

AI lietotņu un aģentu nākotne OpenLedger
Temats
Openledger
Birkas
OpenLedger
Pārskats par ierakstu
No specializētiem modeļiem līdz aģentiem, kas var redzēt, racionāli domāt un rīkoties — šis blogs izskaidro, kā OpenLedger nosaka AI aģentu un lietotņu nākotni, ar kontekstu, rīkiem, atmiņu un loģiku, kas integrēta ķēdē.
Mašīnmācības agrīnajos posmos lielākā daļa sistēmu tika veidotas kā monolītiski modeļi, kas tika apmācīti vienreiz un pēc tam 'iesaldēti'. Laika gaitā nozare attīstījās uz smalkāku regulēšanu un uzdevumam specifiskiem variantiem. Šie modeļi ielika pamatu jomas pielāgošanai, bet šodien, lai izveidotu noderīgas AI lietotnes, ir svarīgi 'uzlādēt' modeli, lai tas varētu darīt vairāk.
Jaudīgs modelis ir tikai viena daļa no vienādojuma. Lai AI sistēmas varētu jēgpilni darboties reālajā pasaulē, tām jāizprot savu problēmu telpu, jāinteraktē ar dzīviem datiem, jāiegūst vēsturiskais konteksts un jāizpilda deterministiska loģika. Tieši tāpat kā GPU atklāja apjomu apmācībai, nākamais lēciens ir par interakcijas, atribūcijas un ekonomiskās saskaņas atbloķēšanu lietojumprogrammu slānī.
Šī ir infrastruktūra, ko sniedz OpenLedger.
OpenLedger ir AI blokķēde. Tā nav veidota kā vispārējas lietošanas ķēde, bet kā izpildes un atribūcijas slānis inteliģentām sistēmām. Tā nodrošina substrātu, kur modeļi, dati, atmiņa un aģenti kļūst par savietojamiem komponentiem. Šis emuārs detalizē rīkus, kas paplašinās modeļus, lai ļautu dažādiem aģentiem un lietojumprogrammām pievienot nepieciešamo kontekstu, uzvedību un atmiņu.
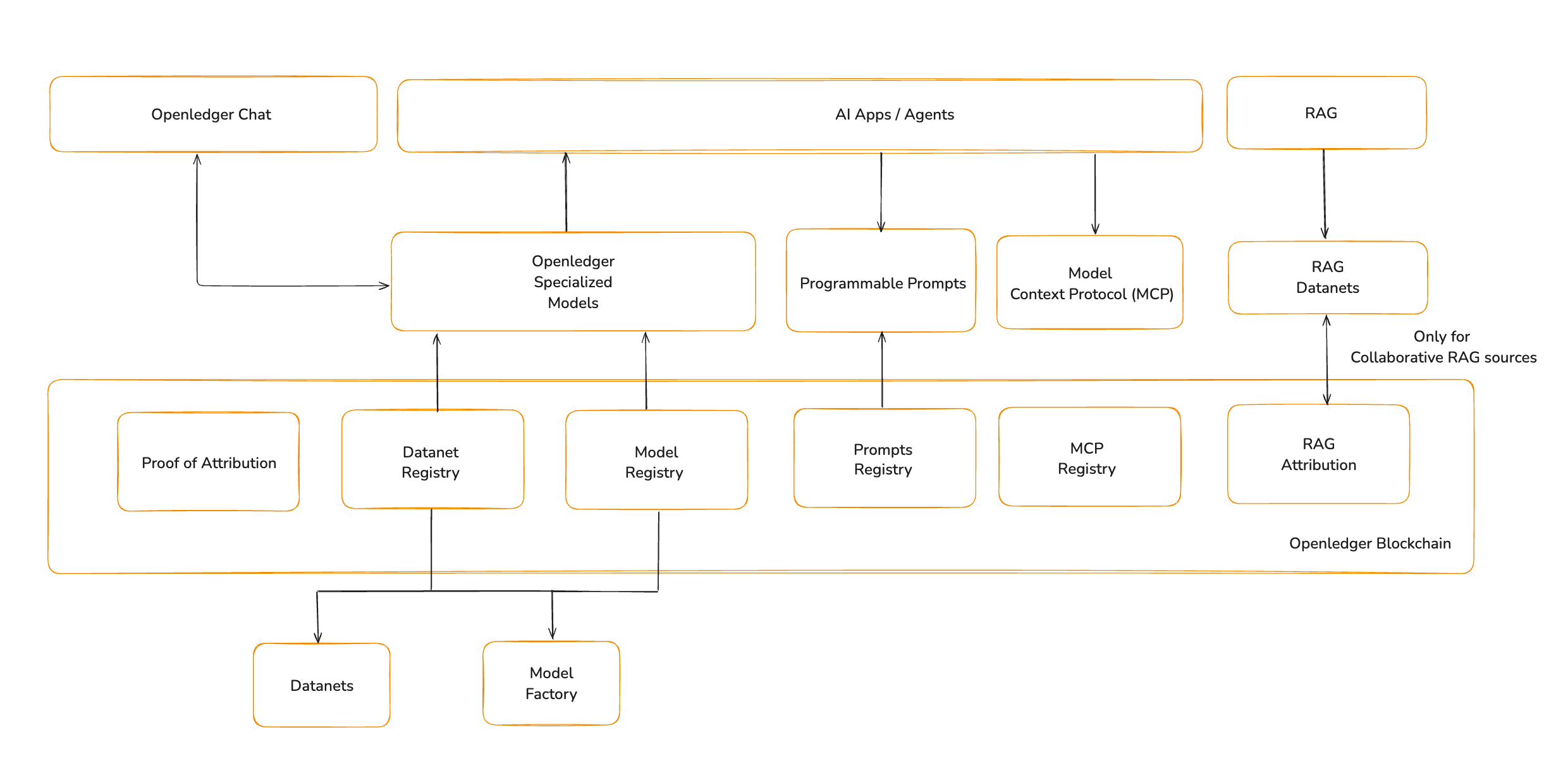
Specializētie modeļi (īsā atkārtošana)
