Augšupielāde neizdevās. Tas bija neērtais moments.
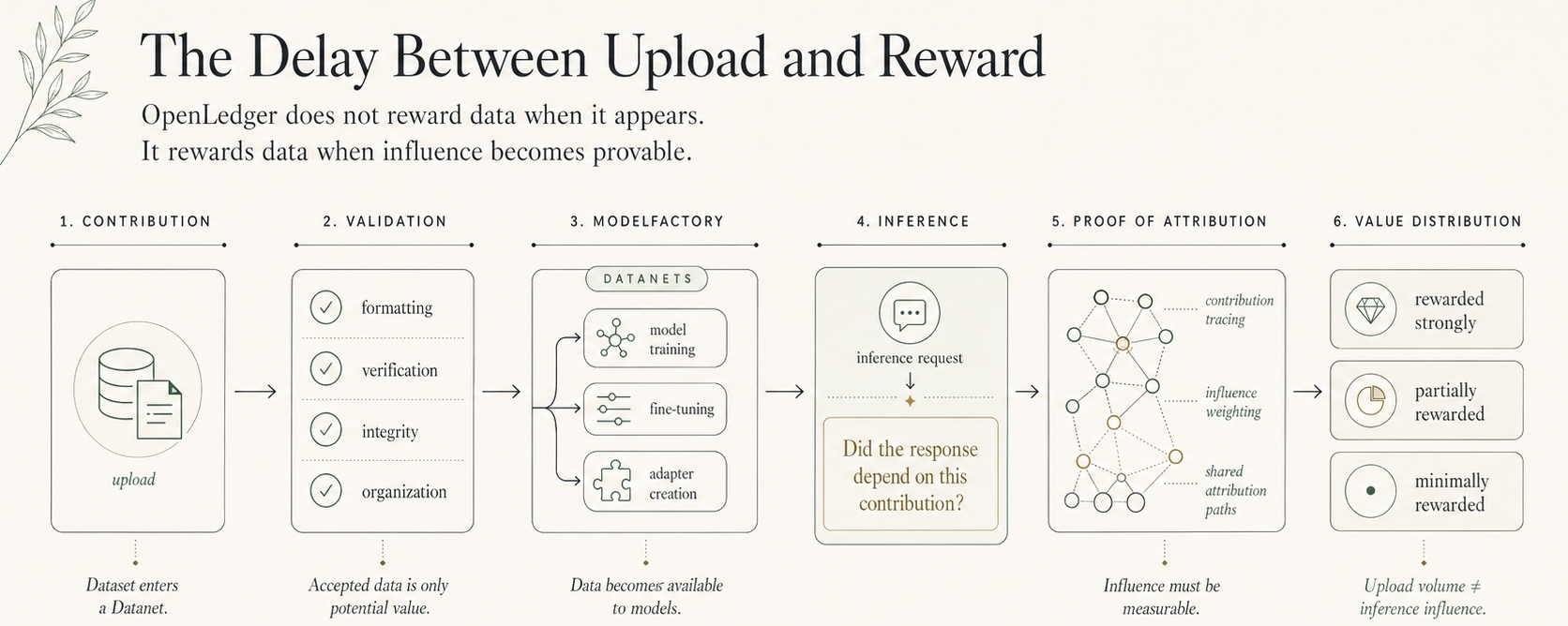
Faili tika apstrādāti. Struktūra noturējās. Datanet pieņēma ieguldījumu bez drāmas. Nav trūkstoša formāta brīdinājuma. Nav bojāta shēma. Nav acīmredzamu noraidījumu no darba plūsmas.
No malas tas izskatījās kā tīrs sākums.
Dati iesniegti. Ieguldītāja rekords izveidots. Domēna konteksts pievienots. Izejmateriāls tagad bija vieta, kur atpūsties OpenLedger, nevis pazust citā privātajā mapē, citā pētījumu arhīvā, citā laboratorijas cauruļvadā, kur noderīgi dati kļūst noderīgi tikai pēc tam, kad kāds cits tos absorbē.
Bet pēc tam jautājums nāca vēlāk.
“Kur šie dati tagad iet?”
Tehniski nē. Tehniski tie bija aizgājuši kaut kur. Tie bija iekļuvuši Datanet. Tam bija protokola vietējais ceļš, devēja pēdas, pozīcija sistēmā, kas izveidota AI datu likviditātei. Šī daļa bija pietiekami skaidra.
Grūtāks jautājums bija ekonomiskais.
Kas to atrod?
Kas uz to apmāca?
Kurai modelim tas ir tik ļoti nepieciešams, lai ieguldījums būtu svarīgs ārpus uzglabāšanas?
Es skatījos uz plūsmu ilgāk, nekā gaidīju. Dati vairs nebija pilnīgi neapstrādāti. Tas bija svarīgi. Tie bija pārkāpuši pirmo robežu. OpenLedger, Datanet nav tikai failu konteineris. Tas ir vieta, kur domēna dati sāk iegūt identitāti pirms modeļa uzlabošanas, pirms aģents rīkojas, pirms secinājuma notikums rada redzamu pieprasījumu.
