Everybody still talks about AI like we’re in 2023 and the only variable that matters is how many H100s you can chain together before your competitors do. Every funding deck turns into the same conversation eventually: bigger clusters, bigger context windows, more parameters, more training runs, more capex. There’s this implicit assumption that model quality will keep scaling cleanly if you just keep feeding the machine enough compute.
For a while, honestly, that assumption held up well enough that nobody questioned it too hard. GPT-2 to GPT-3 was a real shift. You could feel it immediately in production workloads, not just on eval charts. Same thing with early multimodal systems. Suddenly models could parse images without acting completely deranged half the time, and that changed product planning almost overnight.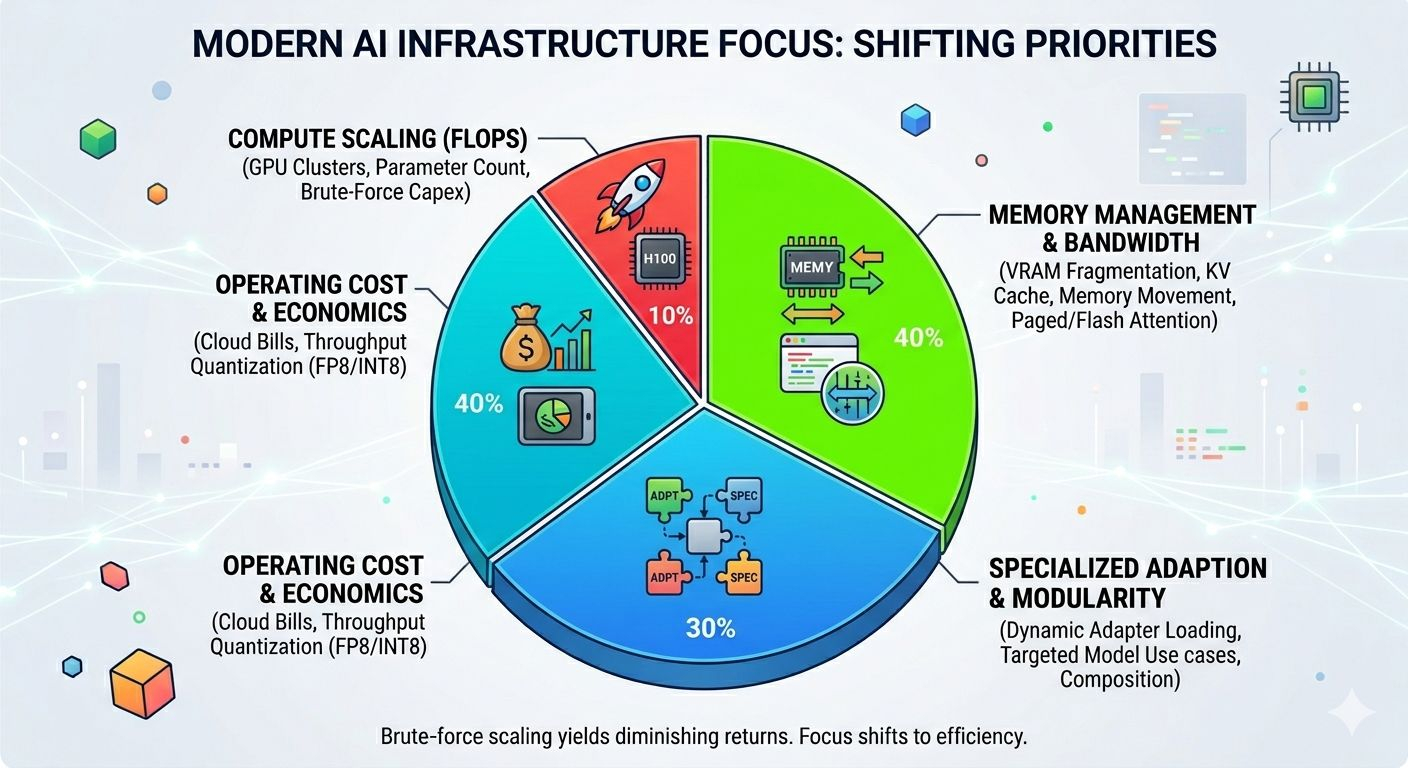
But lately the returns feel different. Not nonexistent. Just... narrower. More expensive. Harder to justify once you’re the person staring at utilization dashboards instead of benchmark screenshots.