Pamatā jebkurai inteliģentai lietojumprogrammai ir modelis. Vispārīgi modeļi piedāvā elastību, bet, kad tie tiek pielietoti specializētos domēnos, tie ļoti gūst labumu no precizēšanas un pielāgošanas. OpenLedger uzlabo šo procesu, izmantojot veltītu cauruļvadu:
-> Datanets, kas ir kurēti, sadarbīgi un atribūti dati, ko veido kopiena
-> Modeļa fabrika, kas vienkāršo precizēšanu, izmantojot bezkode darba plūsmas
-> OpenLoRA, kas piedāvā izmaksu efektīvas adapteru variācijas, kas var mainīties reālajā laikā, padarot secinājumus vieglus un kompozīcijas veidā.
Šie komponenti ir plaši apspriesti iepriekšējās publikācijās. Tie kalpo kā pamats. Un ar pareizajām paplašinājumiem tie ļauj attīstīties spēcīgiem, inteliģentiem aģentiem.
Modeļa konteksta protokols (MCP)
Lai modelis varētu atvērt failu, izlasīt datu bāzi vai izsaukt rīku, tam ir nepieciešama piekļuve ārējai valstij un kontekstam. Lai dotu modeļiem šo spēju, OpenLedger ievieš Modeļa konteksta protokolu (MCP).
MCP nosaka struktūru, kā piegādāt kontekstu modelim un saņemt strukturētas atbildes, kuras var izpildīt. Tas sastāv no trim daļām: klienta, kas piegādā datus, servera, kas apstrādā rīku izsaukumus, un maršrutētāja, kas pārvalda plūsmu starp tiem.
Praksē MCP jau ir pieņemts sistēmās, piemēram, Cursor, kur aģents var lasīt vietējos failus, rediģēt kodu bāzes un veikt uz rīkiem balstītas darbības attīstības vidē. Rīki, piemēram, 21.dev, darbojas kā MCP klienti, kuri var tikt pievienoti Cursor, lai izveidotu dinamiskas, reāllaika saskarnes. Izmantojot 21.dev, aģenti iegūst iespēju darboties uz dzīviem UI komponentiem, radot rezultātus, kas atspoguļo reāllaika stāvokli ar vizuāli bagātu slāni.
