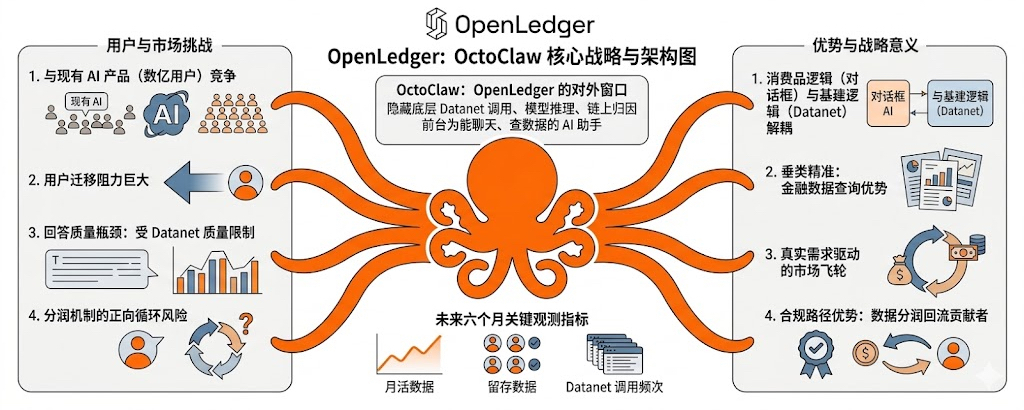
OpenLedger做了一年多基础设施,Datanet、Model Factory、链上归因这些东西,普通用户其实根本看不见也用不到。我自己五月这周翻它的GitHub和文档,越看越觉得这个项目像在地下室里盖房子,地基打得很扎,但你从街上路过完全不知道里面在干什么。OctoClaw这个产品的出现,我觉得是@OpenLedger 第一次把头探出地面,让外面的人能看见它在做什么。
之前的产品线全是给开发者准备的。你要用Datanet,得懂数据上链、贡献权重、归因证明这套东西,门槛不低。Model Factory也是一样,能上手训练模型的人本来就不多,再叠加链上工具的学习成本,普通用户基本被挡在门外。$OPEN 的代币和叙事讲了一年,但真正能让一个完全不懂Web3的人在五分钟内用起来的产品,之前一个都没有。这是它增长曲线一直起不来的根本原因,不是技术不行,是没有前台。
OctoClaw的设计走的是另一条路。它把底层的Datanet调用、模型推理、链上归因这些东西全都藏在了一个对话框后面,用户看到的就是一个能聊天能查数据能做任务的AI助手,跟用普通的AI产品几乎没区别。但每一次调用背后,实际上都在触发OpenLedger链上的分润流程,数据提供方、模型训练者、节点运营者都能拿到对应的OPEN代币。用户不需要知道这些,他只要觉得这个AI好用就行。这种设计我觉得很聪明,前台是消费品逻辑,后台是基础设施逻辑,两边的体验完全解耦。
这里有一个转折点值得细说。OctoClaw如果能做到几十万的月活,对整个#OpenLedger 网络的拉动是几何级的。因为每一个OctoClaw用户都是Datanet数据的真实消费者,他们的每次调用都在给数据贡献者发钱,给模型训练者发钱。这会让原本只有少数极客愿意贡献数据的状态,转变成有真实需求驱动的市场。供需两端一旦被打通,飞轮才会真的开始转起来。之前OpenLedger的增长一直靠激励补贴撑着,用户来了拿完奖励就走,留存极差。OctoClaw如果能把"用得爽"做出来,留存的逻辑就完全不一样了。
我自己试用了OctoClaw的内测版本几天,做了几个金融数据查询和链上地址分析的任务,体验比我预期要好。响应速度还可以,回答的准确度在金融这个垂类上明显比通用大模型强,因为后面接的Datanet里有专门的金融数据集。这个差距是肉眼能感觉到的,不是营销话术。但我也不想说得太满,OctoClaw目前在通用任务上还是不如成熟的AI产品流畅,复杂多轮对话的表现有点跟不上,文件处理能力也偏弱,这些都是要补的功课。
战略意义这件事还得从更大的层面看。AI赛道的项目99%都在卷模型本身,OctoClaw的差异化不在模型,而在它背后的归因和分润机制。同样一个回答,用OctoClaw产生的价值会回流给数据贡献者,用别的AI产品产生的价值就全归平台方了。这个差别短期内用户感受不到,但长期看是两套完全不同的价值分配方式。如果AI生成内容的版权和数据使用费这件事在监管层面被认真对待,OctoClaw这种合规路径的竞争优势会被放大。如果监管始终是个软约束,那OctoClaw的差异化就只剩用户体验本身能不能打。
OctoClaw的风险我觉得也很清楚,但不是三条并排摆出来那么简单。它要跟那些已经有几亿用户的成熟AI产品正面竞争,用户迁移的阻力非常大,光靠归因机制讲故事拉不动普通人,这是最现实的一道坎。再往深一层,OpenLedger链上的数据质量参差,OctoClaw的回答质量天花板就被Datanet的质量卡住,这块如果不能持续提升,用户体验会到一个点就上不去了。而且分润机制如果没有形成正向循环,贡献者赚不到钱就不会持续贡献,数据池会慢慢枯竭,这三件事是连着的,任何一环断掉都会影响另外两环。
但我整体还是看好OctoClaw这步棋。它让OpenLedger第一次有了一张能给普通用户看的脸,从一个开发者圈子里的项目,变成了一个有消费级产品入口的项目。这个转变对估值的影响是根本性的,不只是多了一个产品那么简单。我现在的看法是。接下来半年OctoClaw的月活数据、留存数据、还有Datanet调用频次这三个指标,会直接告诉我们这步棋走对了没有。