Ir neliela problēma AI iekšienē, kas ne vienmēr saņem pietiekamu uzmanību.
Cilvēki runā par to, ko AI var darīt. Viņi runā par ātrumu, precizitāti, izmaksām un uzdevumiem, ko tas var pārņemt. Bet viņi ne vienmēr runā par jautājumu, kas izvirzās tieši pirms tā izmantošanas.
Vai es varu uzticēties tam, uz kā tas ir balstīts?
Šis jautājums šķiet vienkāršs, bet tas atver daudz.
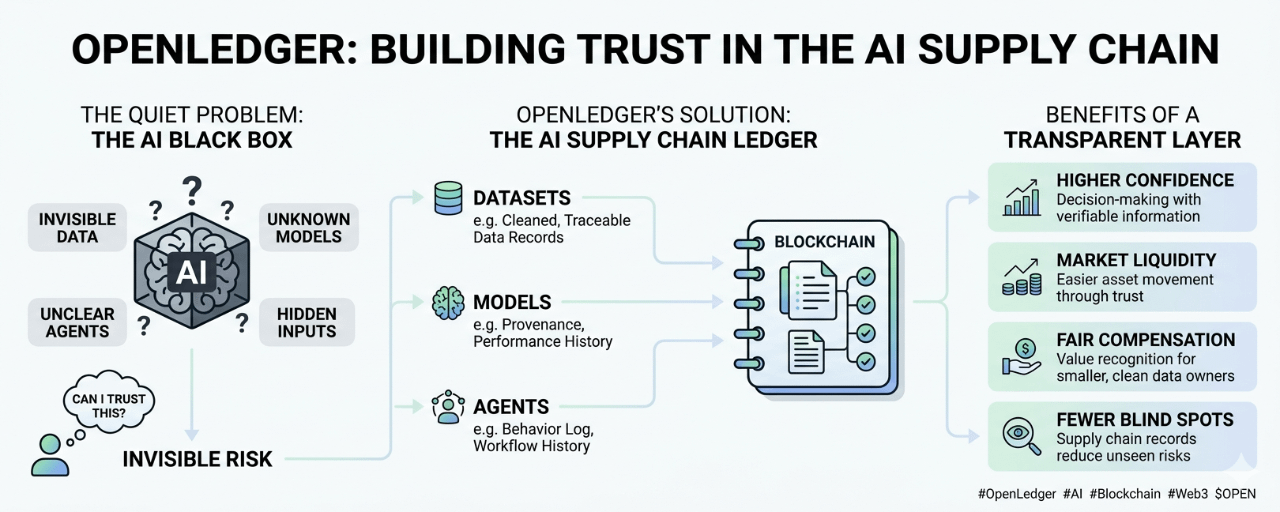
Katrā AI sistēmā ir kaut kas iekšā. Dati, no kuriem tā mācījās. Modeļi, uz kuriem tā paļaujas. Aģenti, kas rīkojas saskaņā ar norādījumiem. Rīki, kas savienojas ar citiem rīkiem. Dažreiz ķēde ir skaidra. Bieži tas tā nav. Lietotājs redz galīgo rezultātu, bet ne sastāvdaļas.
@OpenLedger izskatās interesanti, kad to apskata no šī leņķa.
Nevis kā vēl viens mēģinājums padarīt AI lielāku. Nevis kā jauna etiķete jau pazīstamam. Vairāk kā veids, kā padarīt slēptās AI daļas redzamākas, izsekojamas, un iespējams, noderīgākas laika gaitā.
Jo dziļāk AI iekļūst reālajā darbā, jo vairāk cilvēki rūpēsies par to, no kurienes lietas nākušas.
Kompānija, iespējams, nevēlas izmantot datu kopu, ja nezina, kā tā ir savākta. Izstrādātājs, iespējams, nevēlas izmantot modeli, ja nav kāda uzvedības ieraksta. Lietotājs, iespējams, nevēlas, lai aģents pieņem lēmumus, ja neviens nevar izskaidrot, kādus rīkus tas izmantoja vai kāda loģika ietekmēja tā darbības.
Sākumā tas izklausās pēc tehniskas bažas. Laika gaitā tas sāk šķist kā uzticības baža.
#OpenLedger ir balstīta uz datiem, modeļiem un aģentiem. Tie nav tikai programmatūras gabali. Tie kļūst arī par ekonomiskiem elementiem. Tie nes vērtību. Tie var uzlabot sistēmas. Tie var ietaupīt laiku. Tie var radīt izejas, uz kurām citi var būvēt. Bet lai šī vērtība droši pārvietotos, cilvēkiem ir nepieciešams vairāk par piekļuvi. Viņiem ir nepieciešams konteksts.
Tur blockchain sāk iegūt jēgu klusākā veidā.
Nevis kā burvju risinājums. Nevis kā galvenais varonis. Vairāk kā kopīgs piezīmju bloks, uz kuru var atsaukties dažādas puses. Vieta, kur var reģistrēt lietošanu, īpašumtiesības un ieguldījumus, neprasot visiem uzticēties vienai privātai datu bāzei.
Parasti var pateikt, kad tirgus vēl veidojas, jo uzticības slānis ir vājš. Cilvēki paļaujas uz reputāciju, slēgtiem līgumiem vai lielām platformām, lai samazinātu risku. Tas darbojas kādu laiku. Bet tas arī ierobežo, kas var piedalīties.
