OpenLedger ir viens no tiem projektiem, kas liek tev uz mirkli apstāties, nevis tāpēc, ka prezentācija ir pilnīgi jauna, bet tāpēc, ka problēma, kas slēpjas zem tās, ir pietiekami reāla, lai tu to nekavējoties noraidītu.
Un godīgi sakot, tas tagad ir reti sastopams kriptovalūtās.
Pēc dažām ciklām tu sāk attīstīt tādu kā alerģiju pret lielām naratīvām. DeFi bija paredzēts, lai pārbūvētu finanses. GameFi bija paredzēts, lai piesaistītu nākamos miljardu lietotājus. Metaverse zeme kaut kā bija paredzēta, lai aizstātu nekustamo īpašumu. Modular ķēdes bija paredzētas, lai risinātu mērogošanu. AI kripto tagad ir jaunākais posms, kur katrs projekts pēkšņi atklāj, ka tas vienmēr ir bijis par mākslīgo intelektu.
Tāpēc, kad kaut kas sevi sauc par “AI blokķēdi”, pirmā instinkts nav sajūsma. Tā ir aizdomas.
Tu izlasi frāzi vienreiz, un tava smadzenes uzreiz sagatavojas parastajam buzzwordu kaudzei: decentralizēta inteliģence, atvērtie aģenti, datu suverenitāte, mērogojama infrastruktūra, kopienas īpašums, motivācijas saskaņotība. Visi pazīstamie ingredienti. Visi vārdi, kas izklausās svarīgi, līdz tu pajautā, kas patiesībā notiek zem tā.
Bet OpenLedger vismaz norāda uz problēmu, kas ir svarīga.
AI ir ieguldījumu problēma.
Nezīmola problēma. Ne token problēma. Ieguldījumu problēma.
Katrs noderīgs AI sistēma ir veidota uz kāda cita datiem, zināšanām, piemēriem, atsauksmēm, dokumentiem, darba plūsmām, etiķetēm, korekcijām un nozares pieredzi. Tas ir tas, ko cilvēki parasti izlaiž. Modelis tiek prezentēts kā produkts, bet modelis patiesībā ir ilga neredzamu ievades rezultāts.
Kāds izveidoja datus. Kāds tos attīrīja. Kāds tos organizēja. Kāds zināja pietiekami daudz par tēmu, lai padarītu informāciju noderīgu. Tad viss tiek absorbēts modelī, un, kad tas ir iekšā, sākotnējā ieguldījuma kļūst gandrīz neiespējami redzēt.
Tā ir dīvainā vienošanās mūsdienu AI. Visi iegulda inteliģences slānī, bet tikai daži platformas piesaista lielāko daļu vērtības.
OpenLedger cenšas būvēt ap šo plaisu.
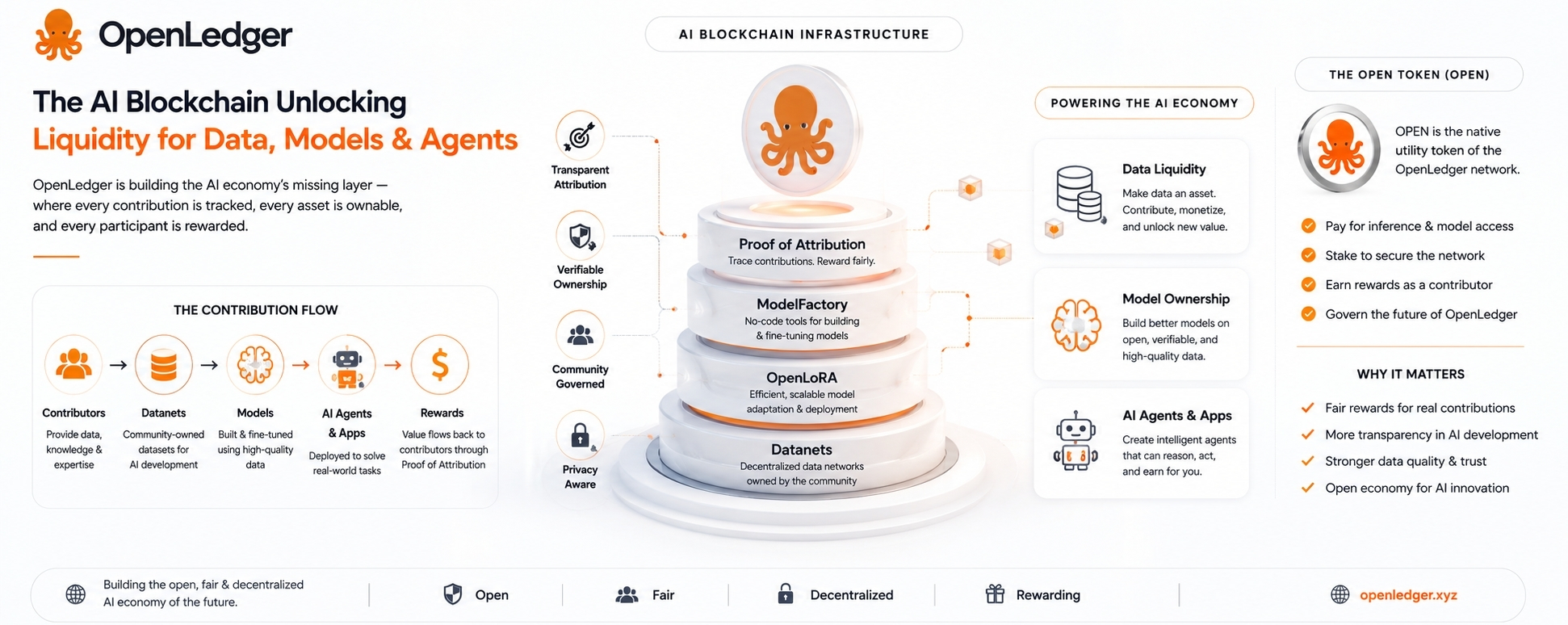
Pamatiideja ir tāda, ka dati, modeļi un AI aģenti nedrīkst vienkārši klīst kā neskaidri digitāli objekti. Tie jāspēj izsekot. Tie jāspēj saistīt ar cilvēkiem vai kopienām, kas tos izveidoja. Un, ja tie radīs vērtību vēlāk, tam jābūt kādam mehānismam, lai atlīdzinātu ieguldītājus, kas stāv aiz tiem.
