

Okay... I'll be honest. First time I sat with OpenLedger’s agent stack, I thought the ugly version was bad attribution.
The ugly version isn't bad attribution.
It is Datanet slice being wrong on Monday and still feeding the agent on Friday because everything looked traceable enough on Tuesday.
That's the OpenLedger problem I keep circling around.
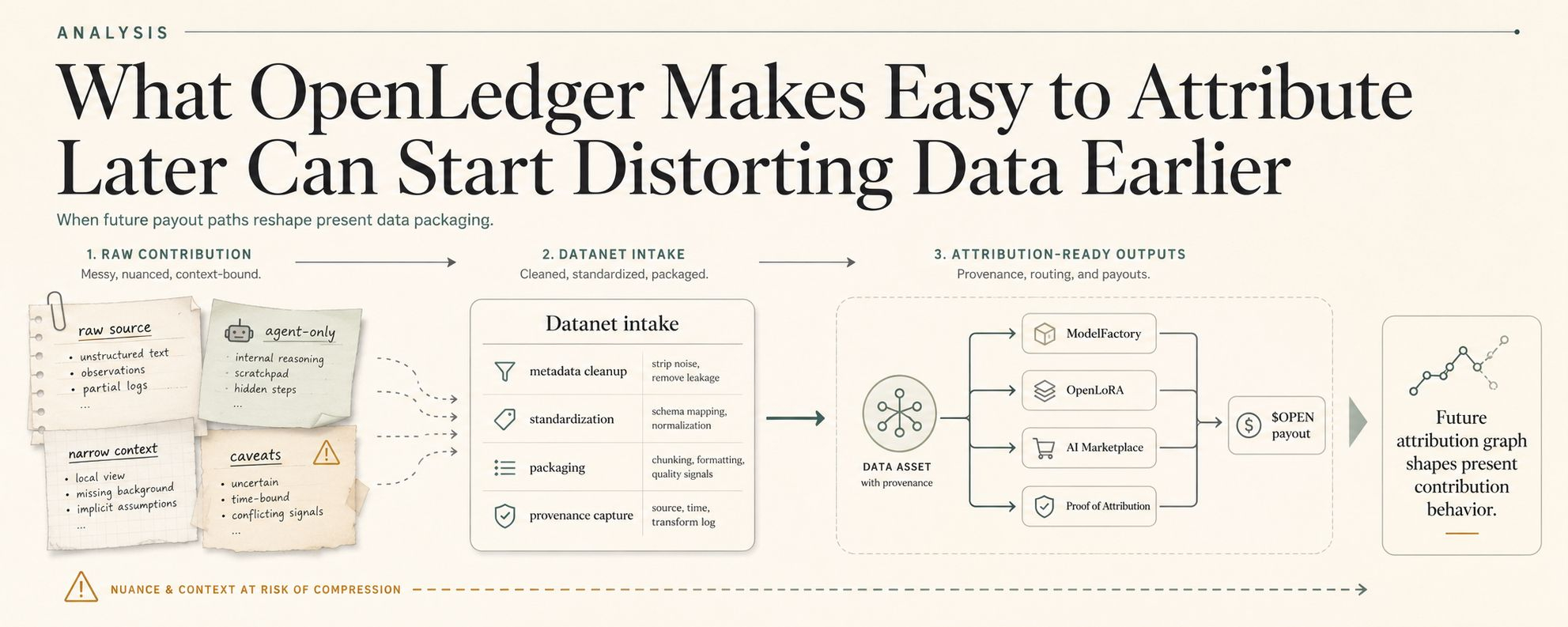
Not the nice version. Not the one where Datanets finally give AI workflows cleaner source paths, where PoA can show what shaped an output, where OpenLoRA can make specialized adapters cheaper to serve, where ModelFactory lets builders package an agent without duct-taping infrastructure together at 2 a.m. Good. OpenLedger should do that. Centralized AI was always a little obscene once the thing being used stopped being generic text and started being actual operational judgment.
The worse version is calmer.
A Datanet feeds the run.
The adapter serves cleanly.
The agent answers.
PoA traces the contribution.