Tas bija mans pirmais nepareizais lasījums.
Es domāju, ka svarīgais brīdis nāks vēlāk. ModelFactory apmācība. Aģenta izmantošana. OPEN atlīdzības, kas ienāk pēc tam, kad dati jau ir pierādījuši sevi reālā darba plūsmā. Tīrā stāsts sākas tur, jo ieņēmumus ir vieglāk pamanīt pēc tam, kad kaut kas atbild.
Bet spiediens sākas agrāk.
Tas sākas no izcelsmes.
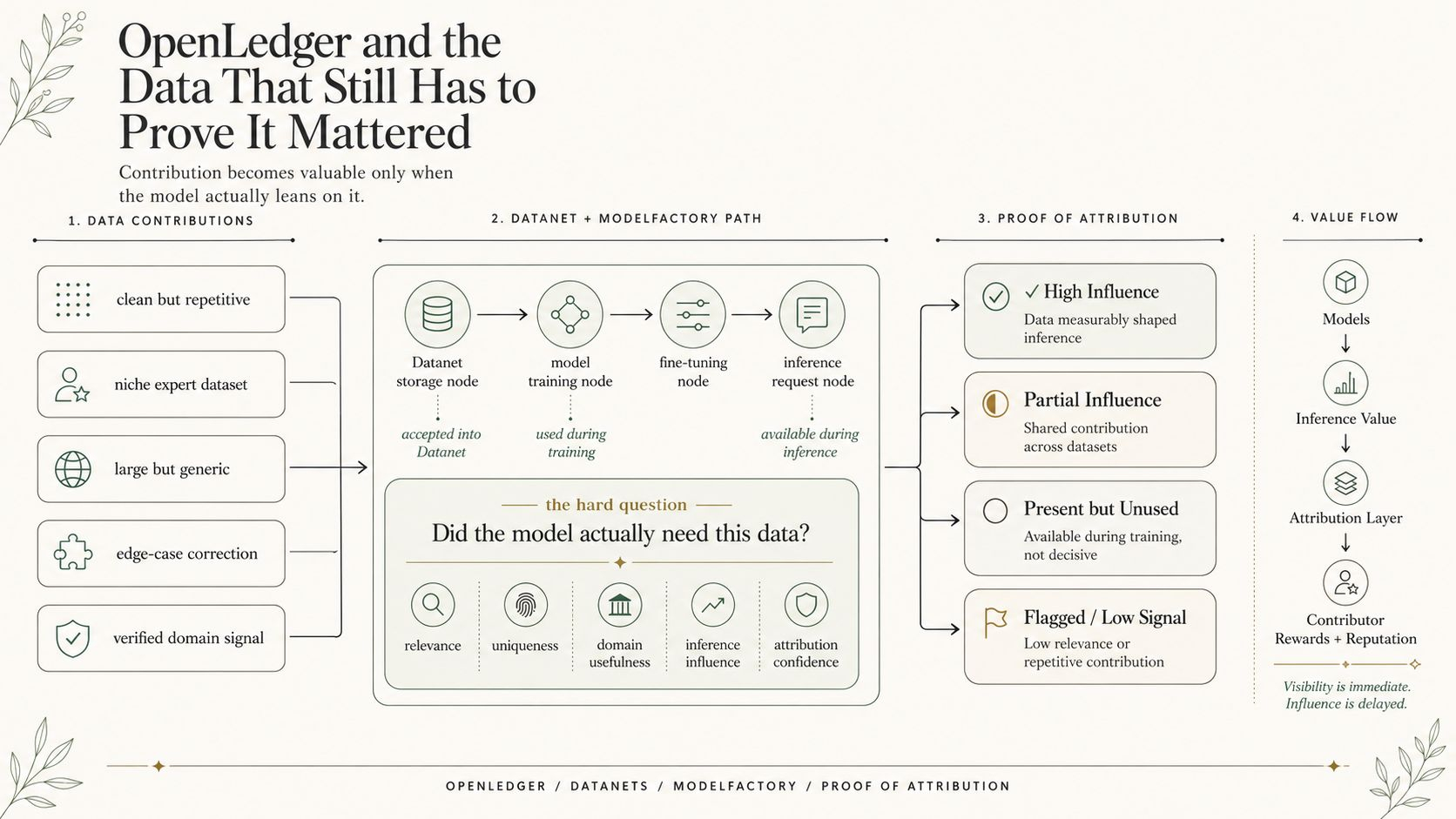
Visnoderīgākie dati dzīvo dīvainā mirušajā zonā pirms apmācības. Tie var būt vērtīgi, bet nav likvīdi. Tie var uzlabot modeli, bet vēl nav novērtēti. Tie var piederēt devējiem, kas saprot domēnu labāk nekā ikviens cits, bet ap tiem parasti nav tīras sistēmas, lai saglabātu šo ieguldījumu redzamu, kad dati ieiet kāda cita AI kaudzes sastāvdaļā.