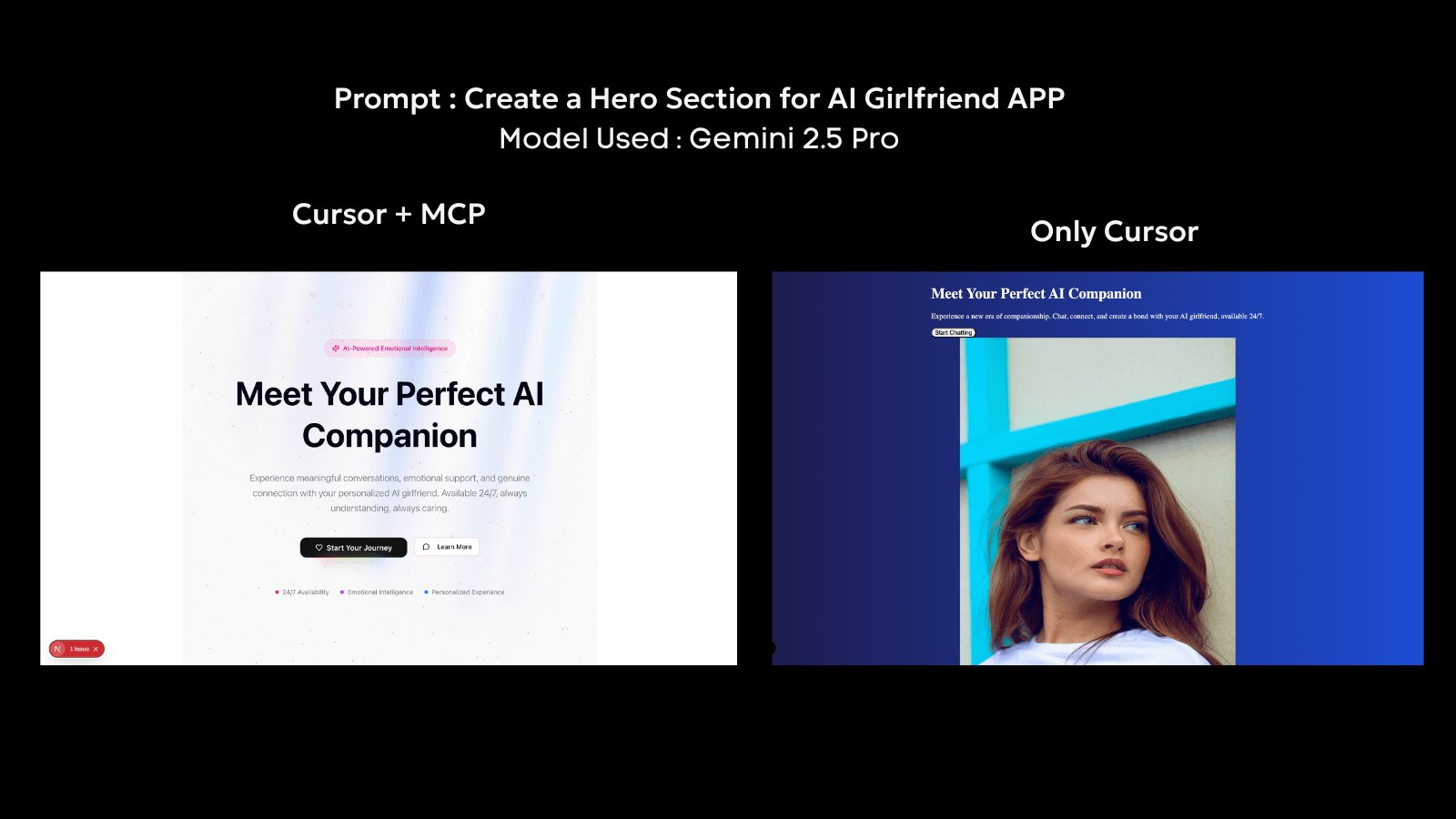
Nākotnes redzējums par MCP ar OpenLedger
OpenLedger iztēlojas MCP attīstību par uz ķēdes reģistru. Katrs MCP rīks var tikt reģistrēts, versiju veidots un atribūts. Rīki kļūst par kompozīcijas komponentiem, ko var izsaukt jebkurš aģents, ar lietojumu, kas tiek reģistrēts un atlīdzināts uz ķēdes. Tas ļauj izstrādātājiem publicēt failu lasītājus, renderētājus vai API klientus, un tos var izsaukt jebkurš OpenLedger bāzēts aģents ar pilnu atribūciju un izsekojamību.
Iegūšanas papildinātā ģenerācija
Dažas zināšanas ir pārāk lielas, pārāk detalizētas vai pārāk bieži atjauninātas, lai tās varētu tieši iekļaut modeļa svaros. Tomēr tās ir pamats racionālai domāšanai. Iegūšanas papildinātā ģenerācija (RAG) paplašina modeļa spējas, ieviešot reāllaika, vaicājumiem specifisku atmiņu.