Mazie datu īpašnieki varētu būt noderīgi resursi, bet pircēji var viņiem neuzticēties. Neatkarīgi modeļu veidotāji var radīt spēcīgus rīkus, bet viņiem var nebūt zīmola nosaukuma, lai pierādītu kvalitāti. Aģentu izstrādātāji var izveidot noderīgas darba plūsmas, bet šiem aģentiem nepieciešama kāda vēsture, pirms citi jūtas ērti tos izmantot.
OpenLedger šķiet mēģina dot šiem elementiem vēsturi.
Tas ir cits skatījums nevis vienkārši monetizējot AI aktīvus. Monetizācija ir svarīga, protams. Ja kāds izveido noderīgu datu kopu vai modeli, viņam vajadzētu būt veidam, kā nopelnīt no tā. Bet pelnīšana ir atkarīga no uzticības. Pirms kāds maksā par aktīvu, viņš vēlas zināt, kas tas ir, kur tas ir izmantots un vai tas patiešām palīdz.
Šajā ziņā likviditāte nav tikai par kustību. Tā ir arī par pārliecību.
Tirgus kļūst likvīds, kad cilvēki var rīkoties bez pārāk lielām šaubām. Viņiem nav nepieciešama perfekta pārliecība, bet viņiem nepieciešama pietiekama informācija, lai pieņemtu lēmumu. Ja OpenLedger var palīdzēt AI aktīviem nēsāt izcelsmes, lietošanas un veiktspējas ierakstus, tad dati un modeļi kļūst vieglāk pārvietojami. Nevis tāpēc, ka visi pēkšņi viņiem tic, bet tāpēc, ka ir kaut kas, ko pārbaudīt.
Tas kļūst svarīgāk, kad AI kļūst modulārs.
Nākotne, iespējams, nebūs viens milzīgs modelis, kas dara visu. Tā var būt modeļu, datu kopu, aģentu un rīku sajaukums, kas strādā kopā. Uzņēmums var izmantot vienu modeli dokumentiem, citu attēliem, privātu datu kopu iekšējai zināšanai un vairākus aģentus specifiskām darba plūsmām. Šādā uzstādījumā katrai sastāvdaļai jābūt uzticamai pašai par sevi.
Tas kļūst mazāk līdzīgi vienas mašīnas iegādei.
Tas kļūst vairāk līdzīgi piegādes ķēdes veidošanai.
Un piegādes ķēdēm nepieciešami ieraksti.
Viņiem jāzina, kas iekļuva sistēmā, kad tas iekļuva, kurš to nodrošināja, kā tas mainījās un ko tas ietekmēja. AI, iespējams, nepieciešams kaut kas līdzīgs. Nevis tāpēc, ka katrai detaļai jābūt publiskai, bet tāpēc, ka neredzamie ievadi rada neredzamus riskus.
Šeit joprojām ir grūti aspekti.
Dažus ierakstus var manipulēt. Daži veiktspējas apgalvojumi var būt vāji. Daži dati var būt sensitīvi un nevar tikt atklāti tieši. Daži aģenti var uzvesties labi vienā vidē un slikti citā. Kopīgs reģistrs nenovērš šīs problēmas. Tas tikai dod cilvēkiem vietu, kur sākt uzdot labākus jautājumus.
Tas joprojām ir noderīgi.
Pašreizējā AI pasaule bieži prasa lietotājiem uzticēties galīgajam rezultātam, nesaprotot ceļu aiz tā. OpenLedger norāda uz citu ieradumu. Tas liecina, ka ceļš ir svarīgs. Sastāvdaļas ir svarīgas. AI aktīva vēsture ir svarīga.
Tas varētu mainīt, kā tiek vērtēti mazāki dalībnieki.
Mazs datu kopums ar skaidriem ierakstiem var kļūt vērtīgāks nekā liels datu kopums ar neskaidru izcelsmi. Šaurs modelis ar uzticamu lietošanas vēsturi var būt vieglāk pieņemams nekā plašs modelis ar neskaidriem apgalvojumiem. Aģents, kas var parādīt, ko tas izdarīja un kādos apstākļos, var nopelnīt vairāk uzticības nekā tas, kas vienkārši sola automatizāciju.
Vērtība pāriet no skaļuma uz saprotamību.
Tas ir smalks pārmaiņas, bet šķiet svarīgs.
AI jau ir padarījusi radīšanu vieglāku. Tā ir padarījusi izejas lētākas un ātrākas. Bet nākamais izaicinājums varētu būt šķirot cauri visam tam ātrumam. Zināt, kuri aktīvi ir reāli, kuri ir noderīgi, kuri ir droši un kuriem jāmaksā.
OpenLedger ir viens mēģinājums strādāt pie šī klusā slāņa.
Nevis spīdīgā AI priekšpuse. Nevis galīgā atbilde uz ekrāna. Ieraksts zem tā. Daļa, kas palīdz cilvēkiem redzēt, ko viņi faktiski izmanto.
Un, iespējams, kad AI kļūst izplatītāks, šis ieraksts būs svarīgāks, nekā mēs gaidām. Nevis tāpēc, ka cilvēki vēlas vairāk sarežģītības, bet tāpēc, ka viņi vēlēsies mazāk aklumu.
$OPEN
Raksts
OpenLedger un kluss uzticības jautājums AI
Atruna: ietver trešo pušu viedokļus. Tas nav padoms. Binance AI var tikt izmantots bez garantijas. Skati lietošanas noteikumus.