The marketplace route, or maybe an @OpenLedger OctoClaw action path, keeps moving.
And the assumption underneath can still be stale, narrow, or just dumb in a very expensive way.
That’s the part people don’t like sitting with.
Because OpenLedger makes specialized automation viable. That is one of its real strengths. You can encode a useful agent around niche source material, attach it to a Datanet, run a specialized adapter path, trace what contributed, and turn the result into something users or other workflows can actually consume. Good. Fine. Useful.
It also means the mistake doesn’t have to be loud anymore.
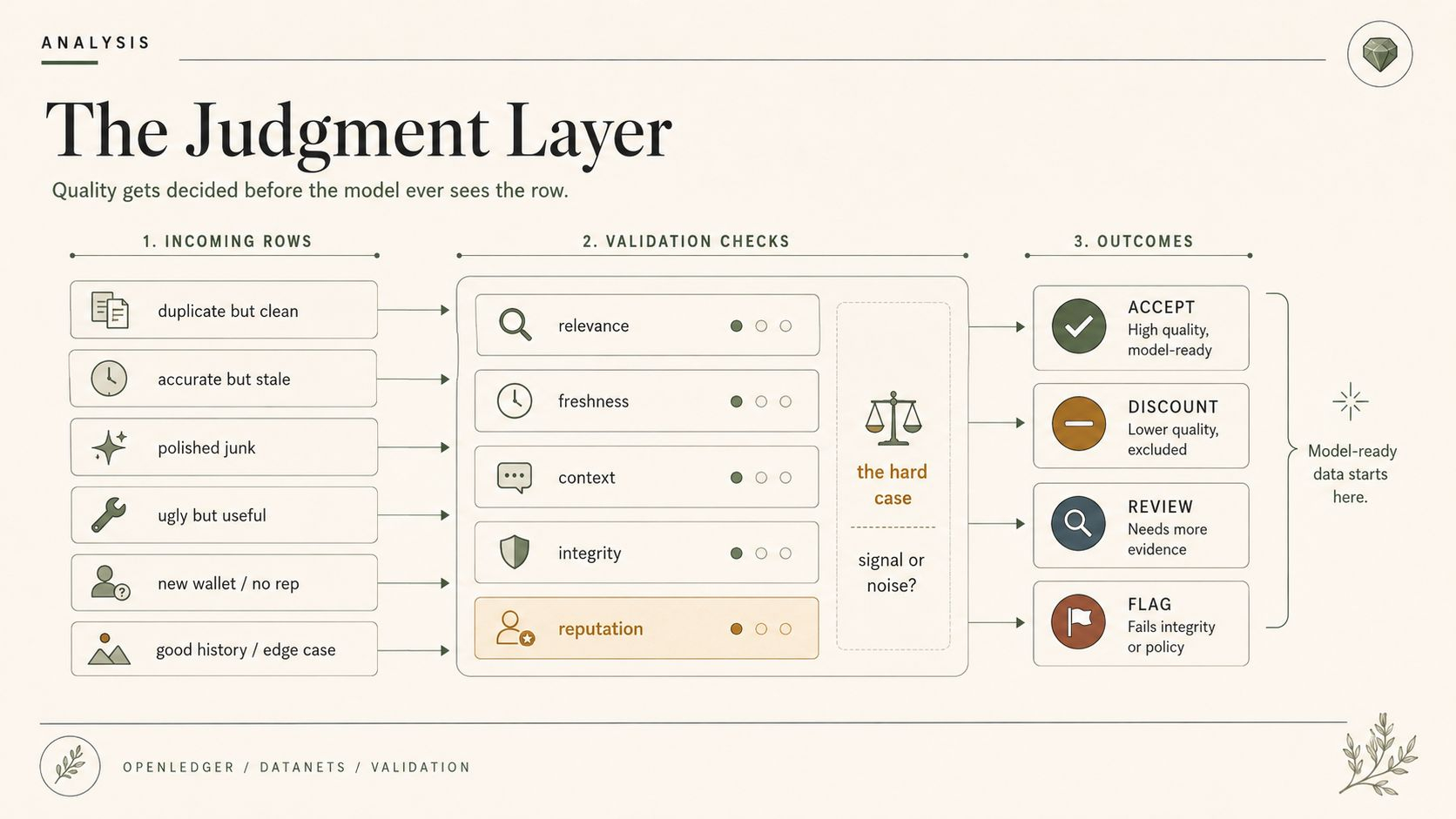
Take a market research agent. It was trained or tuned around a Datanet slice that made sense last month. Liquidity bands were different. The same wallets mattered then. The source mix had enough signal before the market stopped looking like that. The agent was not fake. The data was not invented. The adapter did not explode. The PoA trail still points back to real contributions.