Tas izklausās acīmredzami, kad tu to saki lēnām. Tas arī izklausās ārkārtīgi grūti, kad tu domā par to, kā AI patiesībā darbojas.
Jo AI atribūcija ir nekārtīga.
Modelis neatbild uz jautājumu, vienkārši velkot vienu failu no plaukta. Tas nesaka: “Šī atbilde nāca 12% no Ali datu kopas, 8% no šī audita ziņojuma un 3% no tā foruma ziņas.” Vismaz ne dabiski. Rezultāti tiek veidoti ar apmācības datiem, finetuning, svariem, aicinājumiem, iekļaušanām, atguves sistēmām, adapteriem un visām citām lietām, kas pievienotas kaudzei.
Tāpēc, kad OpenLedger runā par Atribūcijas pierādījumu, tā ir daļa, uz kuru vērst uzmanību, bet arī daļa, kas pelnījusi vislielāko skepsi.
Ideja ir identificēt, kuri dati ietekmēja AI rezultātu un atlīdzināt līdzdalībniekus, pamatojoties uz šo ietekmi. Ja tas strādā, tas ir nozīmīgi. Ja tas kļūst neskaidrs, tas ir tikai vēl viens tokenizēts punktu sistēma ar labāku valodu.
Tas ir ceļš, ko OpenLedger jāiet.
Tomēr ietvars nav tukšs. AI tiešām nepieciešama labāka grāmatvedības slāņa. Šobrīd internets ir pilns ar vērtību, ko AI sistēmas patērē, saspiest un monetizē. Rezultāts izklausās tīrs, bet ievades vēsture ir izplūdusi. Un, kad AI aģenti kļūst aizvien izplatītāki, šī izplūšana kļūst par lielāku jautājumu.
Ja AI aģents palīdz auditēt gudro līgumu, no kurienes nāca tā drošības zināšanas?
Ja AI tirdzniecības asistents atpazīst modeli, kuru dati palīdzēja to iemācīt?
Ja juridisks AI rīks pārskata līgumu, kuri dokumenti ietekmēja tā domāšanu?
Ja medicīnas asistents sniedz ieteikumu, kādas zināšanas bija zem šī atbildes?
Šie vairs nav filozofiski jautājumi. Tie kļūst par ekonomiskiem jautājumiem, kad cilvēki sāk maksāt par rezultātu.
Tāpēc OpenLedger Dataneti ir interesanti.
Datanets ir pamatā kopienas īpašuma datu tīkls, kas izveidots ap konkrētu tēmu vai lietojumu. Tā vietā, lai dati tiktu klusi savākti vienā centralizētā uzņēmumā, līdzdalībnieki var pievienot noderīgu informāciju kopīgā datu slānī. Šie dati var tikt izmantoti modeļu apmācībai vai finetuning.
Teorijā tu varētu iegūt Datanetu gudro līgumu exploitu, citu juridisko dokumentu, vēl vienu veselības aprūpes darba plūsmu, vēl vienu datu kartēšanas, vēl vienu DeFi riska analīzes un tā tālāk.
Ideja nav tikai savākt datus. Visi savāc datus. Ideja ir saglabāt ierakstu par to, kas ko ieguldījis, un tad savienot šo ieguldījumu ar nākotnes modeļa izmantošanu.
