这两年AI版权官司打得有多凶,做内容的人多少都有体感。纽约时报告OpenAI的案子去年年底出了一审判决,Getty Images告Stability AI那边欧洲和美国两条线都还在打,今年三月又冒出几起音乐厂牌联合起诉Suno和Udio的诉讼,整个2026年上半年AI公司的法务部门基本没闲着。我有个朋友在一家中型音乐版权公司做BD,她跟我说她们今年的工作内容已经不是谈合作了,而是天天追着各家AI公司问,你们的训练数据里到底有没有我们的内容,有的话怎么算钱。
这个场景挺荒诞的,因为版权方知道AI公司用了它们的内容,AI公司也知道自己用了,但中间没有一个能让双方都认账的机制,所以只能靠诉讼来解决。我第一次认真去看@OpenLedger 是因为这件事,想看看链上归因这套技术能不能给版权这个老问题一个新答案。
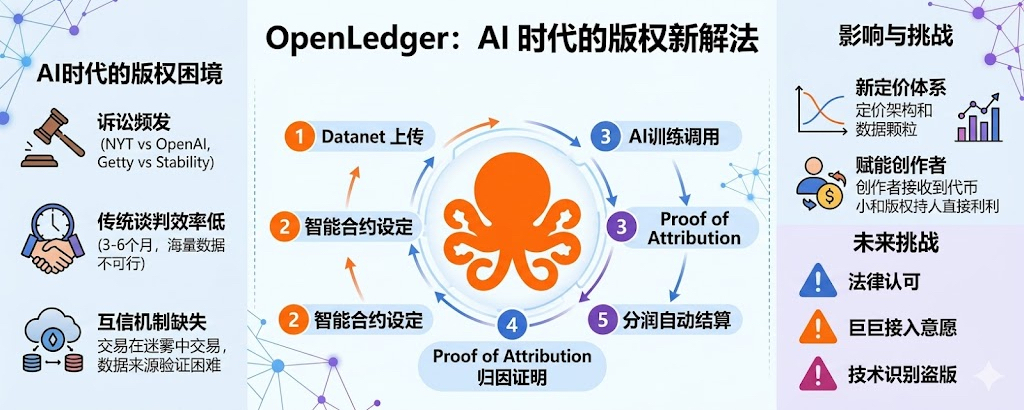
OpenLedger做的事情,往大了说其实是在搭一个AI版权和授权的底层协议。版权方把内容上传到Datanet,授权条件写进智能合约,AI模型训练的时候要调用这条数据必须先触发合约,调用一次扣一次费,分润按Proof of Attribution自动流回版权方钱包。整个链条里不需要双方坐下来签合同,不需要法务来回审核条款,也不需要事后对账。
这跟传统版权授权的逻辑差异很大。传统授权基本是一对一谈判,版权方派人跟使用方对接,谈一份合同要三到六个月,谈完之后还要靠人工对账确认使用情况,这套体系在版权方少、使用方少的时代还没啥,但放到AI时代就就不一样了。一个大模型训练可能涉及几百万个版权来源,按传统办法去谈,光是把所有版权方找齐就够律师团队忙好几年。#OpenLedger 的链上协议把这个一对一谈判的过程变成了一对多的标准化合约,版权方只需要把内容和授权条件挂上去,谁来用、用多少、怎么分钱,全部由代码自动处理。
我自己在五月这周做了一次小尝试,把一篇我自己写的文章上传到了OpenLedger的一个文本类Datanet里,授权条件写的是允许商业模型训练但要求每次调用付0.05美金等值的$OPEN 代币。半个月内我收到了几次自动结算,金额加起来大概一美金多,数字小到忽略不计,但这件事让我第一次感受到,内容创作者可以不通过任何平台直接收到模型训练的分润。
更深一层看,这套协议如果真的成熟,对整个AI版权市场的改变不只是分润机制。它可能会带来一个全新的版权定价方式。传统版权授权基本是按时间、按地域、按用途打包定价,价格由谈判双方拍脑袋决定,市场没有透明的参考标准。OpenLedger这种链上协议天然就是按使用计费,每一次调用对应一次结算,时间长了链上会沉淀出大量数据,市场参与者可以根据这些数据形成清晰的版权使用价格曲线。
法律认可是最大的不确定性,OpenLedger的智能合约在技术上能强制执行授权条件,但在法律上能不能被各国版权法认可为有效授权凭证,一份链上合约的法律效力跟一份纸质合同的法律效力之间还隔着各国司法,AI公司即使用了OpenLedger,遇到版权诉讼时还是会担心链上凭证不够用。版权方的接入意愿也是个大问题,大型版权方比如华纳音乐、迪士尼、纽约时报这种公司对自己的版权资产控制欲极强,愿不愿意把内容放到一个去中心化协议上谁都不知道,因为去中心化意味着它们对内容流向的控制权下降,OpenLedger目前能吸引到的更多是个人创作者和中小版权方,AI版权市场的大型版权方愿不愿意进来,决定了这套协议的天花板。技术层面的版权识别也还没解决,OpenLedger能记录链上数据的使用情况,但记录不了AI模型有没有用了链下来源的盗版内容来训练,一个AI公司完全可以一边用OpenLedger做合规展示,一边在底下偷偷爬版权内容来加强训练,这种双轨操作在技术上很难被监控,要彻底解决这个问题需要配合内容指纹、模型审计这一套技术。
OpenLedgerAI的版权市场需要一个能自动化处理授权和分润的底层设施,这个需求是刚性的,不会因为某家公司不做就消失。OpenLedger是真的在做这件事的项目,光这一点就让它在长期里有挺大想象空间。但要从协议走通到真正成为AI版权市场的底层标准,OpenLedger还得熬过法律认可、大型版权方接入、技术能力补齐这三个问题,每一道都不是它单方面能推动的事,需要等整个行业一起努力。