Pēdējā laikā esmu izpētījis Openledger arhitektūru, galvenokārt attiecībā uz atribūtu un ieguldītāju stimulu slāni. Patiesībā projekts ir interesantāks, ja pārtraucat to skatīties kā "AI + blokķēde" un sākat to aplūkot kā mēģinājumu novērtēt ieguldījumu AI sistēmās.
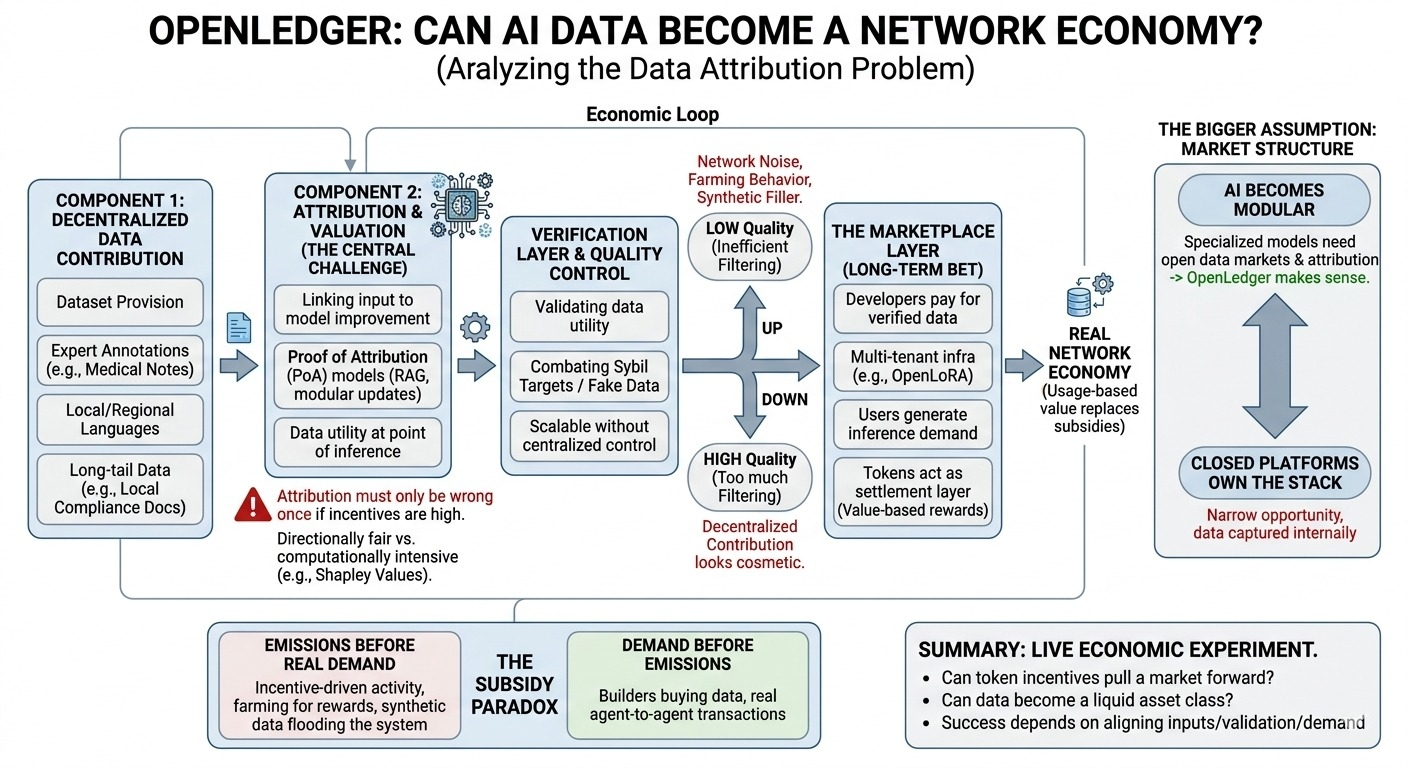
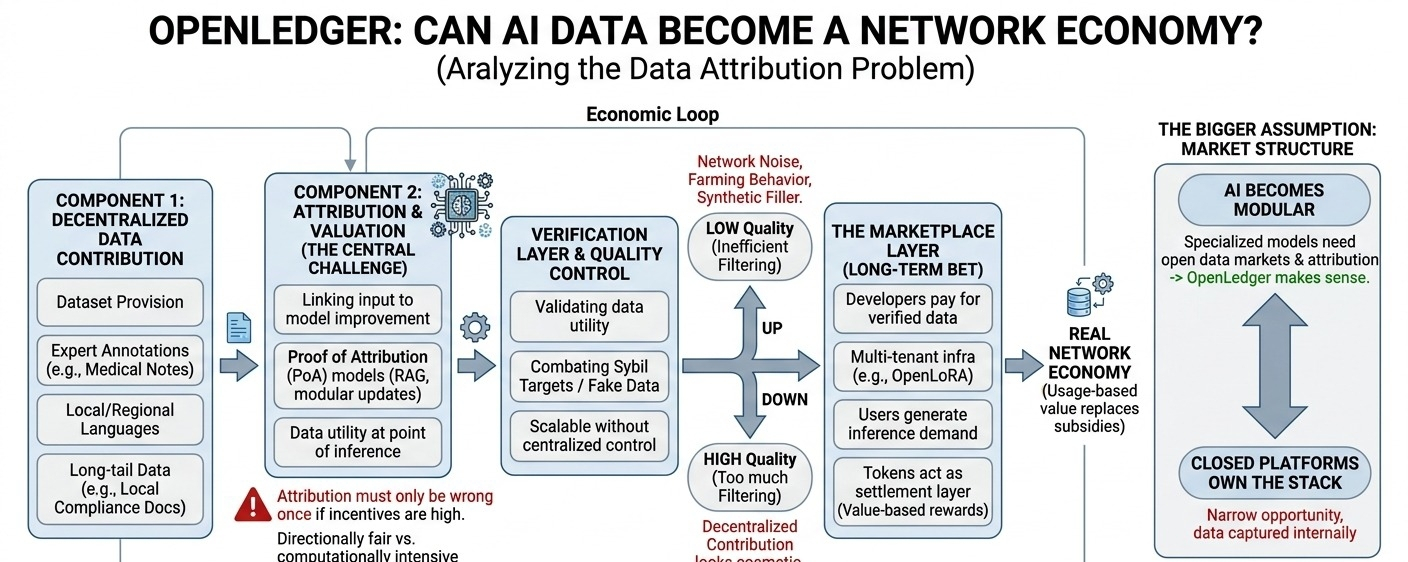
lielākā daļa cilvēku domā, ka Openledger ir tikai vēl viens AI + kripto tokens. Tas ir vienkāršotais variants. Tas, kas man pievērsa uzmanību, ir veids, kā protokols mēģina savienot decentralizētu datu ieguldījumu, modeļa izmantošanu un atlīdzības sadali vienā ekonomiskajā ciklā.
