What if AI models were trained more like open-source ecosystems instead of closed corporate products?
Most people imagine AI models being built inside private labs using massive closed datasets.
But after spending more time working with AI tools, I noticed something important.
The biggest limitation usually isn’t the model itself.
It’s the quality of feedback, data, and alignment behind it.
A model can sound intelligent and still fail badly in practical use if the training process is disconnected from real users.
That’s why OpenLedger caught my attention.
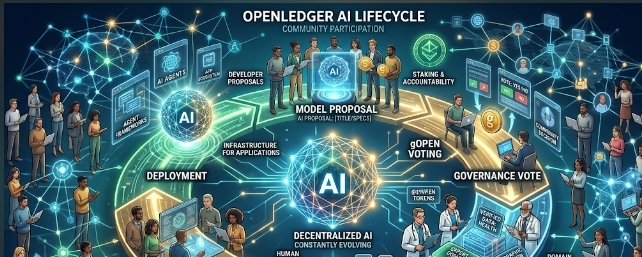
Its model lifecycle feels less like a traditional AI pipeline and more like a collaborative system where different participants help shape the final outcome together.
The process starts with a model proposal.
Developers submit an idea explaining what the model should do, how it works, and why it matters.
There’s also a staking requirement attached to proposals, which I think is important
In many open systems, low-effort participation quickly becomes a problem.
Requiring stake creates accountability before a model even enters governance.
Then the community decides what moves forward.
Protocol Governors vote using gOPEN tokens, meaning model progression depends on collective support instead of a single centralized decision-maker.
I’ve seen how difficult AI prioritization can become even in small teams.
Everyone wants different outcomes:
better reasoning, better speed, better creativity, better safety.
Governance introduces friction, but sometimes that friction is healthier than silent centralized control
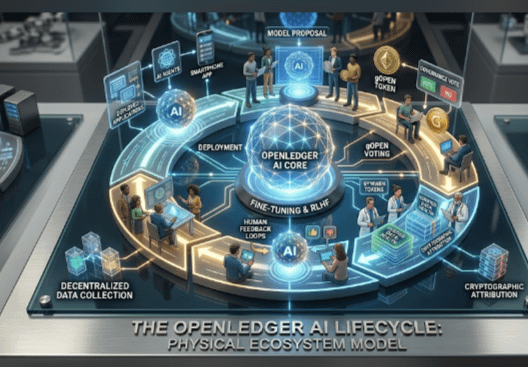
The most interesting stage for me is decentralized data collection.
From personal experience, I’ve noticed that AI quality changes dramatically depending on the data source.
A model trained only on generic internet content often feels repetitive and shallow.
But when training data comes from people with real domain expertise, responses become more useful and grounded.
For example, a healthcare-focused AI model trained with verified medical contributors would likely outperform a general-purpose model in real-world diagnosis support.
OpenLedger tries to reward contributors based on data quality and relevance instead of pure quantity.
The cryptographic attribution layer also matters because it creates transparency around contribution ownership.
After that comes fine-tuning and RLHF.
This part feels especially practical because human feedback is still one of the strongest ways to improve model behavior.
I’ve personally tested AI systems where the difference between a raw model and an aligned model was massive.
One gives technically correct answers.
The other actually understands context, tone, and user intent better.
That gap usually comes from feedback loops.
In OpenLedger’s system, validators help refine outputs, and contributors are rewarded for useful feedback while poor-quality participation can be penalized.
The final stage is deployment through APIs and agent frameworks.
That’s where the model stops being an experiment and becomes infrastructure for applications and autonomous agents.
What I find most valuable in this structure is the shift in participation.
Instead of AI value flowing only to the company that owns the final model, OpenLedger distributes contribution across multiple layers:
developers, data contributors, validators, governors, and application builders.
Of course, decentralization alone does not guarantee quality.
Open systems can easily become noisy if incentives are weak.
The real challenge will be maintaining high standards while scaling participation.
But the direction itself feels important.
After working with AI tools for a while, I’ve realized that the future of AI may depend less on who owns the biggest model — and more on who builds the healthiest ecosystem around it.
In the next phase of AI, ownership alone may not matter as much as contribution.
The strongest models could come from the strongest communities.
