was digging into how openledger handles data attribution and decentralized AI infra, and honestly the surface narrative feels too simple. most people seem to frame it as ai + crypto token + data marketplace. but when you actually trace the mechanics who contributes data who trains models who pays who earns it's more layered than that. and also more fragile.
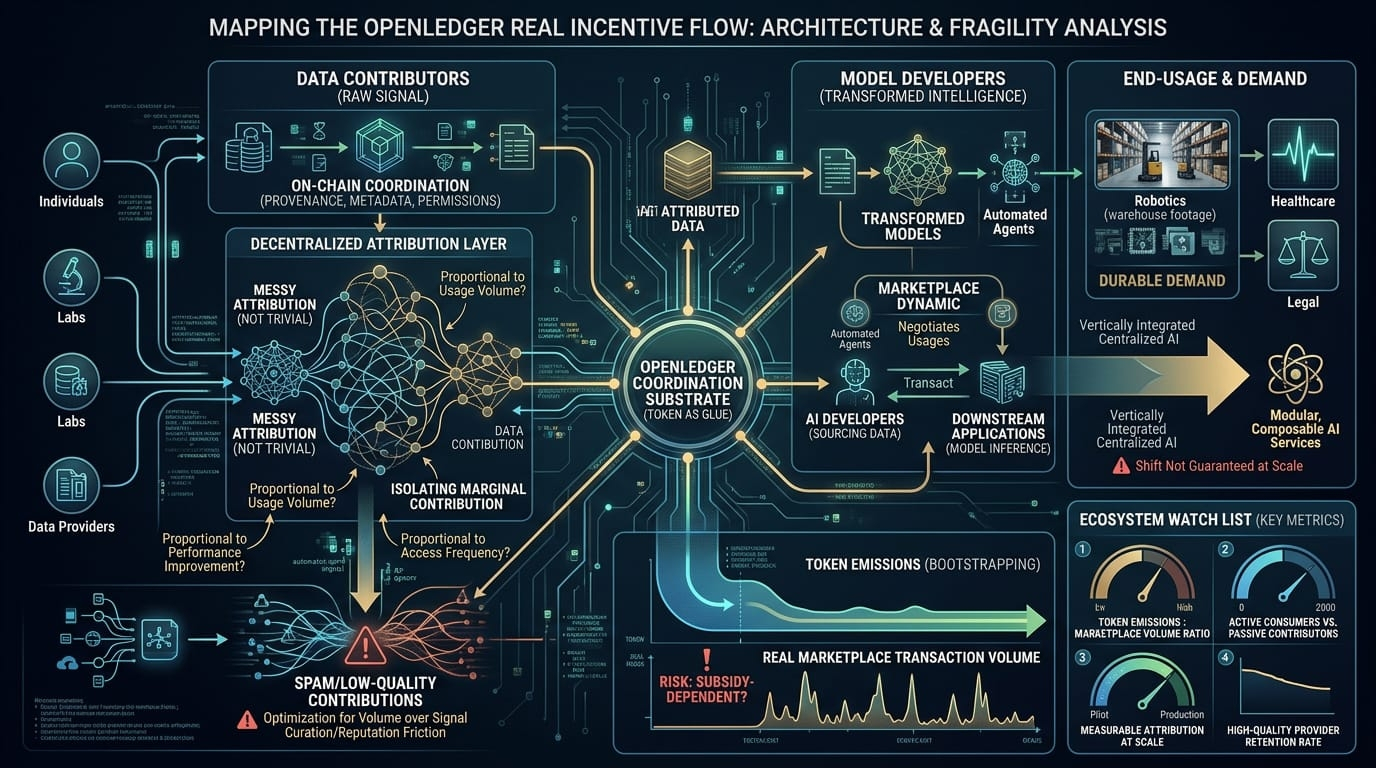
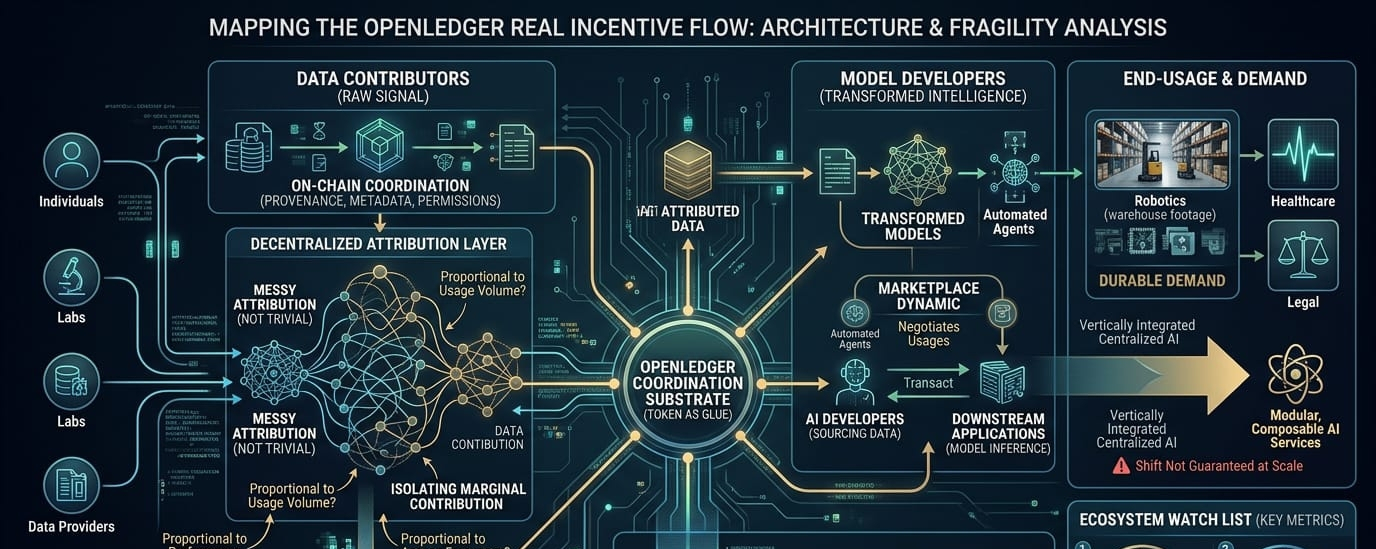
what caught my attention first was the decentralized data contribution system. openledger positions contributors (individuals small labs data providers) as first class economic actors. instead of centralized scraping or proprietary pipelines the protocol coordinates datasets on chain with metadata ownership records, and usage permissions. in theory this flips the model data isn't silently absorbed into a corporate training set it's explicitly contributed and attributed.
but the key question is whether that attribution layer can actually hold up. attribution in AI training is messy. models blend signals from millions (or billions) of samples. isolating marginal contribution is not trivial. openledger seems to rely on cryptographic provenance + usage tracking + potentially model level accounting mechanisms. still, and this is the part i keep thinking about how granular can attribution really get? if a model fine tunes on 50 different datasets are rewards proportional to usage volume? model performance improvement? access frequency? there’s an implicit assumption that contribution can be measured fairly.
then there's the marketplace dynamic. datasets and models are supposed to transact through the protocol AI developers sourcing data downstream applications paying for model inference maybe even automated agents negotiating usage rights. on paper this connects AI production directly with on chain economic coordination. instead of static licensing you get programmable usage terms.
but who actually creates value here?
data contributors create raw signal. model developers create transformed intelligence. end users create demand. the token sits in the middle as coordination glue. the system only works if all three sides scale somewhat simultaneously. if data floods in but model demand is weak token rewards inflate without real usage backing them. if model demand spikes but high quality data is scarce the marketplace becomes shallow.
i also wonder about spam and low quality contributions. any tokenized data incentive system faces this. if rewards are distributed for contribution events contributors may optimize for volume over signal. openledger likely has curation staking or reputation layers but those introduce governance friction. someone (or something) must adjudicate quality. fully automated validation seems optimistic unless the protocol relies heavily on model performance benchmarks as feedback loops.
another architectural assumption sustained demand for decentralized AI infrastructure. right now most AI development remains vertically integrated. centralized providers control compute data pipelines deployment and billing. openledger's model presumes a shift toward modular composable AI services where developers actively seek alternative data sources and attribution guarantees. that may happen especially in domains like healthcare or legal data where provenance matters but it's not guaranteed at scale.
token incentives are the other tension point. early networks often bootstrap with emissions. the bet is that usage eventually replaces inflation as the primary reward driver. but will real AI workloads generate enough economic throughput to sustain contributor payouts? or does the system risk becoming subsidy-dependent? i haven’t seen clear evidence yet that marketplace volume matches emission velocity.
a realistic example imagine a robotics startup sourcing specialized vision datasets through openledger warehouse footage edge case object interactions rare lighting conditions. they fine tune a perception model and deploy it commercially. ideally each dataset contributor receives proportional rewards tied to model licensing or inference usage. that's elegant in theory. in practice attribution math enforcement, and cross chain payments get complicated fast.
