I’ve been in crypto long enough to recognize when a narrative starts getting recycled faster than the infrastructure behind it can mature. AI is in that phase right now.
Every week brings another “intelligent” protocol, another autonomous agent framework, another decentralized data marketplace, another chain claiming it will become the coordination layer for machine economies. The language changes slightly, but the structure stays familiar. Raise attention. Attach incentives. Accelerate growth metrics. Hope adoption arrives before the narrative cools down.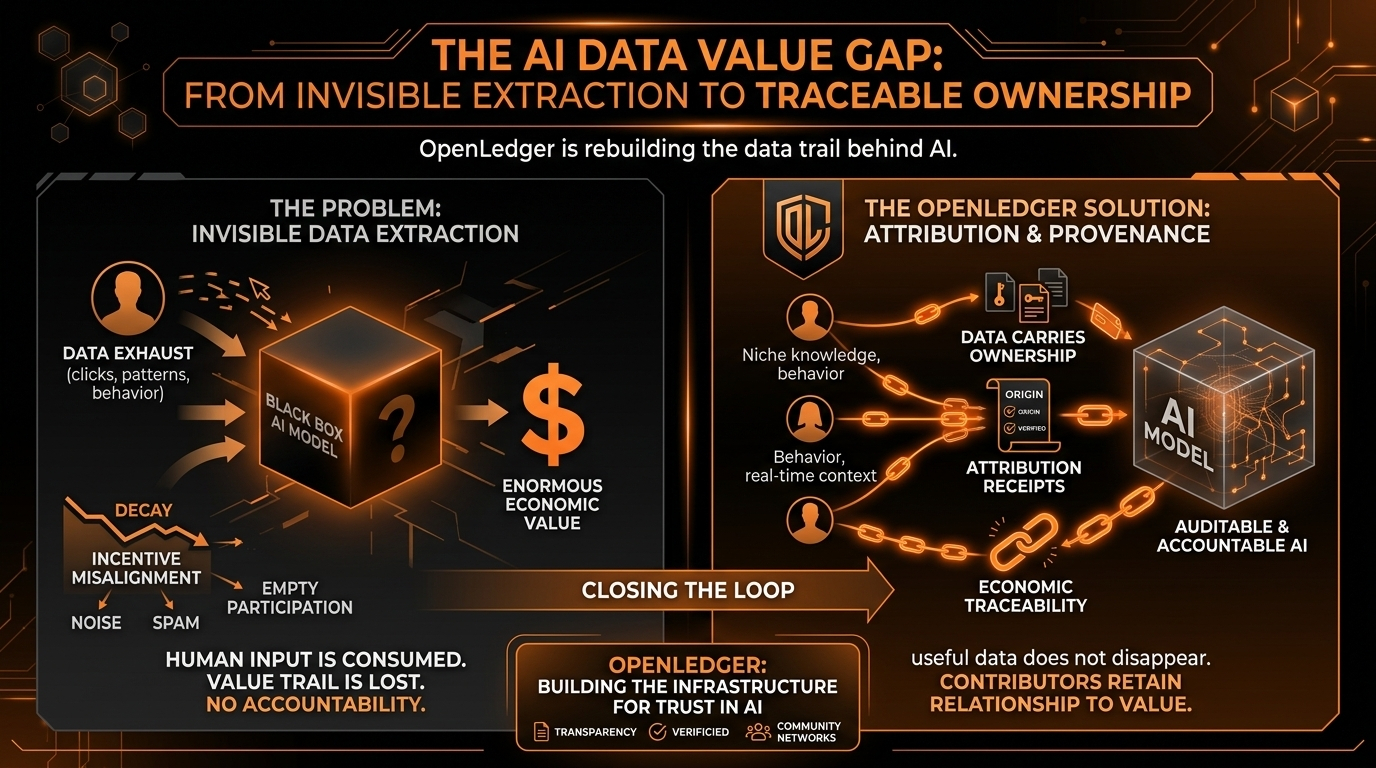
Most of the time, the market moves on before the hard questions ever get answered. That is why OpenLedger caught my attention for a different reason.
Not because it claims to connect AI and crypto. That alone means almost nothing anymore.
What interests me is the specific problem it is aiming at: the disappearing value trail behind data. And honestly, I think that problem is going to become one of the biggest economic fights of the AI era.
