
Dažas sarunas paliek prātā ilgāk, nekā gaidīts.
Pāris dienas atpakaļ es devos prom agri uz slimnīcu aizņemtā rīta maiņā. Ceļi bija neparasti klusi, un, godīgi sakot, mana domas jau bija koncentrējušās uz pacientu ziņojumiem, iecelšanām un garo grafiku priekšā. Kā katru normālu dienu, es domāju, ka vissvarīgākās diskusijas notiks operāciju telpās vai konsultāciju kabīnēs.
Bet pārsteidzoši, viena no interesantākajām sarunām par AI un blockchain notika pacienta istabā.
Rutīnas pārbaudē viens no maniem regulārajiem pacientiem pamanīja, kā es pārlūkoju kripto pētījumu rakstus savā telefonā, kamēr gaidīju ziņojumus.
Viņš smaidīja un jautāja man:
“Doktor, vai jūs esat dzirdējuši par OpenLedger?”
Es paskatījos uz viņu un atbildēju neformāli: “AI projekts?”
Viņš uzreiz piekrita.
Tas viens mazais jautājums lēnām pārvērtās dziļā diskusijā par to, kā AI sistēmas tiek būvētas, kurš patiesībā pie tām piedalās un kāpēc lielākā daļa dalībnieku nekad nesaņem atzinību.
Pacients paskaidroja kaut ko, kas patiesi piesaistīja manu uzmanību.
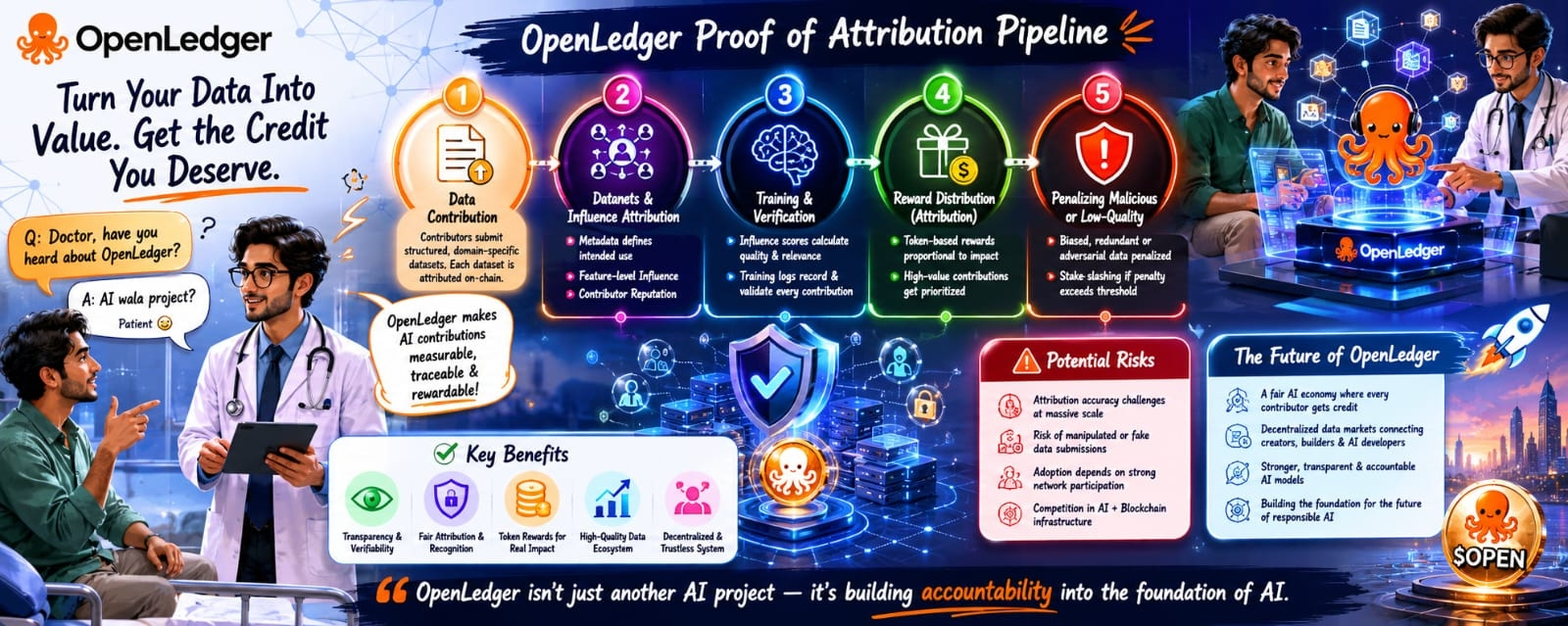
“Šodien AI modeļi tiek apmācīti, izmantojot milzīgas datu masas no cilvēkiem visur. Bet vai kāds patiešām var pierādīt, kuru datu kopums palīdzēja modelim kļūt gudrākam?”
Godīgi sakot, tas jautājums palika manā galvā.
Jo jo vairāk es par to domāju, jo loģiskāk tas izklausījās.
Lielākā daļa mūsdienu AI sistēmu darbojas kā neredzami melnie kastes. Dati ieiet, modeļi tiek apmācīti, rezultāti iznāk, bet dalībnieki pilnībā izzūd no procesa. Neviens īsti nezina, kuri datu kopumi radīja vislielāko vērtību vai ietekmēja galīgo intelektu.
Tad saruna pārgāja uz OpenLedger un tā Atribūcijas pierādījumu sistēmu.