Tur ir vieta, kur Datanet maina maršrutu.
Nevis maģiski padarot katru datu kopumu vērtīgu. Tas būtu pārāk viegli. Slikti dati joprojām var būt sliktie dati. Pārmērīgi dati joprojām var tur sēdēt, neko nedarot. Devēja ieraksts negarantē pieprasījumu.
Bet tas maina sākotnējo stāvokli.
Dati vairs nav tikai "augšupielādēti." Tie ir izcelsmes.
Ir atšķirība.
Augšupielāde gaida, kad kāds atcerēsies, ka tā eksistē. Izcelsme dod datiem strukturētu ieejas punktu nākotnes modeļa pieprasījumā. Tas izveido pēdas pirms apmācības sākuma, tādējādi, ja dati vēlāk uzlabo modeli, atbalsta aģentu vai veido secinājuma ceļu, devējs netiek izdzēsts no ekonomiskās stāsta.
Tas izklausās mazs, līdz salīdzini to ar normālo AI cauruļu.
Vecajā maršrutā neapstrādāti dati vispirms tiek savākti un novērtēti vēlāk, parasti no puses, kas ir spēcīga pietiekami, lai to centralizētu. Devēji redz pieprasījumu, iesniegumu, varbūt vienreizēju maksājumu, un tad aktīvs pazūd mācību procesā, ko viņi nevar pārbaudīt. Ja modelis kļūst noderīgs, ieguvums pārvietojas prom no izcelsmes.
OpenLedger pirmajā solī cīnās pret to noplūdi.
Datanet kļūst par vietu, kur mācību dati sāk nesatīt atmiņu. Ne cilvēcisko atmiņu. Ekonomisko atmiņu. Ieraksts par to, no kurienes tas nāk, kuram domēnam tas pieder un kā tas vēlāk var savienoties modeļa izveidē, aģenta izpildē un OPEN saistītajos atlīdzību plūsmās.
Tāpēc pirmais likviditātes notikums nav modeļa atbilde.
Tas ir brīdis, kad neapstrādāti dati kļūst pietiekami strukturēti, lai kļūtu atkārtoti izmantojami.
Man tas secinājums sākotnēji nepatika, jo tas šķita mazāk aizraujošs nekā aģents, kas kaut ko dara uz blockchain. Nav redzamas izpildes. Nav dramatiskas iznākuma. Nav tirdzniecības, nav automatizācijas, nav gala atbildes, uz kuru norādīt.
Vienkārši datu kopums ienāk dzelzceļā.
Bet varbūt tieši tas ir tas, ko lielākā daļa cilvēku palaidīs garām.
AI tirgi neizdodas tikai modeļa līmenī. Tie neizdodas agrāk, kad vērtīgi izejmateriāli nav vietējā ceļa uz pieprasījumu. Dati sēž ārpus cenu noteikšanas. Devēji sēž ārpus atribūcijas. Modeļi uzlabojas vēlāk, un neviens nevar skaidri izskaidrot, kuri izcelsmes punkti palīdzēja radīt šo uzlabojumu.
OpenLedger, Datanet ir vieta, kur tas ceļš sāk kļūt šaurāks.
Devējs ne tikai dod sistēmai failus. Viņi ievieto datus AI Blockchain vidē, kur noderīgumu var uzskaitīt uz priekšu, nevis aizmirst atpakaļ. Ja šie dati vēlāk baro ModelFactory, uzlabo specializētu modeli vai kļūst par daļu no aģenta darba plūsmas, sākotnējam ieguldījumam ir labāka iespēja palikt ekonomiski saistītam ar iznākumu.
Ne perfekti. Ne automātiski. Pieprasījumam joprojām ir jānāk.
Tas ir tas, pie kā es turpināju atgriezties.
Datanet var dot datiem identitāti, bet tirgum joprojām ir jāpārbauda, vai dati pelnījuši likviditāti. Struktūra nav tas pats, kas vērtība. Devēja ieraksti nav tas pats, kas izmantošana. OPEN atlīdzības kļūst nozīmīgas tikai tad, kad dati patiešām pārvietojas uz modeļa vai aģenta pieprasījumu.
Un tur ir vieta, kur OpenLedger izcelsmes slānis kļūst interesants.
Tas nenovērtē neapstrādātus datus kā vērtīgus, jo kāds tos augšupielādēja.
Tas dod datiem maršrutu, kur vērtību var atklāt, atkārtoti izmantot, izmērīt un galu galā atlīdzināt, ja ieguldījums izrādās noderīgs AI ekonomikā.
Augšupielāde bija veiksmīga.
Ieraksts eksistēja.
Datanet bija dzīvs.
Bet īstais jautājums tikai sākās.
Nevis "vai dati tika pieņemti?"
Tas jau bija atbildēts.
Grūtāks jautājums bija, vai dati var kļūt pietiekami likvīdi, lai būtu svarīgi pēc izcelsmes, kad modelis, aģents vai secinājuma ceļš beidzot vajadzēja to, ko devējs tur pirmo reizi bija novietojis.
