

I’ve been watching OpenLedger for a while now, and what keeps pulling my attention back is not the token or the usual “AI + crypto” narrative people rush to push every cycle. It’s the fact that the project seems to be focusing on a problem the AI industry quietly keeps avoiding. Everyone talks about models, compute power, and automation, but very few people seriously talk about who actually contributes value to these systems and whether those contributors can ever be recognized fairly once everything disappears into black-box AI models. That’s the part OpenLedger appears to be trying to address, and honestly, I think that conversation matters more than most people realize.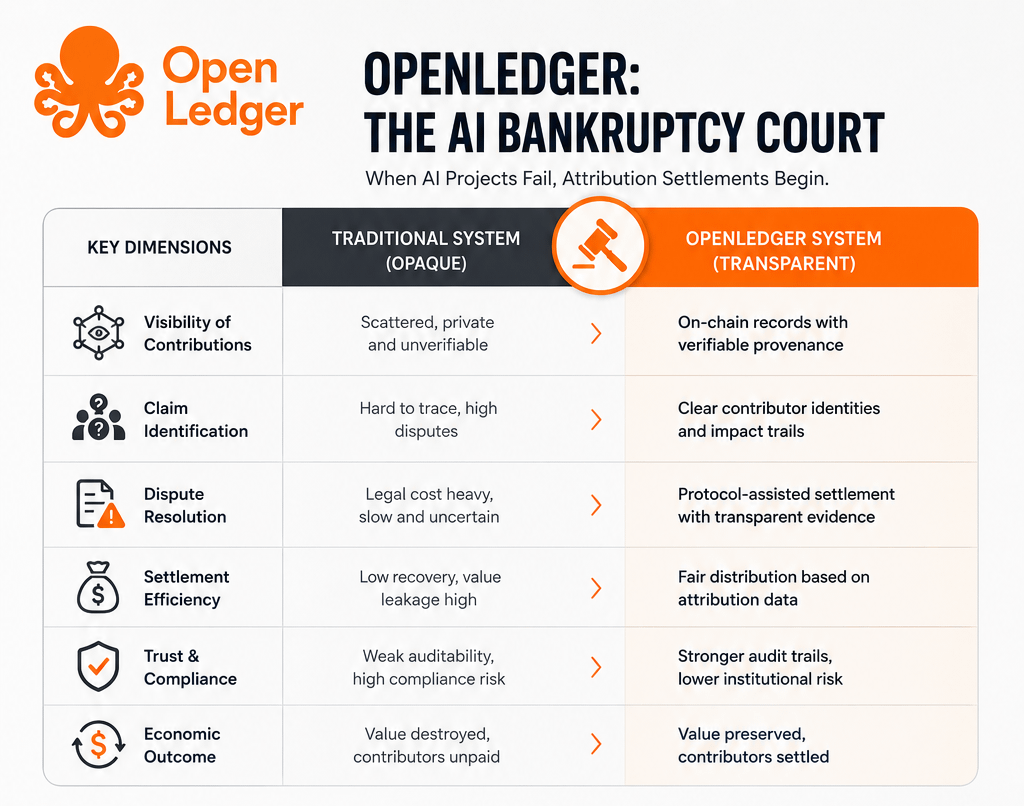
The longer I watch the AI industry develop, the clearer it becomes that modern AI is built on invisible labor. Massive amounts of data come from writers, researchers, online communities, developers, creators, and ordinary users who never really become part of the economic picture once models are trained. Their input gets absorbed into systems that later generate billions in value, while the relationship between contribution and reward becomes impossible to trace. OpenLedger seems to be built around the idea that this missing connection eventually becomes a serious structural problem, especially as AI becomes more commercialized and more deeply integrated into everyday life.