The ugly part of this industry starts after training finishes anyway. That’s where the marketing material stops being useful.
Inference at scale is mostly a resource management problem disguised as AI research. You spend less time thinking about “intelligence” and more time trying to stop memory pressure from wrecking tail latency during traffic bursts. CUDA allocators start fragmenting VRAM after long-running sessions. KV cache growth turns into a mess once users start hammering large context windows concurrently. One noisy tenant or badly tuned deployment can destabilize an entire inference pool if your scheduling layer is sloppy enough.
And then there’s the cloud bill. Which nobody from the “we’re building AGI” crowd ever seems particularly eager to discuss in public.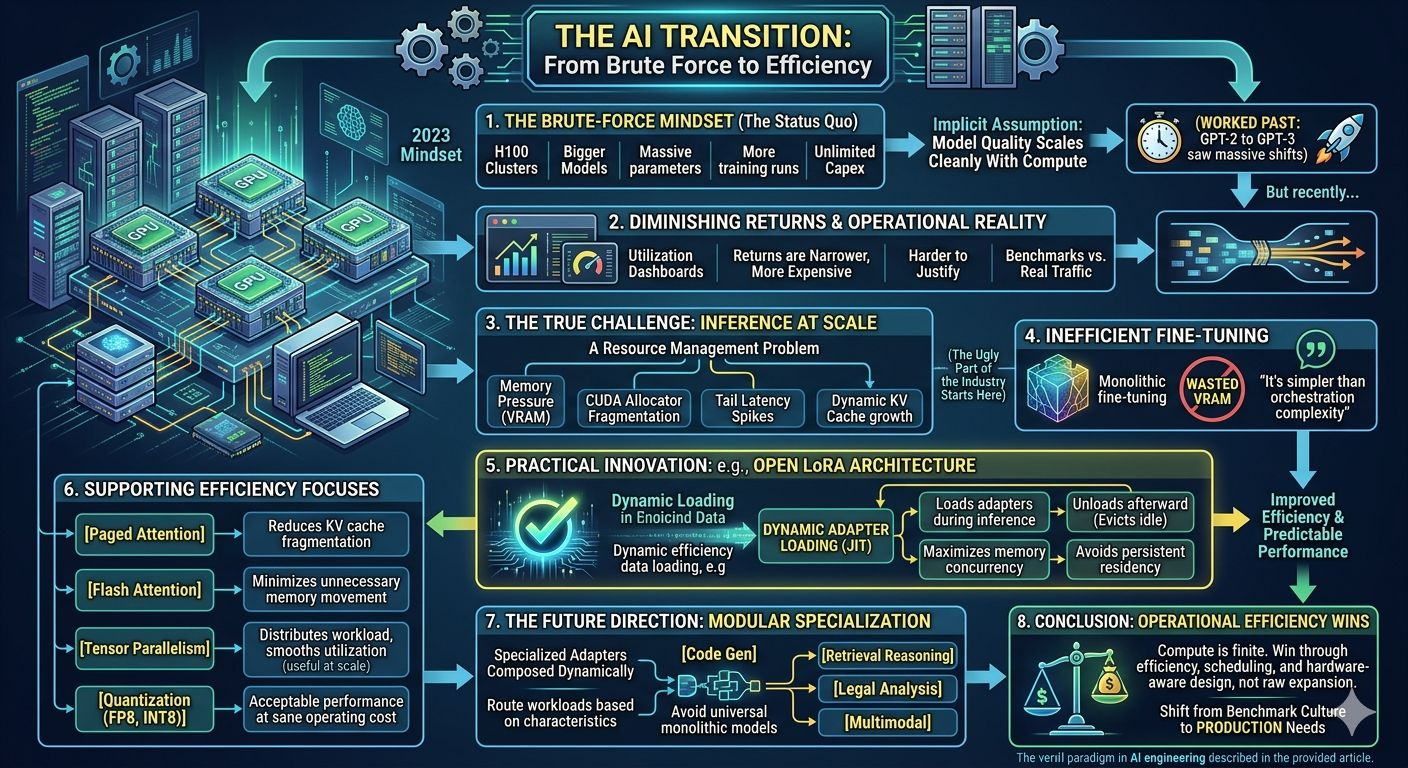
A lot of current fine-tuning infrastructure still feels strangely wasteful when you inspect the actual serving path. LoRA was supposed to make adaptation lightweight, but in practice plenty of systems still end up dragging huge model variants into memory because operationally it’s simpler than dynamically managing adapters correctly under load. So teams burn VRAM to avoid orchestration complexity, which works right up until concurrency rises and suddenly you’re capacity constrained on GPUs that already cost more than half your infra budget combined.