Tas ir tas, kas izklausās nopietnāk nekā parastais “AI plus token” piedāvājums.
Jo, ja specializēts AI patiešām ir tirgus virzība, tad specializēti dati kļūst ārkārtīgi vērtīgi. Vispārējie modeļi jau ir pietiekami labi plašiem uzdevumiem. Nākamā cīņa nav par to, kurš var likt čatbotu teikt jaukas lietas. Tā ir par to, kurš var izveidot modeļus, kas padziļināti saprot konkrētas jomas.
Vispārējs AI var izskaidrot gudro līguma risku. Specializēts modelis, kas apmācīts uz reāliem exploit datiem, varētu patiešām palīdzēt to noteikt.
Vispārējs AI var runāt par finansēm. Specializēts modelis, kas apmācīts uz strukturētu tirgus uzvedību un risku datiem, var kļūt noderīgāks.
Vispārējs AI var kopsavilkumu veselības aprūpes saturu. Specializēts klīnisks modelis, pieņemot, ka privātums un atbilstība tiek pareizi apstrādāti, varētu darīt kaut ko daudz vērtīgāku.
Tātad OpenLedger vēršas uz reālu tendenci: pāreju no vispārējā AI uz jomas specifisku inteliģenci.
Bet atkal, izpilde ir svarīga.
Kripto ir ieradums katru derīgu problēmu pārvērst par pārāk izstrādātu token ekonomiku. Dažreiz token ir būtisks. Dažreiz tas ir tikai līmes lente pār tirgu, kas varētu darboties bez tā.
OPEN, vietējais token, paredzēts sēdēt OpenLedger ekonomikā. To var izmantot tīkla maksām, modeļu piekļuvei, secinājumu maksājumiem, likmēm, pārvaldībai un līdzdalībnieku atlīdzībām. Tas strukturāli ir saprātīgi. Ja tīkls patiesi tiek izmantots, tokenam ir loma.
Bet frāze “ja tīkls patiesi tiek izmantots” šeit veic daudz darba.
Token nepieņem pieprasījumu, tikai pastāvot. Tirgus kļūst vērtīgs nevis tāpēc, ka informācijas panelis saka, ka līdzdalībnieki var nopelnīt. Grūtā daļa ir panākt, lai cilvēki ieguldītu augstas kvalitātes datus, panākt, lai izstrādātāji veidotu modeļus no šiem datiem, panākt, lai lietotāji maksātu par šiem modeļiem, un nodrošināt, lai atlīdzības plūst tā, lai tas justos taisnīgi, nevis patvaļīgi.
Tur ir, kur daudzi kripto projekti sabrūk.
Viņi var izstrādāt motivācijas pirmajai viļņai. Viņi var piesaistīt agrīnos līdzdalībniekus. Viņi var padarīt grafikus dzīvīgus. Bet ilgtermiņa vērtība nāk tikai tad, ja sistēma rada kaut ko, ko cilvēki ārpus motivācijas loka patiešām vēlas.
OpenLedger nākotne ir atkarīga no tā, vai tā var ražot noderīgas AI sistēmas, ne tikai labi marķētus datu kopumus.
ModelFactory ir daļa no šī mēģinājuma. Tā ir paredzēta, lai padarītu finetuning vieglāku, īpaši cilvēkiem, kas nevēlas saskarties ar smagu mašīnmācīšanās infrastruktūru. Tas ir labs virziens, jo vairums nozares ekspertu nav ML inženieri.
Persona, kas saprot juridiskos līgumus, var pat nezināt, kā pielāgot modeli.
Treideris, kurš saprot tirgus struktūru, var nezināt, kā izvietot secinājumu infrastruktūru.
Drošības pētnieks, kurš saprot exploitus, var negribēt pārvaldīt adapterus un GPU.
Ja OpenLedger var padarīt to vieglāk šiem cilvēkiem pārvērst zināšanas izmantojamās AI aktīvos, tas ir svarīgi.
OpenLoRA ir vēl viens praktisks gabals. Specializētie modeļi ir noderīgi, bet to palaišana var kļūt dārga. LoRA balstīta finetuning jau ir viens no reālākajiem ceļiem, kā izveidot daudz vieglus modeļu variantus. Ja OpenLedger var atbalstīt efektīvu daudzu finetunētu modeļu izvietošanu, tas dod ekosistēmai praktiskāku pamatu.
Šeit projekts sāk izskatīties mazāk kā tīra naratīva spēle un vairāk kā mēģinājums izveidot pilnu AI ražošanas kaudzi.
Dati nāk caur Datanetiem.
Modeļi tiek radīti vai finetunēti, izmantojot tādus rīkus kā ModelFactory.
OpenLoRA palīdz ar izvietošanu.
