Pavadījis vairāk laika pētījumos@OpenLedger arhitektūrā, domāju, ka daudzi cilvēki joprojām skatās uz projektu no nepareizā leņķa. Galvenā ideja varbūt nav AI ģenerācija pati par sevi, bet infrastruktūra, kas nepieciešama, lai padarītu AI datus ekonomiski atbildīgus.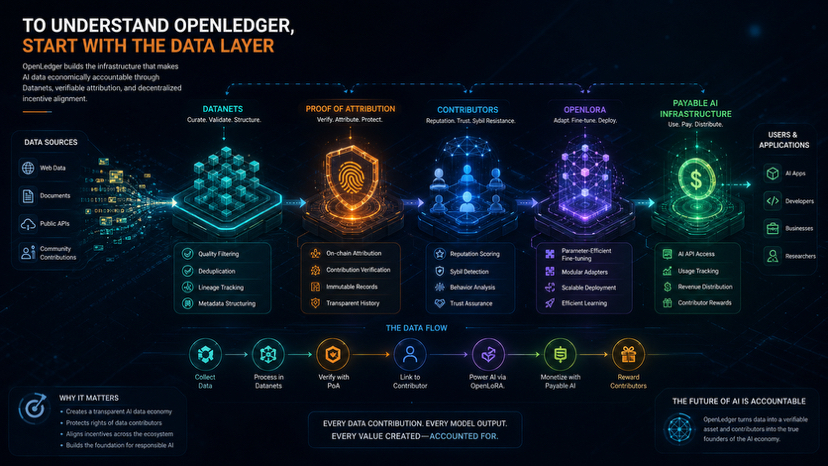
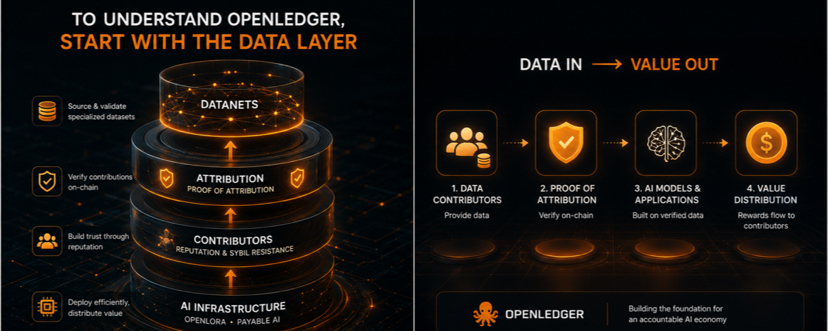
Mūsdienu AI sistēmas joprojām lielā mērā paļaujas uz milzīgiem datu kopumiem, kas savākti bez caurredzama atribūcija. OpenLedger izskatās, ka pie tā pieiet citādi caur Datanets un Proof of Attribution, kur datu kopumi, līdzdalībnieki un modeļu rezultāti var tikt saistīti iekšējā mērāmā on-chain struktūrā.
Kas padara šo interesantāku, ir izpildes plūsma aiz tā. Tā vietā, lai tikai teorētiski runātu par decentralizētu AI, ekosistēma pakāpeniski savieno vairākas kārtas kopā:
• Dataneti, lai iegūtu un validētu specializētus datu kopumus
• Līdzdibinātāju reputācija un Sybil pretestības mehānismi
• OpenLoRA, lai nodrošinātu mērogojamu modeļu izvietošanas efektivitāti
• Maksājams AI infrastruktūra vērtības sadalei, kas saistīta ar AI lietošanu
Ja kāds vēlas dziļi izpētīt OpenLedger, es domāju, ka labākais piegājiens nav sākt ar tokenu diskusijām, bet gan saprast, kā dati plūst visā ekosistēmā:
Kas sniedz datus?
Kā tiek verificēta atribūcija?
Kā ieguldījums galu galā var kļūt par izmērāmām ekonomiskām vērtībām?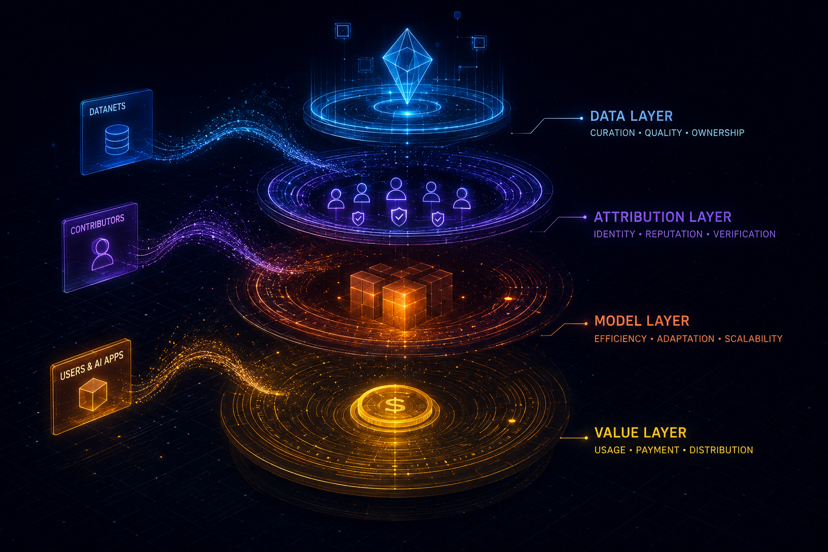
Tas var galu galā kļūt par vienu no svarīgākajiem jautājumiem nākotnes AI ekonomikā.