On paper this is exactly the sort of thing OpenLedger is built to improve. Specialized data. Traceable source paths. Agent output that does not ask everyone to trust a sealed corporate model with a smiley dashboard.
Now imagine the source assumption goes stale and nobody really tightens the Datanet scope after the market changes. Or worse, they tighten the public-facing policy note and forget the source slice still sitting in the agent’s retrieval path. Not exploit territory. Just normal operational drift. One source mix old. One exception path left in. One agent still running exactly what it was built to run.
And because it is traceable and automated, the mistake scales like a polite disease.
Not with sirens.
With repetition.
One output that should have been reviewed.
One source family that should have been retired.
Then another.
Then another.
Each individually traceable. Each PoA path clean. Each answer looking boring and correct in isolation. The kind of boring that gets people hurt because boring systems earn trust faster than noisy ones.
That is where OpenLedger gets sharp in a way I don’t think people fully price in.
Opaque AI fails like a locked room. Everybody knows they can't see enough and starts yelling about the box. Traceable AI can fail like procedure. The lineage keeps showing up, the agent keeps answering, the records look tidy enough, and the outside workflow often cannot tell if the problem is source freshness, adapter behavior, retrieval scope, or just the old assumption still breathing inside the output.
I've watched systems like this before. Not OpenLedger specifically. Just systems that got a little too good at saying “output generated successfully” when the real question was whether the source assumption still deserved to exist in that exact shape.
And people inside the system always know first. That is the uncomfortable part.
Ops notices the dashboard row feels off.
A desk notices the agent keeps leaning into the same stale venue cluster.
One reviewer starts muttering that too many borderline outputs are clearing cleanly.
Nobody has a dramatic screenshot proving disaster because the thing is not exploding. It is just wrong in a smooth, repeated, institution-shaped way.
Great.
Those are the hardest mistakes to kill.
Because on OpenLedger the trace is only answering one question: what shaped this output? Useful. Necessary. But if the Datanet slice is stale, over-narrow, over-broad, or still carrying assumptions from an old regime, then traceable automation turns into a very efficient machine for scaling yesterday’s judgment into today’s workflow.
Quietly.
That quiet matters.
A black-box AI system doing the same thing leaves a different kind of mess. People distrust it by default once it gets weird. They ask for logs. They ask for model notes. They assume the box is hiding something. Annoying, but at least suspicion creates friction.
OpenLedger removes a lot of that friction for good reasons.
That is the value.
It also means a weak source assumption can travel further because the trace looks clean enough to calm the room.
