 Es atkal un atkal pārdomāju vienkāršu spriedzi kriptovalūtās un mākslīgajā intelektā: mums tiek teikts, ka decentralizētās sistēmas atlīdzina ieguldījumu, taču lietas, kas patiešām rada vērtību—dati, etiķetes, precizēšana, atsauksmes un neredzamais kurēšanas darbs—joprojām pazūd fona. OpenLedger man šķiet interesants, jo tas neizliekas, ka šī pretruna ir jauna. Tas sāk no tās. Projekta paša ietvars ir tāds, ka lielākā daļa AI darbojas aiz slēgtām durvīm, ar neskaidru izcelsmi un vājo atpazīšanu cilvēkiem, kuru dati veidoja rezultātu. Šajā ziņā OpenLedger ir mazāk tīra izgudrojuma nekā nopietns mēģinājums atbildēt uz atkārtotu jautājumu, kas ir sekojis visam AI uzplaukumam: kurš, precīzi, būtu jāapmaksā, kad modelis ir noderīgs?
Es atkal un atkal pārdomāju vienkāršu spriedzi kriptovalūtās un mākslīgajā intelektā: mums tiek teikts, ka decentralizētās sistēmas atlīdzina ieguldījumu, taču lietas, kas patiešām rada vērtību—dati, etiķetes, precizēšana, atsauksmes un neredzamais kurēšanas darbs—joprojām pazūd fona. OpenLedger man šķiet interesants, jo tas neizliekas, ka šī pretruna ir jauna. Tas sāk no tās. Projekta paša ietvars ir tāds, ka lielākā daļa AI darbojas aiz slēgtām durvīm, ar neskaidru izcelsmi un vājo atpazīšanu cilvēkiem, kuru dati veidoja rezultātu. Šajā ziņā OpenLedger ir mazāk tīra izgudrojuma nekā nopietns mēģinājums atbildēt uz atkārtotu jautājumu, kas ir sekojis visam AI uzplaukumam: kurš, precīzi, būtu jāapmaksā, kad modelis ir noderīgs?