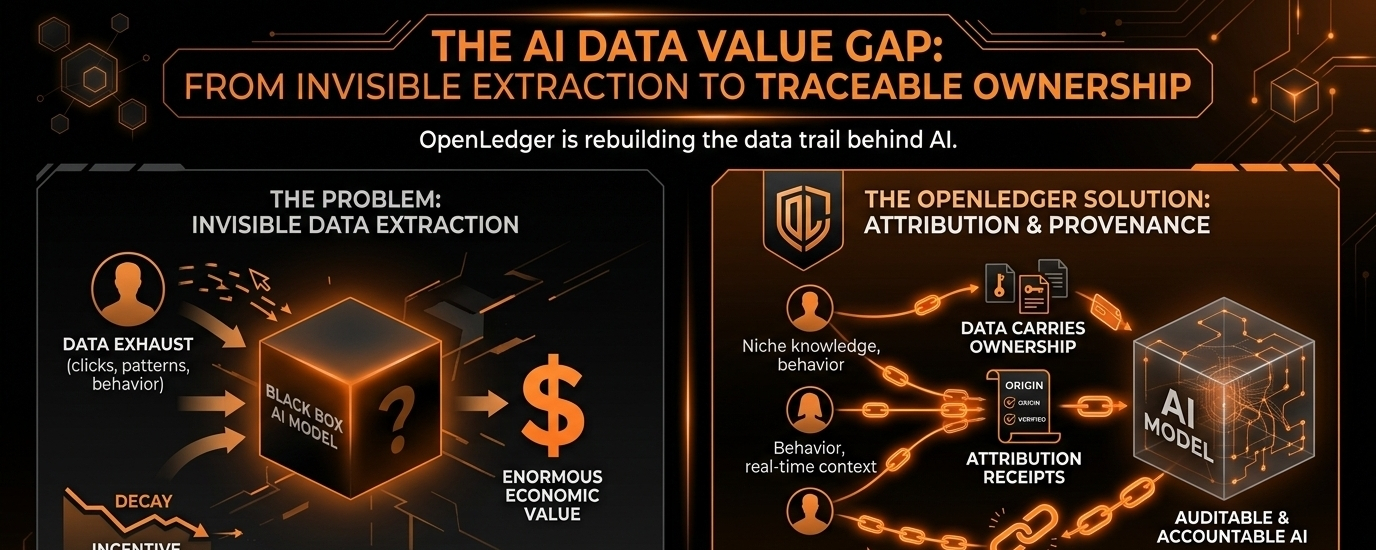
The internet spent years teaching people to give away value for free. Every click, conversation, preference, search, review, pattern, and behavioral signal became raw material for platforms. Most users never thought about it because the exchange felt invisible. You got convenience, entertainment, or access, while companies collected the underlying data exhaust quietly in the background.
AI changed the scale of that extraction completely.
Now those signals are not just supporting ad targeting systems. They are feeding models. Training agents. Shaping automated decision-making systems. Powering recommendation engines. Influencing financial tools. Creating synthetic intelligence layers that can generate enormous economic value from human contribution.
And yet the people producing the raw inputs still mostly disappear inside the process. That is the crack OpenLedger is trying to address.
The project keeps circling around a simple but extremely difficult idea: what if data carried ownership, attribution, and economic traceability before it became absorbed into AI systems?
At first glance, that sounds straightforward. It is not.
Because data is messy in ways most crypto incentive systems are not prepared for.
I’ve watched multiple “data economy” projects collapse into the same trap over the years. The problem usually starts with incentives.
The moment a protocol rewards contribution, the system begins attracting optimization behavior instead of genuine value creation. People stop asking, “What information is useful?” and start asking, “What activity gets rewarded fastest?”
That distinction destroys ecosystems quietly.
I saw it happen during earlier DeFi farming cycles. Protocols wanted liquidity, so users optimized for emissions. NFT ecosystems wanted engagement, so communities optimized for artificial hype. SocialFi platforms wanted interaction, so users optimized for visibility rather than quality.
The same risk exists with AI data systems.
If contribution metrics are weak, the network fills with noise almost immediately. Spam. Synthetic behavior. Low-quality signals. Recycled information. Manufactured participation.
And the worst part is that these systems can still look successful from the outside while decaying internally. High activity numbers hide weak foundations surprisingly well.
That is why OpenLedger’s challenge is much harder than branding a decentralized AI platform. The real challenge is whether it can separate meaningful contribution from empty participation.
Because if it cannot, none of the bigger ideas matter.
This is where the concept of attribution becomes more important than most people realize. Crypto loves talking about ownership, but ownership without traceability becomes fragile fast.
OpenLedger’s broader thesis appears to revolve around the idea that useful data should not disappear once it enters a model pipeline. Instead, contributors, datasets, and information sources should maintain some relationship to the value they help create.
That sounds philosophical until you think about where AI is heading.
The more autonomous systems become, the more important accountability becomes. And accountability needs receipts.
If an AI agent makes a decision inside a financial system, users will eventually want to know what information shaped the action, which model generated the conclusion, what signals influenced the outcome, whether the data was verified, whether the source was reliable, and who contributed to the underlying intelligence layer.
Right now, most AI systems operate like sealed boxes. Outputs appear. Explanations rarely do.
That may work during early experimentation phases, but it becomes dangerous once real capital starts depending on automated systems. Especially in DeFi.
This is probably the part of OpenLedger that interests me the most. Crypto keeps rushing toward AI-driven automation before solving the trust layer underneath it.
Everyone wants intelligent agents capable of managing portfolios, reallocating liquidity, monitoring market conditions, executing trades, optimizing yield, analyzing sentiment, adjusting risk exposure, and coordinating on-chain strategies automatically.