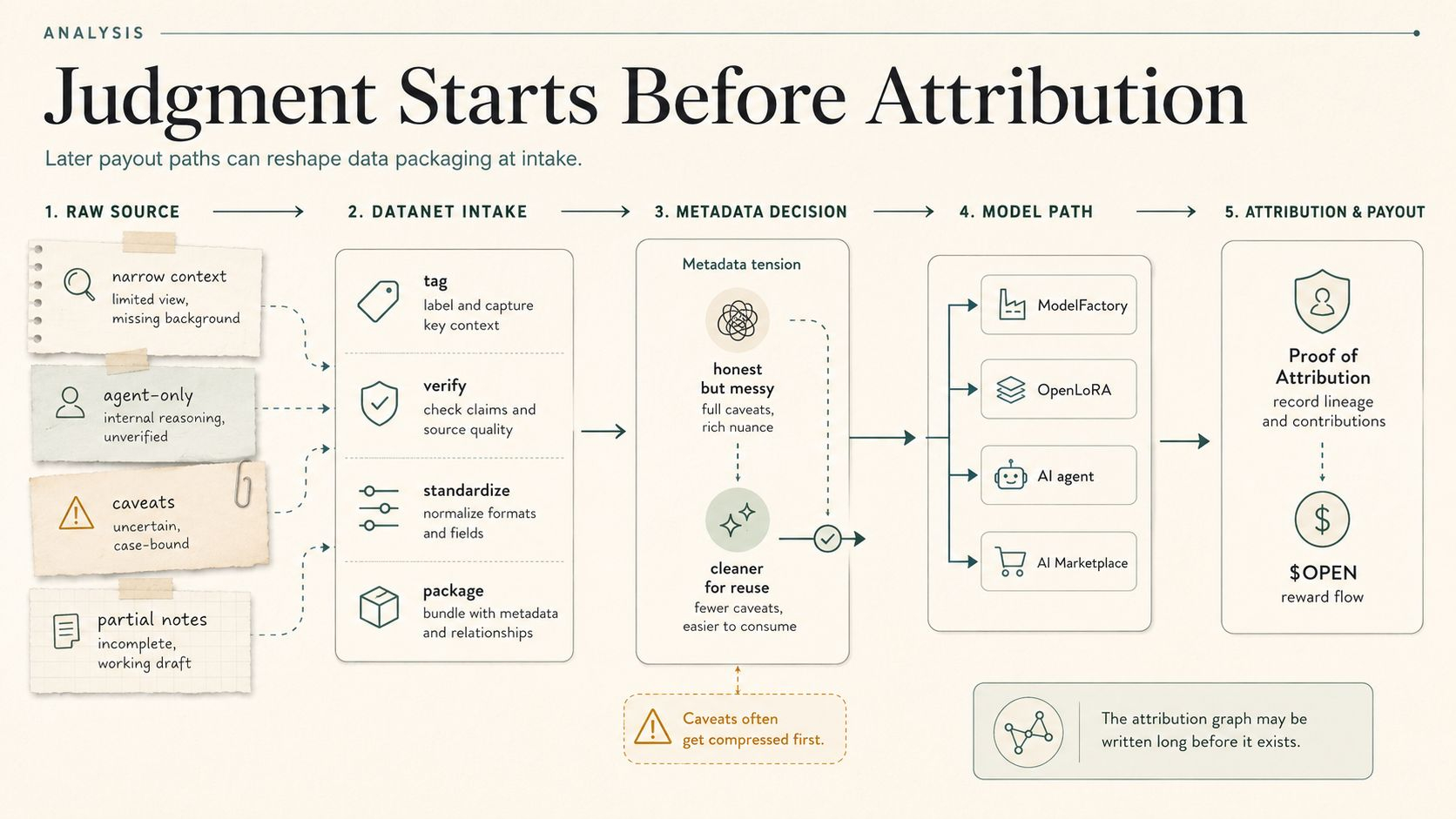
And the architecture makes that easier to miss, not because OpenLedger is broken, but because it is orderly. Datanet source path. OpenLoRA adapter. ModelFactory agent. PoA contribution trace. Output lands. Everything can look mechanically adult while the underlying source policy is still carrying some rotten little assumption nobody wanted to revisit because the agent was working.
Working.
That word again.
That's the trap.
Not exploit.
Not fraud, necessarily.
Not bad attribution in the narrow sense either.
Just a Datanet assumption that fit one moment, then the moment moved, and the agent kept going because nobody built enough drag into the workflow to force the question back open.
And once that happens at scale, the fight changes.
Now it is not “did OpenLedger trace the specialized workflow?” Maybe it did.
It is “how many times did the traceable system repeat the wrong judgment before anyone outside the build room could even describe what was wrong?”
That is a nastier question.
Because by the time the pattern gets obvious, the PoA trail is clean, the outputs are done, the marketplace route moved, the OctoClaw action may already have fired off the stale path, the dashboard looks technically valid, and the real argument is sitting one layer lower where nobody wanted to spend time in the first place:
who let a stale Datanet assumption sit in the retrieval path long enough to become a quiet production system just because OpenLedger could trace it while it ran?