Šis jautājums ir atkal aktualizējies, jo vecās atbildes nekad nav pilnībā turējušas. Atvērtas datu tirgus varētu uzskaitīt aktīvus, bet tās reti padara lejupvērsto lietošanu saprotamu. Licences varētu regulēt piekļuvi, bet ne katru secinājumu. Audita ceļi varētu reģistrēt notikumus, bet ne vienmēr piešķirt nozīmīgu kredītu. Pat tad, kad AI būvētāji vēlējās būt uzmanīgāki, mūsdienu modeļu struktūra padarīja grūti izsekot vienu ieguldījumu uz vienu rezultātu ar pārliecību. OpenLedger baltais papīrs ir pietiekami atklāts pamatproblēmā: datu devēji parasti ir atdalīti no vērtības, ko viņu dati rada, un nav bijis plaši pieņemta mehānisma, lai tos atpazītu vai atlīdzinātu. Šis atstatums nav tikai ētisks; tas ir struktūrāls.
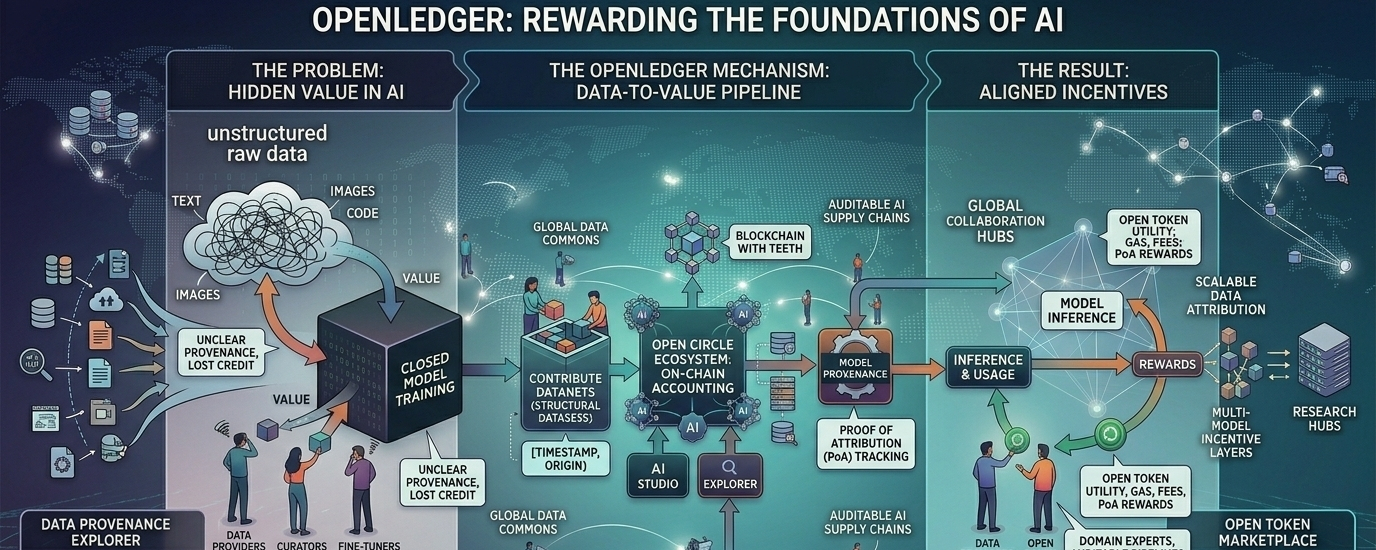
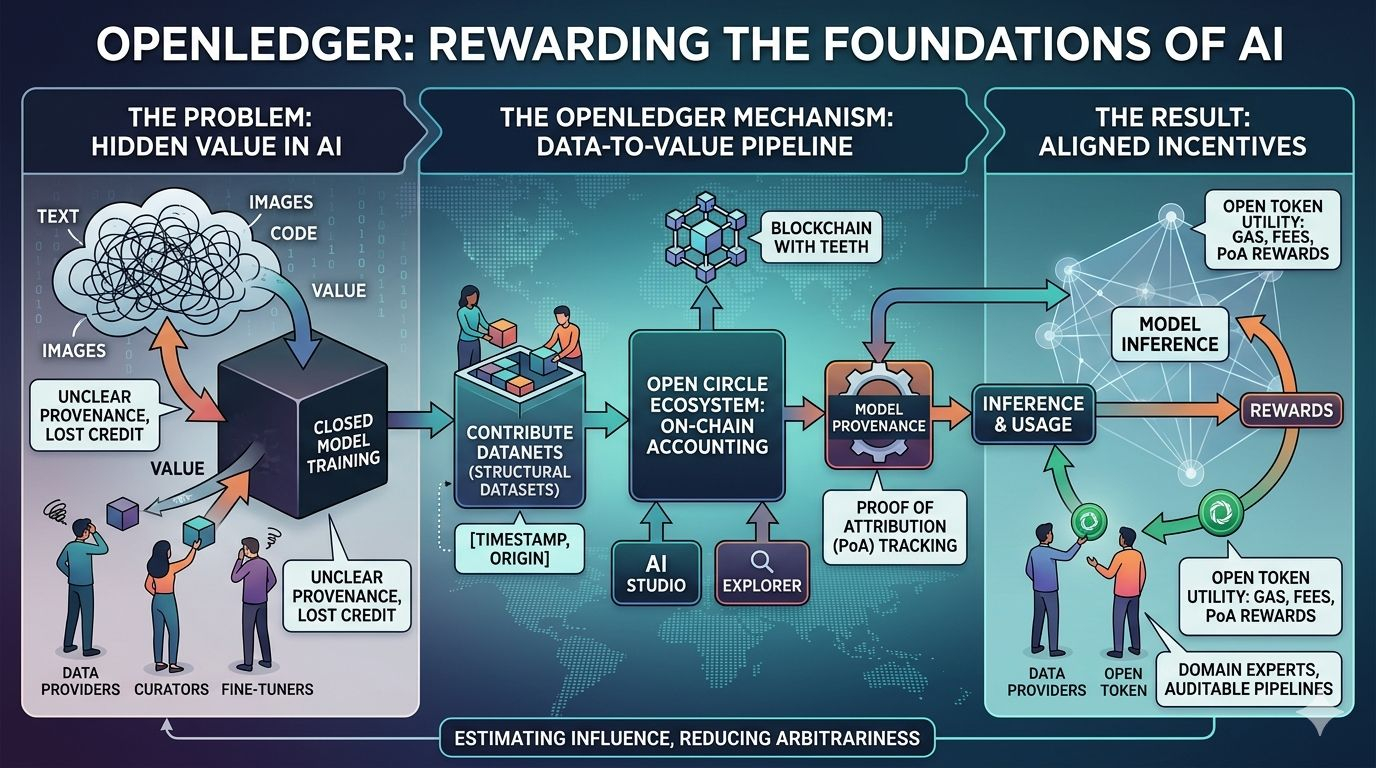
Ko OpenLedger piedāvā, ir alternatīvs ietvars, nevis vispārējs blockchain ar AI tēmu pievienotu. Projekts sevi raksturo kā AI blockchain, kas būvēts īpaši datiem, modeļiem un aģentiem, un tā materiāls atkārtoti uzsver, ka tas necenšas būt viss visiem. Loģika ir šaurāka: ja AI kļūs par programmējamu ekonomisku slāni, tad tās ievades izcelsme, modeļu izcelsme, un atlīdzības sadalei jābūt vietējai stekam, nevis piespiestai vēlāk. Es redzu to kā argumentu, ka blockchain noderīgā loma šeit nav abstrakta decentralizācija, bet grāmatvedība ar zobiem.
