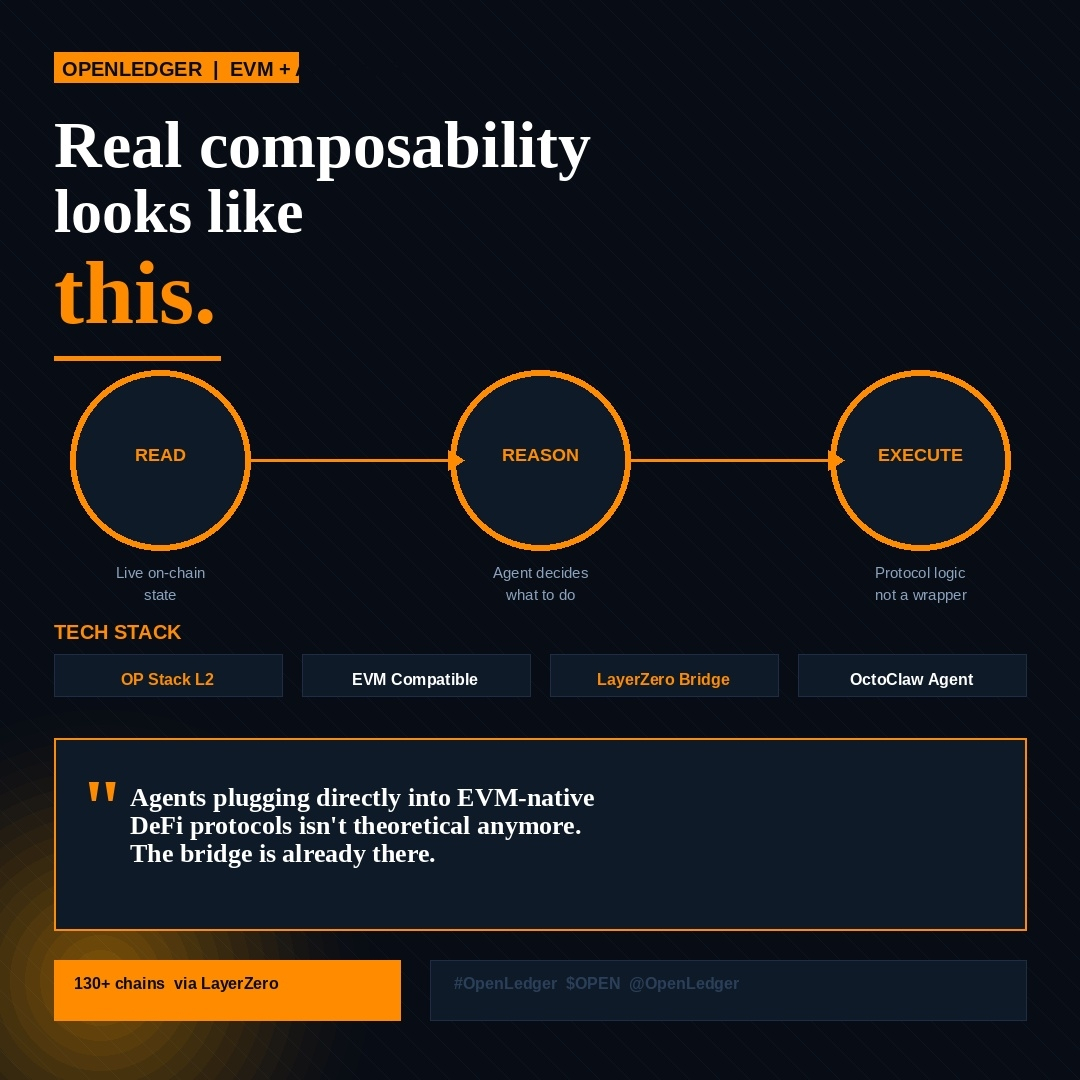
Here's what I keep circling back to. How do you quantify influence at the data level? What's the minimum contribution threshold to qualify for attribution? Can bad actors game the provenance mechanism? What happens when two contributors submit functionally identical data?
And what happens when model outputs synthesize thousands of training sources so thoroughly that tracing any single input becomes computationally or economically unworkable?
These aren't rhetorical. They're hard engineering problems. The kind that produce whitepapers, not press releases.
The OpenCircle Launchpad adds pressure. $25M committed to fund builders in the ecosystem. Builders will build things that depend on the attribution layer underneath them. If the provenance mechanism has gaps, every product built on top of it inherits those gaps. That's not a startup risk. That's a systemic risk for the whole ecosystem.
This is a system design problem wearing the clothes of an economic thesis. Payable AI is what you see in the front end. Attribution infrastructure is what has to work quietly before any of it functions. The order matters. Build the wrong layer first and the whole thing is theater. Incentive theater with a very polished deck.
Capital in Web3 flows toward demos. Toward visible things. Toward the exciting layer. Infrastructure gets funded reactively, usually after something fails publicly and takes real money down with it. That's not cynicism. That's pattern recognition.
I believe the Payable AI thesis is directionally correct. Contributor economies will happen. Value will eventually route back to data creators. The macro logic holds and I actually think it's one of the more coherent theses floating around in this space right now.
But I keep coming back to the boring middle. The attribution ledger. The provenance mechanism. The part that has to work quietly and correctly before any of the economic promises become real. Nobody's writing long threads about data lineage. The conference talks are about the vision. Not the plumbing. The plumbing is unglamorous. The plumbing doesn't clap.
The original question isn't "will AI become payable?" It will, one way or another, regardless of whether OpenLedger wins or loses. The question is whether the attribution infrastructure gets built with the same rigor as the economic narrative around it. Whether the boring layer gets the same resources and attention as the exciting one.
Still no answer. That discomfort isn't going anywhere.