pirmais komponents ir datu ieguldījumu sistēma. līdzdalībnieki var sniegt datu kopas, anotācijas, atsauksmes vai nozares specifiskus ieguldījumus. tas var būt svarīgi ilgstošiem datiem, kurus centralizētas platformas var neefektīvi vākt, piemēram, reģionālo valodu piemēri, vietējie atbilstības dokumenti vai ekspertu marķētas medicīniskās piezīmes.
tad nāk atribūcija, kur dizains kļūst sarežģītāks. ja modelis uzlabojas, izmantojot ieguldītos datus, kā openledger zina, kuri izejas dati bija svarīgi? mākslīgā intelekta modeļi neveido skaidras kvītis. tie absorbē modeļus no jauktām datu kopām. viens mazs, bet reti sastopams datu kopums var uzlabot modeli vairāk nekā liels vispārējs augšupielādējums.
un šī ir daļa, par kuru es vienmēr domāju: atribūcija tikai vienreiz var būt nepareiza, kad stimuli ir lieli.
varbūt sistēmai nav nepieciešama perfektā atribūcija. varbūt tai ir nepieciešams būt virzienā godīgai un grūti manipulējamai. bet tas joprojām prasa spēcīgu izcelsmes izsekošanu, validāciju un veidu, kā saistīt atlīdzības ar faktisko modeļa lietderību, nevis vienkāršu aktivitāti.
tirgus slānis ir ilgtermiņa likme. ideālā gadījumā izstrādātāji maksā par pārbaudītiem datiem vai modeļu piekļuvi, lietotāji rada pieprasījumu pēc secinājumiem, un līdzdalībnieki nopelna no lietošanas balstītas vērtības. šajā versijā token darbojas kā norēķinu slānis starp dalībniekiem, nevis tikai kā subsīdiju mehānisms.
bet neērta daļa ir laiks. ja emisijas notiek pirms reāla pieprasījuma, tīkls var izskatīties aktīvs, kamēr ir galvenokārt stimulēts. cilvēki augšupielādē datus, jo pastāv atlīdzības, nevis tāpēc, ka būvētājiem ir nepieciešami dati. tad zemas kvalitātes datu kopas, dublētas augšupielādes, sintētiskais aizpildītājs un saimniecības uzvedība kļūst par sistēmas sastāvdaļu.
tātad verifikācijas slānis nav izvēles jautājums. openledger jāspēj palielināt kvalitātes kontroli, neizveidojot centralizētu apstiprināšanas komiteju. pārāk maz filtrēšanas un tīkls kļūst trokšņains. pārāk daudz filtrēšanas un decentralizētā ieguldījumu modelis sāk izskatīties kosmētisks.
vēl joprojām nav skaidrs, kas šeit patiesībā rada vērtību. līdzdalībnieki rada izejas datus. validatori rada uzticību. modeļu izstrādātāji rada izmantojamus sistēmas. lietotāji rada ekonomisko pieprasījumu. tīklam jānodrošina, lai šie stimuli būtu saskaņoti pietiekami ilgi, lai reāla izmantošana aizstātu tokenu subsīdijas.
lielāka pieņēmuma ir tāda, ka mākslīgā intelekta attīstība laika gaitā kļūst arvien modulārāka. ja specializētajiem modeļiem arvien vairāk nepieciešami ārējie datu tirgi un caurspīdīga atribūcija, openledger sāk iegūt jēgu. ja slēgtās platformas turpina piederēt visai struktūrai, iespēja var būt šaurāka, nekā tokenu tirgus sagaida.
sekoju līdzi:
* lietošanas balstītas atlīdzības pret emisijām
* datu kopu kvalitāte pēc stimulu palielināšanas
* izstrādātāju pieprasījums pēc pārbaudītiem datiem
* atribūcijas strīdi un surogātpasta pretestība
nav vēl skaidras secinājuma. openledger varētu veidot īstu mākslīgā intelekta koordinācijas slāni. vai arī tas varētu pārbaudīt, vai tokenu stimuli var virzīt tirgu uz priekšu, pirms pieprasījums ir skaidri ieradies.