Es viņam tieši jautāju: “Kā OpenLedger atšķiras no citiem AI projektiem?”
Viņš atbildēja ar ļoti vienkāršu atbildi:
“OpenLedger cenšas padarīt AI ieguldījumus izmērāmus, izsekojamus un atlīdzināmus.”
Un, godīgi sakot, šis skaidrojums vienkāršoja visu.
Ideja aiz OpenLedger šķiet pārsteidzoši praktiska, kad to pareizi saproti.
Kad dalībnieki iesniedz strukturētus datu kopumus AI apmācībai, šie ieguldījumi tiek saistīti blokķēdē. Tā vietā, lai kļūtu neredzami pēc iesniegšanas, dati paliek pārbaudāmi un pastāvīgi ierakstīti.
Vienkāršiem vārdiem sakot, OpenLedger cenšas atbildēt uz svarīgu jautājumu:
Kas patiesībā palīdzēja apmācīt inteliģenci?
Šī koncepcija vien pati šķiet spēcīga.
Kamēr mēs turpinājām diskutēt, iznāca vēl viens interesants temats: ietekmes atribūcija.
Es jautāju viņam: “Bet kā sistēma zina, vai dati patiešām bija noderīgi?”
Viņš paskaidroja, ka OpenLedger mēra funkciju līmeņa ietekmi. Praktiski tīkls novērtē, cik daudz konkrēts datu kopums palīdz uzlabot modeļu rezultātus.
Tas maina visu stimulu struktūru.
Parasti AI sistēmas atlīdzina mērogu. Vairāk datu parasti nozīmē lielāku nozīmīgumu.
Bet OpenLedger šķiet, ka koncentrējas uz kvalitātes un atbilstības atlīdzību.
Dalībnieki ar uzticamiem vēsturiskajiem iesniegumiem un spēcīgākām reputācijām laika gaitā iegūst augstāku uzticamību. Vērtīgi datu kopumi saņem labākas atlīdzības, kamēr zemas kvalitātes ieguldījumi kļūst mazāk nozīmīgi.
Šajā brīdī pat es sāku redzēt, kāpēc šī arhitektūra ir svarīga decentralizētā AI nākotnei.
Bet katrai sistēmai ir riski.
Tātad, protams, es uzdevu nākamo jautājumu:
“Kas liedz cilvēkiem augšupielādēt surogātdatus, manipulētus vai subjektīvus datu kopumus, lai tikai iegūtu atlīdzību?”
Tas, iespējams, bija vissvarīgākais mūsu sarunas moments.
OpenLedger iekļauj soda sistēmas ļaunprātīgiem ieguldījumiem. Ja datu kopumi tiek atzīti par pretinieciskiem, liekiem vai kaitīgiem, dalībnieki var saskarties ar daļas samazināšanu un samazinātām nākotnes atlīdzībām.
Godīgi sakot, es domāju, ka šis mehānisms ir nepieciešams.
Jo decentralizēts AI bez atbildības var ļoti ātri kļūt bīstams.
Kā ārstiem, mums jau ir skaidrs, cik jutīga ir datu integritāte. Pat nelielas neprecizitātes veselības aprūpes sistēmās var radīt nopietnas sekas. Tā pati loģika attiecas uz AI apmācības infrastruktūru.
Laba inteliģence nevar tikt būvēta uz neuzticamiem datiem.
Pacients tad teica kaut ko, kas patiesi likās man apstāties uz brīdi.
“Doktor, nākotnē dati var kļūt vērtīgāki par darbu pašu.”
Tā rinda šķita dziļāka par vienkāršu kripto diskusiju.
Jo AI attīstās ātri, un galu galā atribūcija kļūs par galveno jautājumu visā pasaulē. Uzņēmumi, radītāji, pētnieki un dalībnieki visi vēlēsies pierādījumus par to, kā inteliģence tika izveidota un kam pienākas ekonomiskā vērtība no tās.
OpenLedger šķiet, ka pozicionē sevi šai nākotnei.
Protams, projekts joprojām nes sev līdzi nenoteiktību.
Atribūcijas novērtēšana mērogā ir tehniski sarežģīta. Ietekmes mērīšana lielās AI sistēmās nav viegla pat centralizētiem uzņēmumiem ar milzīgiem resursiem. Pieņemšana ir vēl viens izaicinājums, jo decentralizētas ekosistēmas izdodas tikai tad, ja pietiekami daudz izstrādātāju un dalībnieku aktīvi piedalās.
Konkurence AI kripto infrastruktūrā arī strauji pieaug.
Bet neskatoties uz riskiem, es domāju, ka pamatideja aiz OpenLedger patiešām ir svarīga.
Tas, kas mani visvairāk pārsteidza, nebija hype, mārketings vai cenu spekulācijas.
Tas bija arhitektūra.
Projekts cenšas ieviest caurspīdīgumu nozarē, kurā dalībnieki parasti ir neredzami. Tā vietā, lai izturētos pret datiem kā pret brīvu degvielu AI sistēmām, OpenLedger tos uzskata par izmērāmu ekonomisko vērtību.
Un, godīgi sakot, pēc šīs sarunas slimnīcā, es sāku skatīties uz AI infrastruktūru ļoti savādāk.
Dažreiz nozīmīgākās diskusijas notiek nevis konferencēs, tirdzniecības vietās vai pētījumu pasākumos.
Dažreiz tie notiek klusi normālas slimnīcas pārbaudes laikā, kad viens vienkāršs jautājums negaidīti atver durvis uz daudz lielāku nākotni.