What makes the project interesting to me is that it doesn’t feel like it’s trying to compete directly with the biggest AI companies on model quality alone. Instead, it seems more focused on the infrastructure underneath AI itself. Attribution, provenance, coordination, tracking contributions — these are not flashy topics, but they are the kind of foundational problems industries eventually have to solve once they mature. In many ways, OpenLedger feels less like an AI product and more like an attempt to build accounting infrastructure for the AI economy.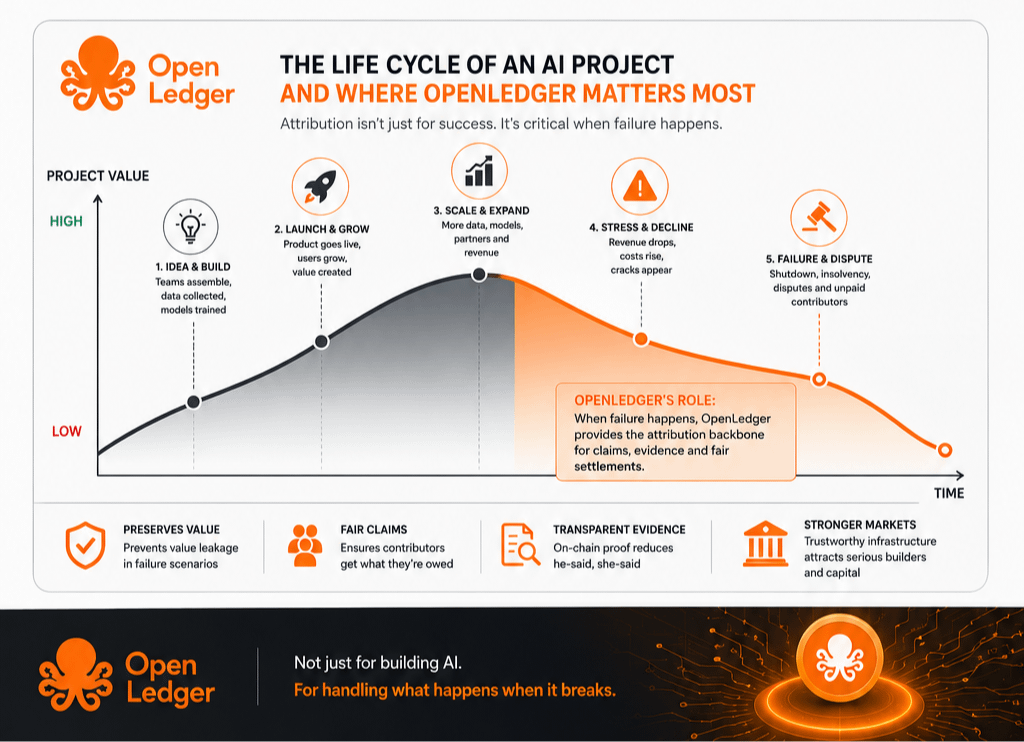
That idea sounds simple when people explain it casually, but the reality is probably much more complicated than it first appears. AI systems are messy by nature. A single model may be influenced by millions of different data points, contributors, refinements, and interactions over time. Trying to measure which input actually mattered — and by how much — is incredibly difficult. I think this is where many projects underestimate reality. Creating a fair system for attribution is not just a technical challenge. It’s also a social and economic challenge because once money and ownership enter the picture, disagreements become unavoidable.
That’s why I keep looking at OpenLedger with cautious interest instead of excitement. I’ve seen enough crypto cycles to know that good narratives are everywhere, but systems that survive real-world incentives are much rarer. In theory, everyone supports fairness and transparency. In practice, people immediately begin trying to maximize their own advantage once rewards are involved. Spam data appears. Manipulation appears. Arguments over quality appear. Any infrastructure trying to connect AI outputs to contributor rewards will eventually face these pressures.
At the same time, I do think the timing of the project is important. The AI industry is slowly moving toward a future where questions around data ownership, licensing, and accountability become harder to ignore. Regulators are paying closer attention. Creators are becoming more defensive about how their work is used. Companies are increasingly treating proprietary data as strategic assets. The idea that AI systems may eventually need clearer attribution and transparent economic flows no longer feels unrealistic to me. It feels increasingly inevitable.
The token itself, at least from my perspective, feels like a supporting component rather than the center of the story. OPEN may help coordinate incentives inside the ecosystem, but I don’t think the long-term relevance of OpenLedger depends on token speculation alone. If the infrastructure actually solves meaningful coordination problems, the token becomes part of the machinery. If the underlying system fails to gain adoption, then the token probably doesn’t matter much either. That’s usually how infrastructure projects work regardless of how aggressively markets price them in the short term.
What I also find interesting is that OpenLedger seems to understand that AI is not only a technology race anymore. It’s becoming an economic coordination problem. The industry is moving toward a world where the hardest questions are not just about building smarter models, but about deciding who owns value, who gets compensated, and how trust is maintained between participants who may never know each other directly. Those are complicated systems problems, and crypto infrastructure arguably makes more sense there than in many of the use cases the industry chased over the last decade.
Still, I think it’s far too early to know whether projects like OpenLedger can truly operate at meaningful scale outside controlled environments. Building infrastructure is one thing. Convincing developers, companies, and contributors to align around shared standards is something else entirely. History shows that industries often resist transparency until they absolutely need it. So the biggest challenge may not be technical design at all. It may simply be adoption and behavior.
Right now, I see OpenLedger as a serious attempt to explore a real weakness inside the AI economy rather than just another project attaching itself to a trend. Whether it ultimately succeeds is still uncertain, but at least the problem it’s aiming at feels genuine. And honestly, in a market full of recycled narratives and short attention spans, that alone makes it worth watching carefully.