Kāpēc dati kļūst vērtīgi tikai pēc tam, kad kāds cits tos jau ir izmantojis?
Šis jautājums mani nemitīgi moka iekš OpenLedger.
Ne tāpēc, ka modeļu slānis nav svarīgs. Tas ir svarīgs. ModelFactory, inferenču pieprasījums, aģenti, OPEN atlīdzības, visa šī maršruta nozīme ir liela. Bet es joprojām tiekos piesaistīts atpakaļ, pirms modelis sniedz atbildes, pirms aģents rīkojas, pirms ikviens var norādīt uz tīru lietošanas notikumu un teikt, jā, šis ieguldījums radīja vērtību.
Dīvainā daļa sākas agrāk.
Neapstrādāti dati parasti ienāk AI tirgos ar gandrīz nekādu ekonomisko formu. Ieguldītājam var būt reta nozares zināšana, vietējie ieraksti, nišas uzvedības dati, tirgus novērojumi, pētījumu piezīmes vai kāds neglīts, bet noderīgs datu kopums, ko neviens cits nav apgrūtinājis strukturēt. Bet pirms tas nonāk modelī, tas atrodas mirušajā zonā. Vērtīgs, varbūt. Likvīds, ne gluži.
Te ir vieta, kur OpenLedger Datanets kļūst interesantāki, nekā tie sākumā izskatās.
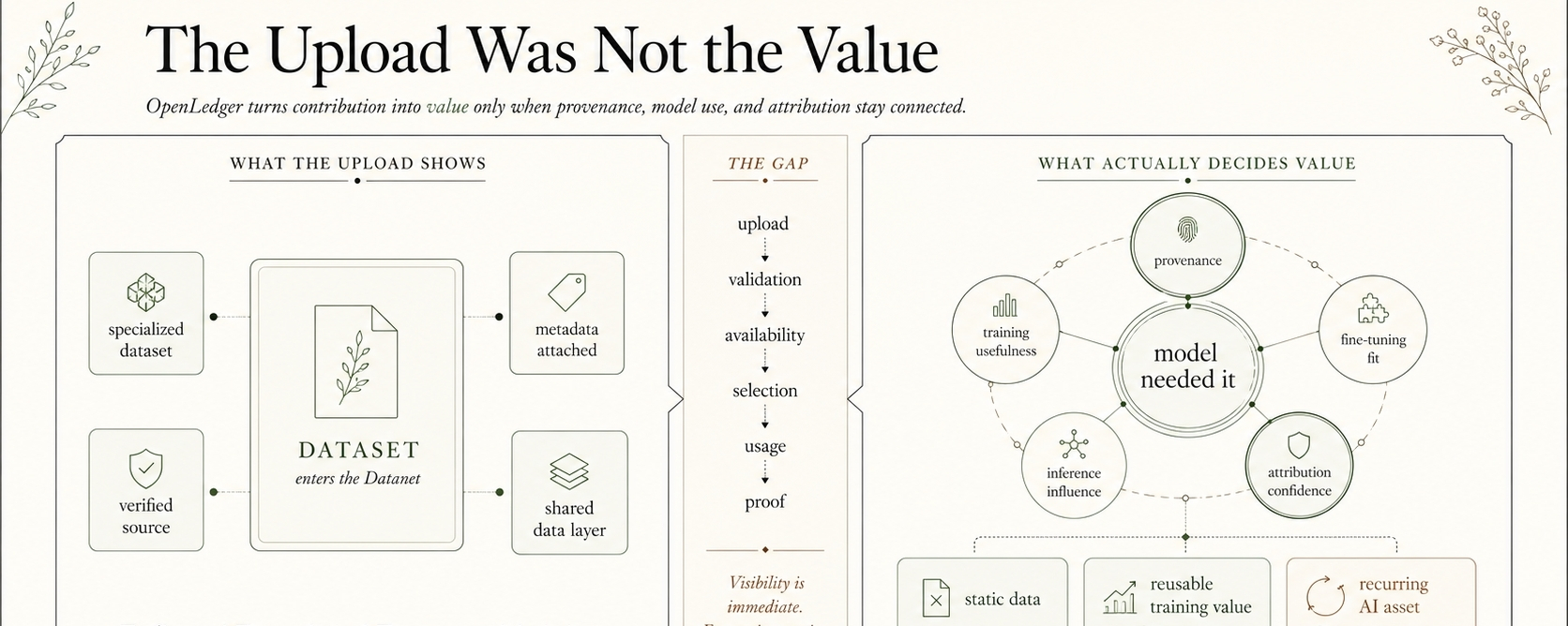
Datanets nav tikai vieta, kur novietot failus. Tas pārvērš datu ievadi par izcelsmes momentu. Līdzdalībnieks ne tikai augšupielādē materiālu; viņš rada izsekojamu sākumpunktu nākotnes AI pieprasījumam. Šī atšķirība šķiet maza, līdz atlīdzības sāk kustēties.