That’s honestly the first thing I noticed looking through Open LoRA’s architecture. It’s not pretending to reinvent transformers or publish some mystical roadmap to AGI. Most of the engineering focus seems aimed at serving efficiency, which immediately makes it more interesting to me than half the AI infra startups currently flooding Twitter with cinematic product demos.
The dynamic adapter loading approach especially makes sense if you’ve actually spent time operating inference systems instead of just benchmarking them in isolated environments. Keeping every adapter resident in VRAM is fine in controlled demos. Real traffic ruins those assumptions fast. Different request patterns arrive simultaneously, sequence lengths fluctuate unpredictably, and suddenly memory residency becomes a scheduling problem rather than a static deployment decision.
So instead of permanently pinning adapters into GPU memory, Open LoRA loads what it needs during inference and unloads afterward. That sounds minor until you’ve watched GPU memory slowly disappear over several hours because stale allocations never got cleaned up properly and now allocator fragmentation is tanking throughput. People underestimate how quickly inference servers degrade once memory behavior gets messy. Performance cliffs don’t arrive gradually either. Everything looks stable, then P99 latency detonates in fifteen minutes and your autoscaling layer starts making terrible decisions.
The JIT adapter loading layer is probably the most practical part of the system. It treats adapters less like permanent model state and more like dynamically scheduled resources. Honestly it reminds me more of operating systems work than ML research sometimes. Pull resources in when required, evict aggressively when idle, avoid unnecessary residency, minimize contention. Pretty basic principles conceptually, but applying them cleanly to inference pipelines is harder than people admit.
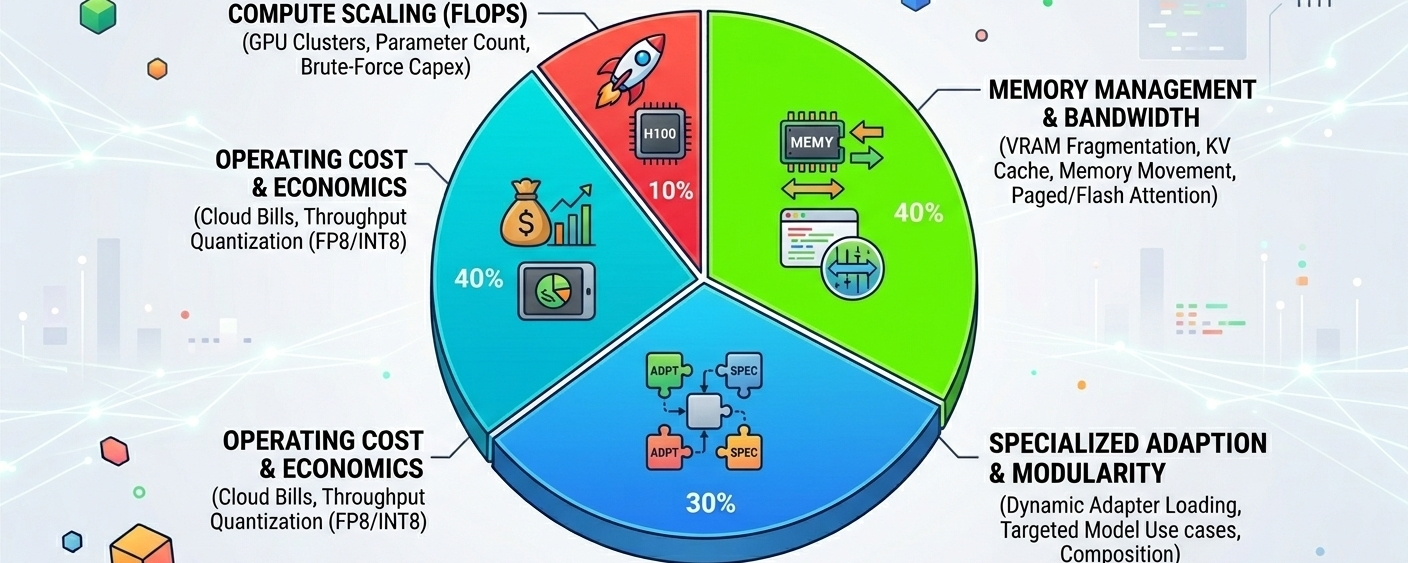
A lot of AI infra conversations still obsess over FLOPS while quietly ignoring bandwidth constraints and memory behavior, which is funny because memory movement becomes the dominant problem much sooner than most people expect. Especially with larger contexts.