RAG atdala uzglabāšanu no secinājumiem. Dokumenti tiek iekļauti vektoros, indeksēti semantiski un iegūti izpildes laikā atbilstoši lietotāja vaicājumam. Iegūtā saturs tiek ievietots pieprasījuma logā, nostiprinot modeļa atbildi.
Šī metode ir īpaši nozīmīga domēnu specifiskiem aģentiem. Aģents, kas apmācīts izprast konkrētu domēnu, var piekļūt emuāru ierakstiem, dokumentācijai, priekšlikumiem un kopienas diskusijām. Vēlējoties nevis iegaumēt visu šo saturu, tas veic pieprasījumu uz RAG sistēmu, kas veidota no uzticamiem avotiem. Atbilde ir precīza, aktuāla un balstīta uz reāliem pierādījumiem. Šī struktūra ļauj aģentiem izvairīties no halucinācijām, vienlaikus ļaujot viņiem meklēt, iegūt un racionāli domāt par dinamisku saturu.
Nākotnes redzējums par RAG ar OpenLedger
OpenLedger paplašina RAG par sadarbīgu un atribūtu slāni. Tieši tāpat kā ar datu kopām un modeļiem, katrs dokuments, kas glabājas RAG indeksā, tiek atribūts tā dalībniekam. Kad dokuments tiek iegūts, šī lietošana tiek reģistrēta. Tas pārveido RAG no atmiņas sistēmas par stimulu mehānismu.
Nākotnē dalībnieki varēs reģistrēt dokumentus uz ķēdes kā daļu no sadalītā zināšanu grafika. Katrs iegūšanas notikums izsauks mikro-attribūcijas, radot caurspīdīgu kredīta un ekonomiskās vērtības plūsmu, kas saistīta ar informatīvo ietekmi.
OpenLedger bāzēts aģents, kas apmācīts uz platformas specifiska satura, piemēram, emuāru ierakstiem, dokumentācijām, pārvaldības priekšlikumiem un lietotāju sarunām, nevarēs iegaumēt visu kontekstu. Tas var pieprasīt decentralizētu RAG sistēmu, kas veidota no pārbaudītiem kopienas avotiem. Katrs iegūtais spans saista atpakaļ ar tā autoru, ļaujot atlīdzību sadali pat secinājumu laikā.
Ar OpenLedger infrastruktūru, RAG kļūst par sistēmu pārbaudāmai, stimulētai racionālai domāšanai. Katrs paragrāfs, citāts vai datu punkts var tikt izsekots, atkārtoti izmantots un monetizēts tādā veidā, kas atspoguļo patiesu ietekmi aģentu ekosistēmā.
Pieprasījumi kā uzvedības loģika
Inteliģenta aģenta pēdējais slānis ir tā uzvedība. Tas nav kodēts svaros vai datos. Tas tiek definēts, izmantojot pieprasījumus.
Pieprasījums strukturē mijiedarbību. Tas norāda modelim, kā domāt, kā formatēt tā iznākumu un kādas ierobežojumus ievērot. Tas darbojas kā loģikas slānis, kas nosaka, kā ieejas tiek interpretētas un kā rīki tiek izsaukti. Sarežģītos aģentos pieprasījumu dizains nav vienreizēja instrukcija. Tas var ietvert struktūrētu veidlapu ķēdes, dinamiskus konteksta laukus un plānošanas instrukcijas.
Pieprasījumu inženierija ļauj izstrādātājiem definēt aģenta uzvedību, nemainot pašu modeli. Ar pareizu dizainu aģenti kļūst deterministiski savos racionālos soļos. To iznākumi paliek konsekventi, rīku izmantošana ir ierobežota, un atbildes atspoguļo gan doto kontekstu, gan paredzēto mērķi.
Nākotnes redzējums par pieprasījumiem ar OpenLedger
OpenLedger uztver pieprasījumus kā programmējamos aktīvus. Nākotnē tas var novest pie viedo līgumu standarta pieprasījumiem, ļaujot tos izvietot, versiju veidot un tieši atsaukt uz ķēdes. Pieprasījumi kļūs par pirmās klases celtniecības blokiem aģentu izstrādē, ar atribūciju un atkārtotu izmantošanu, kas ir iekļauta to dizainā.
Pieprasījumu reģistrs uz OpenLedger ļautu izstrādātājiem izveidot un publicēt atkārtoti izmantojamus paraugus, kas saistīti ar konkrētām darbībām, rīkiem vai modeļiem. Šie paraugi varētu tikt saistīti ar aģentiem, atjaunināti laika gaitā un monetizēti, pamatojoties uz lietojumu.