Jo, kad OPEN saistītas atlīdzības nonāk maršrutā, jautājums mainās.
Tas vairs nav: vai kāds iesniedza datus?
Tas kļūst: vai šie konkrētie dati pelnīja kļūt par daļu no ekonomiskā ceļa?
Tas ir grūtāk.
Datanets var padarīt izcelsmi redzamu, bet redzamība nav tas pats, kas vērtība. Līdzdalībnieku ieraksti var parādīt, kurš ievadījis ko, bet ieraksts pats par sevi nevar pierādīt, ka dati ir bijuši svarīgi. Varbūt datu kopums kļūst noderīgs ModelFactory apmācībā. Varbūt tas uzlabo šauru modeli. Varbūt aģents vēlāk paļaujas uz šo modeli izpildes laikā. Varbūt pieprasījums pēc secinājumiem beidzot to sasniedz.
Vai varbūt nekas nenotiek.
Šī nenoteiktība ir viss punkts.
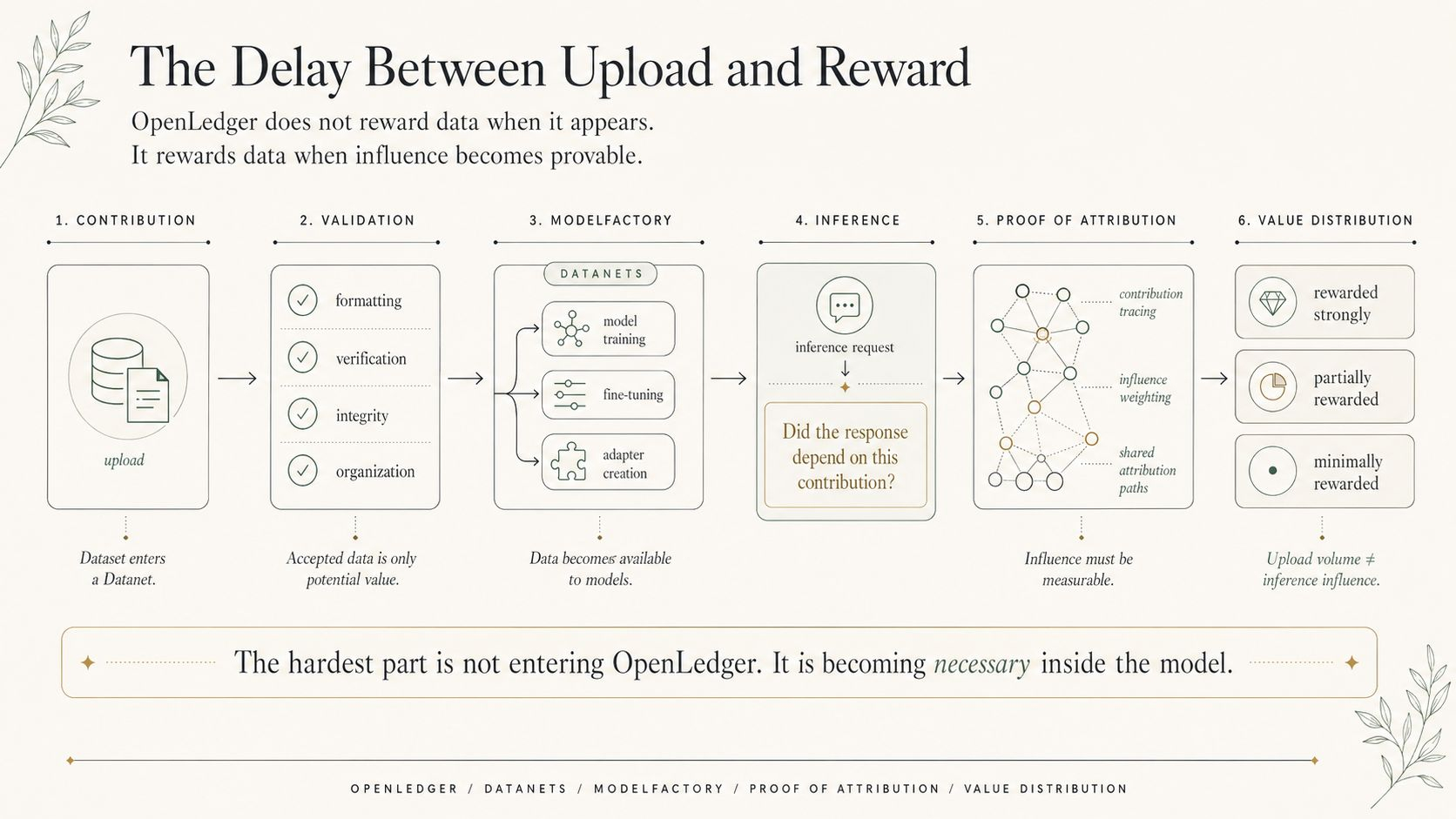
OpenLedger cenšas radīt likviditāti ap datiem, modeļiem un aģentiem, taču datu likviditāte nevar sākties tikai ar galīgo atbildi. Ja vērtība tiek atklāta tikai pēc tam, kad modelis kļūst noderīgs, līdzdalībnieks jau ir nokavējis savu izdevīgumu. Sistēmai ir nepieciešams veids, kā atcerēties izcelsmi, pirms noderīgums kļūst acīmredzams.
