The more time I spend looking into AI infrastructure, the more I keep noticing the same pattern. Almost every project wants our attention fixed on the final outcome the polished model, the smooth interface, the impressive output. Everything is designed to keep the conversation centered around what the system can produce. But the more I think about it, the more it feels like the most important part often gets buried underneath all of that: what the system had to absorb, coordinate, and depend on before that output ever reached us.
Honestly, that is the part I think most people rarely stop to question. Maybe because modern AI has been designed to feel effortless. You type something, a response appears, and the interaction ends there. It feels seamless enough that we rarely think about everything hidden beneath it — the datasets that shaped it, the contributors behind it, and the validation layers filtering what enters the system. Somewhere along the way, we became comfortable treating intelligence as if it simply appears on demand.
That has started feeling strangely incomplete to me.
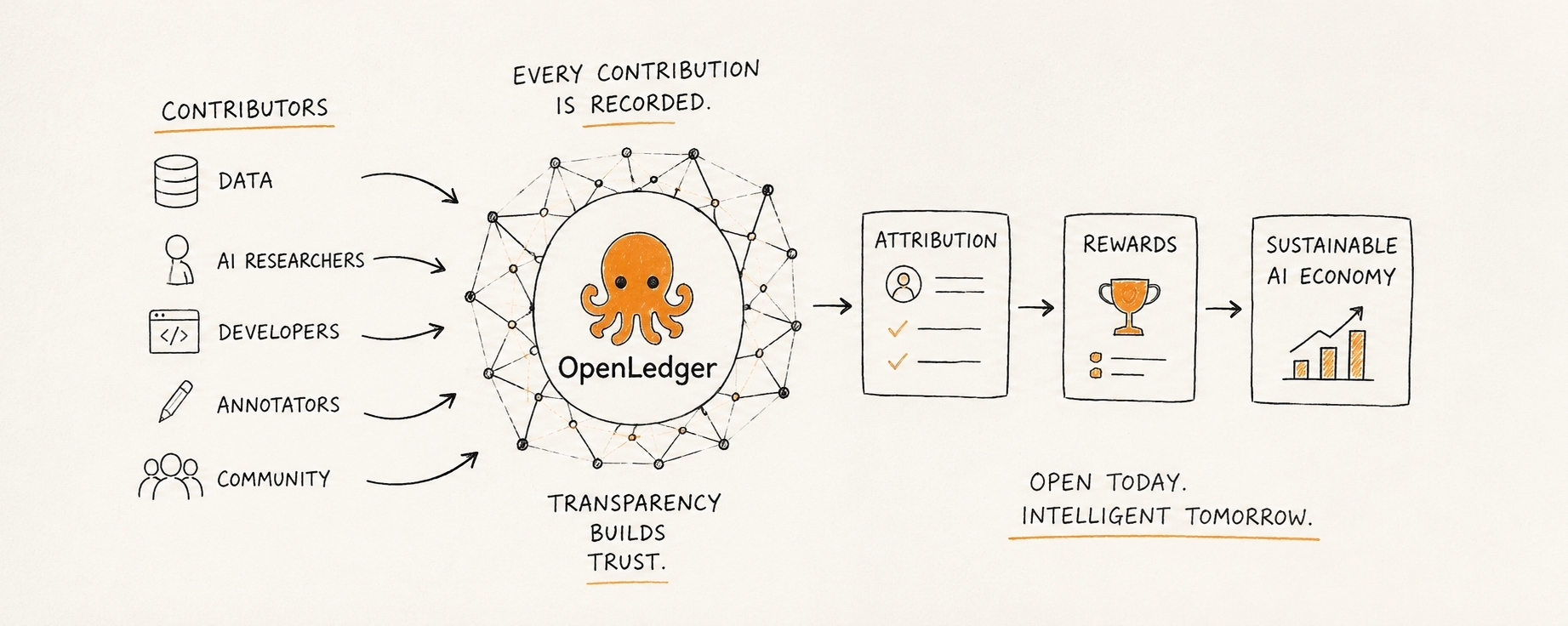
That is probably why OpenLedger stayed on my mind longer than I expected. Not because it promises louder intelligence, and not because it is chasing the usual “faster, smarter, bigger” narrative every AI project seems to lean on. What caught my attention is that it seems focused on something most systems quietly abstract away: the accounting layer beneath intelligence itself.
Most AI systems today feel endpoint-optimized. You ask, it answers, and you move on. The process behind that answer becomes almost irrelevant. OpenLedger feels like it is challenging that assumption entirely. It seems built around the idea that intelligence should not arrive detached from the path that created it, that contribution should remain visible, and that inference should carry lineage.
And in my point of view, that is exactly where the project becomes genuinely interesting.
Because if AI eventually starts generating repeated economic value, then hidden contribution layers quietly become hidden extraction layers too. I do not mean that in a dramatic way. Sometimes abstraction is simply the easiest way to scale. But scale has a habit of making invisible incentives harder to question over time.
That is where OpenLedger feels different. It does not seem interested in removing complexity. It seems willing to expose it through datanets, attribution mechanics, traceable inference pathways, and reward coordination. None of these things make AI feel lighter. If anything, they make the whole system feel heavier, more exposed, and more structurally honest.
I am still not fully convinced that automatically becomes an advantage. Open contribution systems always come with tension. The moment incentives become visible, optimization begins. Quality becomes harder to protect, and coordination becomes harder to sustain. Those are real structural pressures every open system eventually has to confront.
Still, I find visible complexity far more interesting than invisible complexity. At least visible systems can be questioned. Invisible ones usually cannot.
That is what keeps pulling my attention back to OpenLedger. It feels less like a project trying to simplify AI into another polished product narrative and more like an attempt to expose the machinery most systems would rather keep hidden.
And that leaves me thinking about one question:
If intelligence begins creating real economic value at scale, how long can the systems producing that value afford to remain invisible?
@OpenLedger #OpenLedger #openledger $OPEN