Fine. Maybe that future arrives.
But I have also seen what happens when automation scales faster than accountability. Systems become unreadable. And unreadable systems eventually lose trust.
That matters more in DeFi than many builders want to admit.
Traditional finance already struggles with opaque decision-making structures. Crypto was supposed to improve transparency, not recreate hidden mechanisms with more complicated branding. If users feel like protocols are making intelligent decisions behind a curtain they cannot inspect, confidence begins leaking out of the ecosystem slowly.
Trust erosion rarely happens all at once. It starts with uncertainty. Then hesitation. Then reduced participation. Then liquidity leaves.
The projects that survive long-term are usually the ones that understand this earlier than everyone else.
That is why OpenLedger’s focus on data provenance and attribution feels more infrastructure-oriented than narrative-oriented to me. It is less about making AI look exciting and more about making intelligent systems auditable.
That is a much harder problem.
What also stands out is the project’s emphasis on community-built data networks.
In theory, this could become powerful.
Specialized communities often produce information that centralized systems struggle to replicate: niche market intelligence, behavioral insights, regional knowledge, industry-specific expertise, emerging trend recognition, and real-time contextual awareness.
These kinds of signals become valuable when training models or improving agent performance because they reflect actual lived environments rather than generic internet-scale scraping.
But again, the quality problem never disappears.
A community-driven system only works if contribution standards remain meaningful. Otherwise the network risks becoming another incentive machine where users chase rewards while the informational quality degrades underneath the surface.
I think OpenLedger understands this tension, at least conceptually. The question is whether the infrastructure can enforce quality strongly enough over time.
That is where most systems fail.
Not during launch. Not during campaigns. Not during narrative expansion.
They fail during saturation.
Once rewards become predictable, participants begin gaming every visible metric. The protocol then has to decide whether it wants authentic value creation or inflated participation statistics.
Those decisions shape the future of the ecosystem more than marketing ever will.
Another reason I keep watching OpenLedger is because AI has made data ownership economically urgent instead of philosophically interesting.
A few years ago, conversations about data rights sounded abstract. Now they sound inevitable.
The internet trained people to think their digital behavior was disposable. AI is proving the opposite. Every interaction now carries potential training value. Every dataset can become infrastructure. Every behavioral pattern can feed machine intelligence capable of generating revenue elsewhere.
That changes the economics of contribution entirely.
Suddenly the question becomes uncomfortable:
If machines are extracting value from human-generated information at scale, who participates in that value loop?
Right now, the answer is usually “not the contributors.”
That imbalance probably does not survive forever.
Either regulation forces attribution standards eventually, or markets begin demanding systems capable of proving provenance and accountability voluntarily.
OpenLedger seems to be positioning itself before that pressure fully arrives. That timing matters.
Some infrastructure projects fail because they are too early. Others become foundational because they solved a future problem before the market understood its importance.
I do not know which category OpenLedger will fall into yet. But I do think it is targeting a real fracture point.
The market itself also feels different now.
People are more skeptical. Builders are more exhausted. Users are less patient with empty promises. Even the hype cycles feel shorter than before.
The industry has spent years funding narratives that sounded revolutionary until incentives disappeared. That history makes it harder for newer infrastructure projects to earn trust through branding alone.
OpenLedger cannot survive purely on the AI narrative.
Eventually it has to prove the data networks produce useful outputs, the attribution systems actually work, contributors receive meaningful participation pathways, developers integrate because the infrastructure solves real problems, and agents benefit from transparent intelligence layers rather than vague decentralization claims.
That is the uncomfortable stage every serious crypto project eventually reaches.
Usage or narrative. Substance or momentum. Infrastructure or marketing.
The projects that matter long-term usually become slightly boring before they become essential. The excitement fades first. Then the actual utility starts getting tested under pressure.
I suspect OpenLedger is moving toward that stage now.
Personally, I respect projects more when they aim at difficult structural problems instead of easy emotional narratives. And data accountability is absolutely a structural problem.
AI made it impossible to ignore.
Because the deeper AI integrates into finance, research, governance, automation, and digital coordination, the more dangerous invisible intelligence systems become. If users cannot trace how decisions are formed, trust eventually collapses under complexity.
OpenLedger appears to understand that transparency alone is no longer enough.
The next layer is traceability.
Not just seeing transactions. Seeing where intelligence came from.
That is a much bigger shift than people realize.
Maybe OpenLedger succeeds. Maybe it becomes critical infrastructure for AI-driven systems that require attribution, provenance, and accountable data flows.
Or maybe it gets buried beneath faster narratives, louder incentives, and shorter attention cycles like many ambitious crypto projects before it.
I honestly do not know yet.
But I do know this:
The projects worth watching are usually the ones trying to solve problems the market still underestimates.
And right now, the value trail behind AI might be one of the most underestimated problems in the entire industry.
@OpenLedger #OpenLedger #openledger $OPEN