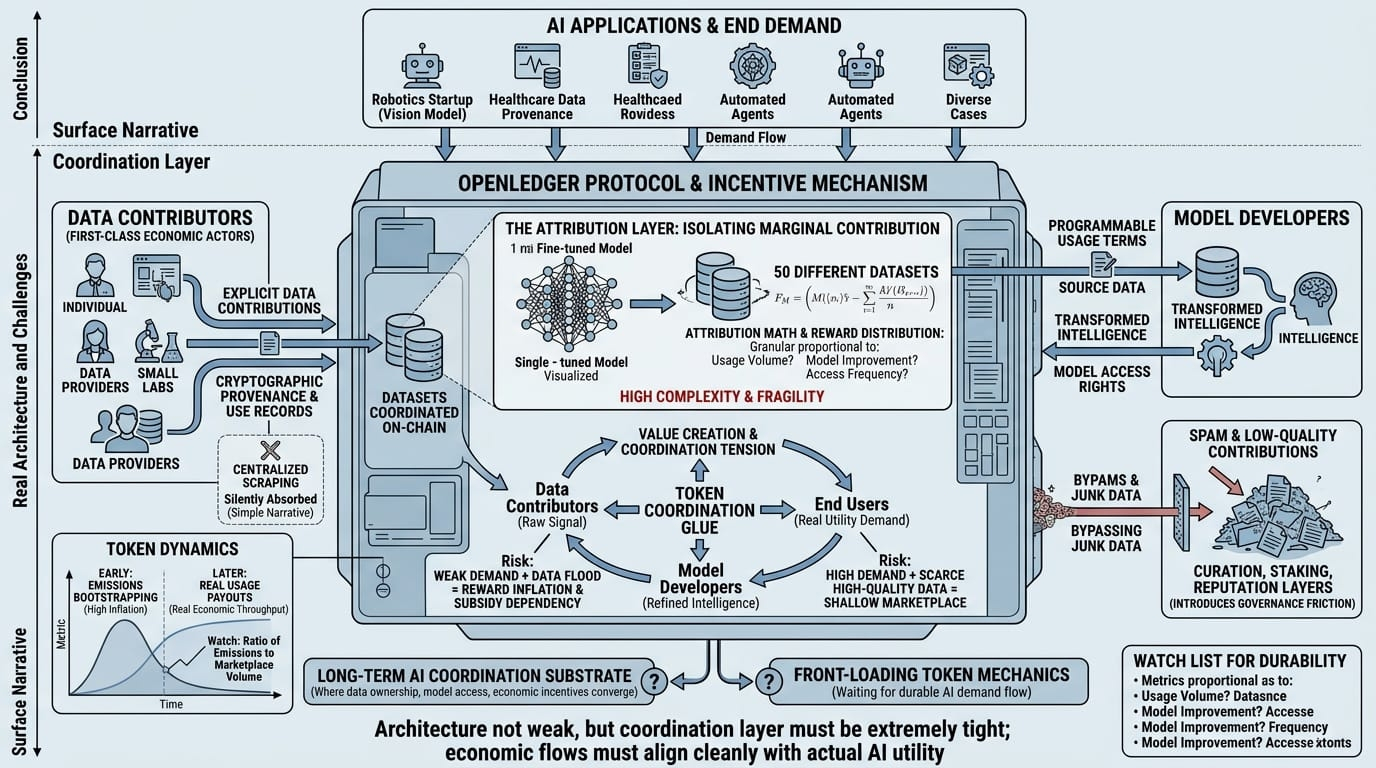
none of this makes the architecture weak it just means the coordination layer has to be extremely tight. cryptographic provenance alone isn’t enough; economic flows must align cleanly with actual AI utility.
so i'm left in a kind of suspended judgment. openledger could be building a long term AI coordination substrate where data ownership model access and economic incentives converge. or it could be front loading token mechanics before durable AI demand flows through the rails.
watching;
ratio of token emissions to marketplace transaction volume
number of active model consumers vs passive data contributors
evidence of measurable attribution at scale (not just pilot cases)
retention rate of high quality data providers over time
i'm mostly trying to understand whether this becomes infrastructure people quietly rely on or a well designed incentive loop waiting for demand that may or may not materialize. the architecture is interesting. the timing is less certain.