Pamatmehānisms tiek saukts par Atribūcijas Pierādījumu, un šeit projekts kļūst tehniskāks nekā tā mārketinga īsais apraksts. 2025. gada jūnija dokumentā OpenLedger saka, ka sistēma izmanto divas atribūcijas metodes: ietekmes funkciju pieejas mazākiem modeļiem un sufiksu masīva balstītu tokenu atribūciju lielākiem valodas modeļiem. Dati tiek organizēti tajā, ko tā sauc par Datu Tīklēm, kas ir strukturēti datu kopas, ko sniedz viens vai vairāki lietotāji, un kas tiek reģistrēti ar metadatiem un laika zīmēm. Modeļi tad reģistrē apmācību izcelsmi pret šiem Datu Tīkliem, lai secinājumu varētu saistīt ar datiem, kas to ietekmēja, un atlīdzības var tikt sadalītas atbilstoši. Tas ir ambiciozs dizains, un arī atklājošs, jo tas parāda, cik grūti patiesībā ir atribūcijas problēma: viena metode nav pietiekama, tāpēc sistēmai jāmaina rīki atkarībā no modeļa mēroga.
Es uzskatu, ka divu metožu pieeja ir gan solīga, gan nedaudz satraucoša. Solīga, jo tā atzīst praktisko realitāti: atribūcija kompakta specializēta modeļa ietvaros ir atšķirīgs uzdevums no atribūcijas pierobežas mēroga valodas modelī. Satraucoša, jo tā arī nozīmē, ka sistēma neatrod perfektu cēloņsakarību patiesību; tā novērtē ietekmi dažādos ierobežojumos. Tas nav kritika, kas ir unikāla OpenLedger. Tā ir atribūcijas daba mašīnmācībā. Bet tas ir svarīgi, jo atlīdzības sistēma, kas balstās uz secinājumu līmeņa ietekmi, darbojas tik labi, cik labi ir tās pieņēmumi. Ja atribūcija ir pārāk stulba, devēji var tikt pārmaksāti vai nepietiekami novērtēti. Ja tas ir pārāk dārgi aprēķināt, sistēma kļūst grūti darboties mērogā. Eleganta daļa OpenLedger ir tāda, ka tā atzīst problēmu. Grūtā daļa ir tā, ka problēma nepazūd.
Produktu valoda ap projektu cenšas pārvērst šo teoriju darbplūsmā. OpenLedger pašu lapas norāda uz AI Studiju, Explorer, Staking un Open Circle ekosistēmu, kamēr blogs par “10 miljardu dolāru lietotnēm” apraksta steku, kurā datu īpašumtiesības, atribūcijas pierādījums, bezkoda modeļu izveide, un RAG un MCP paplašinājumi apvienojas caur caurspīdīgu modeļu veidošanas vidi. Vienkāršos vārdos paredzētais plūsmas process ir pietiekami pazīstams: ieguldīt datus datanetā, izveidot vai pielāgot modeli, izvietot to, un tad ļaut lietojumam atgriezties atribūcijā un maksājumā. Interesantā daļa ir tā, ka OpenLedger vēlas, lai šis cikls būtu redzams ķēdē, nevis slēpts iekšējā privātā platformas grāmatvedībā.