Tas ir tas, ko nosaka Datanet izcelsme.
Bet es neesmu pārliecināts, vai grūtā daļa ir vienkārši "izsekot datiem". Izsekošana ir vieglāka stāsta daļa. Neērta daļa ir lietderības rangs pirms visi piekrīt, ka lietderība eksistē.
Kas notiek, kad divi līdzdalībnieki iesniedz pārklājošus datus? Vai agrākais līdzdalībnieks pelnījis vairāk, jo viņš pirmo reizi izveidoja maršrutu? Vai tīrāka, strukturētāka versija pelnījusi vairāk, jo modelis to var tiešām izmantot? Ja neliels datu kopums uzlabo konkrēta aģenta darba plūsmu vairāk nekā liels vispārējs datu kopums, vai atlīdzību sistēma atpazīst signāla blīvumu, vai tikai redzamo apjomu?
Tas jau man kaut ko saka.
OpenLedger neapstrādāti dati nekļūst par AI-native aktīvu tikai tāpēc, ka tie iekļūst Datanetā. Tie kļūst par tādiem tikai tad, kad sistēma var savienot izcelsmi, atkārtotu izmantošanu un pieprasījumu, neizdzēšot līdzdalībnieku starpā.
Un šī saikne ir trausla.
Atribūcijas pierādījums var palīdzēt izlemt, vai dati ietekmēja modeli, bet pati ietekme ir neskaidra. Datu kopums var netieši veidot apmācību. Tas var kļūt noderīgs tikai pēc apvienošanas ar citiem Datanetiem. Tas var atbalstīt OpenLoRA adapteri, kas vēlāk kalpo specializētam aģentam. Līdz brīdim, kad secinājuma notikums rada ekonomisko vērtību, oriģinālā ieguldījuma var būt vairāki slāņi aiz redzamā rezultāta.
Te ir, kur datu izcelsme kļūst vairāk nekā uzglabāšanas problēma.
Tas kļūst par tirgus dizaina problēmu.
Ja OpenLedger atlīdzina tikai acīmredzamu izmantošanu, līdzdalībnieki var optimizēt datus, kas izskatās uzreiz mērojami. Ja tas pārāk viegli atlīdzina neapstrādātas iesniegšanas, zemas kvalitātes vai dublēti dati var pārpludināt sistēmu. Ja atribūcija kļūst pārāk stingra, slēpti, bet svarīgi dati tiek par maz apmaksāti. Ja tā kļūst pārāk vaļīga, atlīdzību pieprasījumi sāk novirzīties no reālās ietekmes.
Te nav tīras iestatīšanas.
Roberts šķiet nestabils, jo OpenLedger ne tikai jautā, vai dati eksistē. Tas jautā, vai dati var iekļūt AI blokķēdē ar pietiekamu identitāti, lai vēlāk kļūtu likvīdi, noderīgi un ekonomiski atbildīgi.
Tas ir daudz grūtāk pierādīt.
Varbūt Datanets ir pirmā vieta, kur neapstrādāti dati pārstāj būt pasīvi. Nevis tāpēc, ka katrs datu kopums pēkšņi iegūst vērtību, bet tāpēc, ka sistēma dod tam ceļu uz modeļa pieprasījumu pirms centralizēts laboratorija uzsūc peļņu. Līdzdalībnieku ieraksts kļūst par pirmo ekonomisko rokturi. OPEN atlīdzības kļūst par vēlākā pārbaudījuma testu. ModelFactory un aģenti kļūst par pieprasījuma virsmu.
Tomēr es turpinu atgriezties pie tās pašas problēmas.
Izcelsme var reģistrēt, no kurienes dati nāk.
Bet vai OpenLedger var pierādīt, kuri dati pelnīja likviditāti pirms atlīdzības sāk kustēties?