Tensor parallelism falls into that category too. The term sounds academic enough that people mentally file it away as “deep learning optimization stuff,” but operationally it’s straightforward: a single GPU eventually becomes the bottleneck no matter how expensive it is. Throughput collapses once request concurrency climbs high enough. So you distribute the workload across devices to smooth utilization and reduce latency spikes under load.
At small scale, you barely notice the difference. At large scale, tiny inefficiencies compound so aggressively they start dictating architecture decisions. A few extra milliseconds during attention operations. Slightly worse cache locality. Poor batching behavior. Some allocator inefficiency nobody cared about during testing. Then traffic ramps and suddenly inference cost per request jumps hard enough that finance starts asking uncomfortable questions during planning meetings.
That’s also why Paged Attention ended up mattering so much. Long-context serving creates nasty fragmentation issues because KV caches become increasingly chaotic over time. Users never see the underlying allocator behavior directly, obviously. They just notice that responses get inconsistent, latency fluctuates randomly, or certain workloads degrade after servers have been alive for a while.
The optimization itself isn’t glamorous. It reorganizes how memory pages are handled during inference so the cache behaves more predictably and fragmentation becomes manageable instead of pathological. Cleaner allocation patterns, less wasted memory bandwidth, better stability under sustained load. Boring infrastructure work, basically. Which usually means it’s important.
Same story with Flash Attention. People still talk about transformer scaling like raw compute is the dominant constraint, but memory bandwidth becomes the real limiter surprisingly fast once sequence lengths expand. Flash Attention works because it reduces unnecessary memory movement and keeps operations closer to fast memory instead of constantly shuttling tensors around like a badly optimized distributed database query.
None of this stuff produces flashy keynote moments. But it changes operating margins. And eventually operating margins decide which systems survive.
I also think the industry’s long-term direction is probably more modular than people currently want to admit. Right now everybody still frames models as giant monolithic entities that should somehow become universally good at everything simultaneously — reasoning, coding, legal analysis, biology, finance, support tickets, document parsing, whatever. Economically that model feels shaky already, and inference costs get uglier the more generalized the system becomes.
More likely you end up with specialized adapters composed dynamically based on workload characteristics. One optimized for code generation. Another tuned for retrieval-heavy reasoning. Maybe lightweight routing systems deciding which adapters activate depending on prompt structure, latency targets, hardware availability, or even current GPU pressure inside the cluster.
Not because it’s philosophically elegant. Mostly because serving giant fully-loaded models for every request is expensive in ways that stop making sense once scale becomes real.
Quantization is pushing toward the same reality from another direction. FP8, INT8, lower precision inference generally — the goal isn’t academic perfection. It’s acceptable performance at sane operating cost. Most users genuinely do not care whether your model scores marginally higher on some benchmark suite if the system is slow, inconsistent, or too expensive to deploy widely.
The infra side of the industry understands this already. The public AI discourse mostly doesn’t.
You can feel the gap widening between people building production systems and people treating model releases like sports events. One group cares about throughput stability, cache efficiency, scheduling behavior, memory residency, kernel optimization, interconnect bandwidth. The other group posts leaderboard screenshots and argues about whether one model is “smarter” than another because it solved three additional math problems on a benchmark dataset.
Meanwhile the actual production teams are sitting there trying to figure out why NCCL communication overhead just spiked during peak traffic.
That’s why projects like Open LoRA are interesting to me. Not because they’re promising magical new intelligence. Mostly because they’re acknowledging the obvious constraint the rest of the industry keeps trying to talk around: brute-force scaling gets economically ugly very fast.
Compute is finite. Power availability is finite. GPU supply chains are definitely finite. At some point you stop winning through raw expansion and start winning through efficiency, scheduling, memory management, and hardware-aware system design.
Honestly, that transition already started. Most people just haven’t noticed yet because benchmark culture is still drowning everything else out.