Tokenu dizains seko tai pašai loģikai. Fonda tokenomikas lapā teikts, ka OPEN ir vietējais ERC-20 tokens tīklam, ar kopējo piedāvājumu 1 miljards un sākotnējo cirkulējošo piedāvājumu 21.55%. Vēl svarīgāk attiecībā uz sistēmas struktūru, OPEN tiek raksturots kā degviela tīkla aktivitātei, galvenais maksu tokens secināšanai un modeļu veidošanai, kā arī atlīdzības mehānisms datu devējiem caur Atribūcijas Pierādījumu. Dokumentācija arī norāda, ka pārvaldības modelis ir paredzēts, lai atgādinātu Arbitrum stila pārvaldību, aptverot protokola parametrus, uzlabojumus, īpašumtiesību pārcelšanu un citas kritiskas lēmumu pieņemšanas jomas. Tas ir sakarīgs dizains, lai gan neizšķirts: token var saskaņot stimulus, bet tas var arī importēt parastas pārstāvniecības, vēlētāju vienaldzības un koncentrētas ietekmes problēmas.
Kur es kļūstu piesardzīgāks, ir plaisā starp modeli un adopciju. OpenLedger vīzija ir skaidra uz papīra, bet adopcija kriptovalūtās reti neizdodas, jo ideja ir neskaidra; tā neizdodas, jo berze ir operatīva. Datu devējiem ir jārūpējas par to, lai strukturētu datu kopas. Būvētājiem ir jāuzticas, ka atribūcijas slānis ir vērts papildu slogu. Modeļu lietotājiem ir jāpieņem ķēdes maksa un jauna grāmatvedības shēma, nevis centralizētas API ērtības. Pārvaldībai jāpaliek nozīmīgai, nevis kļūt par šauru spēli, ko spēlē neliels tokenu īpašnieku kopums. Un, ja projekts vēlas pārvietoties ārpus kripto-dabisko būvētāju nišas, tam būs jāpierāda, ka atribūcija nav tikai filozofiski pievilcīga, bet operatīvi vienkāršāka nekā alternatīvas.
Ir arī smalkāks ierobežojums: datu izcelsme nav tas pats, kas vērtība. Ieguldījums var būt izsekojams un tomēr nepelna lielu svaru. Modelis var būt atkarīgs no datu kopas un tomēr vispārināt veidos, kurus grūti piešķirt skaidri. Balvas loģika balstās uz ietekmes punktiem, bet ietekme ir inherentā konteksta atkarīga. Tas padara sistēmu godīgāku nekā tīra minēšana, tomēr tas tās nekļūst pilnīgi objektīvas. Es domāju, ka OpenLedger to saprot, kas ir daļa no tā, kāpēc projekts izskatās nopietnāks nekā daudzas AI-blockchain narratīvas. Tas nesola atrisināt kredīta filozofiju mašīnmācībā. Tas cenšas padarīt kredītu mazāk patvaļīgu. Tas ir nozīmīgs atšķirīgas, bet ne galīgā atbilde.
Ja modelis darbojas, cilvēki, kas visvairāk gūs labumu, nav spekulatīvie tirgotāji vai abstrakti "kopiena" saukļi, bet šaurākas grupas: jomas eksperti, kuri var piegādāt augstas kvalitātes datus, būvētāji, kuriem nepieciešamas audītājamas modeļu caurules, un organizācijas, kas vēlas AI sistēmas ar izsekojamiem ievadiem. Cilvēki, kuri var palikt ārpus tās sasniedzamības, ir tikpat svarīgi pieminēt. Gadījuma lietotāji, iespējams, nekad neinteresēsies, kā darbojas atribūcijas grafiks. Lielas uzņēmējsabiedrības var dot priekšroku slēgtām sistēmām ar vienkāršāku iepirkumu un mazākām pārvaldības mainīgajām. Un daudzi devēji, pat ja tehniski tiek atlīdzināti, var atrast procesu pārāk sarežģītu vai pārāk netiešu, lai ar to nodarbotos. Citiem vārdiem sakot, OpenLedger solījums atkarīgs mazāk no tā, vai arhitektūra ir gudra, bet gan no tā, vai pietiek daudz cilvēku uzskata, ka papildu struktūra ir vērta pieņemšanai. Tas ir daudz grūtāks tests. Kas man paliek atklāts, ir vai AI tiešām nepieciešama jauna ekonomiskā slāņa, lai kļūtu atbildīga - vai arī atbildība turpinās ierasties tikai tur, kur iestādes jau ir disicplinētas to pieprasīšanai.