Katrs pieprasījums, ko izmanto aģents, var tikt izsekots atpakaļ uz tā autoru. Atribūcija tiks īstenota infrastruktūras līmenī, ļaujot godīgas atlīdzības, caurspīdīgas koordinācijas un uzvedības līmeņa savietojamības nodrošināšanu aģentu vidū. Pieprasījumi vairs nebūs statiski virknējumi, bet dinamiskas, pārbaudāmas inteliģento sistēmu komponentes.
Piemēra izpēte: Kopienas apmācīta tirdzniecības aģenta izveide uz OpenLedger
Tā ir veids, kā var izveidot īstu tirdzniecības aģentu, izmantojot OpenLedger. Tas sākas ar datiem, veido modeli, pievieno dzīvus rīkus un pārvēršas par strādājošu lietojumprogrammu.
1. solis: Kopienas datu vākšana
Process sākas ar Datanet. Datanet ir kopienas datu sadarbības platforma. Tirgotāji no Discord, Twitter un citām kopienām ievada tirdzniecības stratēģijas, grafiku anotācijas, tokenu analīzi un tirdzniecības lēmumus. Datanet īpašnieks pārskata un apstiprina katru iesniegumu. Kad tas ir apstiprināts, dati tiek pievienoti Datanet un kļūst par daļu no augoša instrukciju datu kopuma. Katrs dalībnieks tiek reģistrēts uz ķēdes.
2. solis: Apmācīt specializētu modeli
Izmantojot pārbaudītos datus no Datanet, modelis tiek precizēts, lai izprastu tirdzniecības modeļus, kā tirgotāji domā un kā tiek pieņemti lēmumi. Modelis tiek izvietots, izmantojot OpenLoRA. Tas notur modeli vieglu, lētāku darbībā un viegli atjaunināmu.
3. solis: Pievienot reāllaika kontekstu ar MCP
Aģentam nepieciešami dzīvi tirgus dati, lai pieņemtu lēmumus. Izmantojot Modeļa konteksta protokolu (MCP), tas savienojas ar:
-> CoinMarketCap par tokenu cenām
-> Binance un Coinbase reāllaika tirdzniecībām
-> Kaito par populārajām domām Twitter
-> Uniswap vai PancakeSwap par uz ķēdes likviditāti
Katrā reizē, kad rīks tiek izmantots, atribūcija tiek reģistrēta uz ķēdes.
4. solis: Izmantot RAG tirgus atmiņai
Aģentam arī nepieciešams vēsturiskais konteksts. Izmantojot Iegūšanas papildināto ģenerāciju (RAG), tas iegūst informāciju, piemēram:
-> Tokenu baltās grāmatas
-> DAO priekšlikumi
-> Pārvaldības lēmumi
-> Emisijas grafiki
-> Iepriekšējo izsistību vai lielo notikumu ieraksti
Tas dod aģentam pilnu fona zināšanu par analizētajiem tokeniem.
5. solis: Definēt aģenta noteikumus kā pieprasījumus
Pieprasījumi norāda aģentam, kā apvienot visus datus un pieņemt lēmumus. Aģents pārbauda cenas, likviditāti, noskaņojumu un tokenu vēsturi.
-> Ja noskaņojums ir augsts, bet pārvaldība ir vāja vai ir bijušas iepriekšējas problēmas, tas uzrāda augstu risku.
-> Ja svārstīgums ir augsts un noskaņojums nav skaidrs, tas gaida.
-> Ja pamati un noskaņojums ir stipri, tas norāda uz iespējamu ieiešanu.
Pieprasījumi ir versiju veidoti, atkārtoti izmantojami un pilnībā atribūti.
6. solis: Atribūcija viss uz ķēdes
Katrs datu kopums, rīks, pieprasījums un dokuments, ko izmanto aģents, tiek reģistrēts uz OpenLedger. Dalībnieki automātiski saņem kredītu, kad viņu darbs iedarbina aģenta lēmumu.
Rezultāts
Kopienas dati kļūst par pilnībā funkcionējošu tirdzniecības aģentu. Tas lasa dzīvos tirgus, izprot tokenu vēsturi, piemēro racionālu domāšanu un pieņem skaidrus lēmumus. Viss, ko tas dara, ir caurspīdīgs, izsekojams un atlīdzina katru iesaistīto dalībnieku. Tā ir veids, kā aģenti tiek veidoti uz OpenLedger.