AI aģenti un lietojumprogrammas sēž virsū.
Bloks reģistrē ieguldījumus, izmantošanu un atlīdzības.
Tas ir vismaz karte.
Vai teritorija izskatās tā ir cits jautājums.
Visgrūtākais joprojām ir atribūcija. Ir viegli uzrakstīt “Atribūcijas pierādījums” baltajā grāmatā. Ir daudz grūtāk likt līdzdalībniekiem uzticēties, ka sistēma precīzi mēra ietekmi. Ja atlīdzības ir pārāk neskaidras, cilvēki zaudēs interesi. Ja sistēma var tikt izspēlēta, zemas kvalitātes dati ieplūdīs. Ja tikai lieli līdzdalībnieki gūst labumu, kopienas aspekts vājinās. Ja atribūcija ir pārāk dārga vai pārāk lēna, izstrādātāji to var izvairīties.
Ir arī privātuma problēma. Daži no vērtīgākajiem AI datiem ir sensitīvi. Veselības aprūpes dati, finanšu ieraksti, juridisks materiāls, uzņēmējdarbības darba plūsmas - šie nav lietas, ko cilvēki vienkārši iemet atvērtā tīklā. OpenLedger vajadzēs spēcīgas atļaujas, privātumu un atbilstības ceļus, ja tas vēlas nopietnu pieņemšanu ārpus kripto dzimušiem datu kopumiem.
Tad ir tirgus problēma. AI kripto ir pārpildīts. Katra nedēļa ir jauna aģentu platforma, datu tirgus, secinājumu tīkls, decentralizēta skaitļošanas slāņa vai modeļa īpašumtiesību protokols. Daži ir pārdomāti. Daudzi ir naratīva apvalki. Investori un lietotāji ir noguruši, pat ja viņi joprojām dzenas pēc nākamās rotācijas.
Tātad OpenLedger ir jāpierāda, ka tā pamata mehānisms patiesi ir svarīgs.
Ne teorijā.
Izmantošanā.
Vai kāds var izveidot labāku modeli, pateicoties OpenLedger?
Vai līdzdalībnieks var nopelnīt, jo viņu dati patiešām uzlaboja rezultātu?
Vai izstrādātājs var palaist AI aģentu ātrāk vai lētāk?
Vai lietotājs var uzticēties tam, no kā viņš mijiedarbojas?
Vai sistēma var piesaistīt datus, kuri citur nebūtu parādījušies?
Tie ir jautājumi, kas ir svarīgi.
Un varbūt tāpēc OpenLedger ir vērts sekot līdzi, neiekrist sajūsmā.
Tas nav automātiski revolucionārs. Tas nav garantēts, ka tas kļūs par AI īpašumtiesību pamatlīmeni. Tas nav imūns pret parastajām kripto problēmām, spekulācijām, pārmērīgi motivētām aktivitātēm un naratīva inflāciju.
Bet tas riņķo ap reālu jautājumu.
AI rada milzīgu vērtību no neredzamām ievadēm. Pašreizējā sistēmā nav godīgas vai caurspīdīgas veids, kā izsekot šīm ievadēm. OpenLedger cenšas izveidot šo trūkstošo slāni, izmantojot blokķēdes sliedes, atribūcijas loģiku un token motivācijas.
Tas var strādāt. Tas var nedarboties.
Bet problēma ir pietiekami reāla, lai mēģinājums pelnītu vairāk nekā ātru noraidījumu.
Tīrākais veids, kā domāt par OpenLedger, ir šāds: tas vēlas dot AI ekonomisko atmiņu.
Ne tikai atmiņa modeļa izpratnē, bet arī ieguldījumu atmiņa. Kas pievienoja datus? Kas veidoja modeli? Kas izveidoja aģentu? Kam pienākas daļa, kad sistēma kļūst noderīga?
Tas ir pārliecinoša ideja, īpaši pasaulē, kur AI kļūst aizvien jaudīgāks un centralizētāks vienlaikus.
Manā skeptiskajā pusē joprojām ir nepieciešama pierādījums. Reāla izmantošana. Reāli līdzdalībnieki. Reāli modeļi. Reāla pieprasījuma. Ne tikai kampaņas, punkti, token emisijas un ekosistēmas partneru ekrānuzņēmumi.
Bet pētnieks manī saprot, kāpēc šī kategorija ir svarīga.
Ja nākamā AI fāze ir veidota uz specializētiem datiem un autonomiem aģentiem, tad īpašumtiesības un atribūcija nav blakus iezīmes. Tās kļūst par infrastruktūru.
OpenLedger uz to liek likmes.
Un pēc pietiekami daudz balto grāmatu izlasīšanas, lai zinātu, cik bieži šīs lietas sabrūk trokšņos, šī vismaz atstāj jautājumu, kas paliek: