Esmu redzējis OpenLedger vairāk kā naratīva maiņu, nevis tikai vēl vienu “AI + blockchain” projektu, un mana pirmā iespaida ir tāda, ka tas cenšas atrasties tieši tajā krustojumā, kur šodien ir lielākā spriedze: AI vēlas vairāk datu, lai kļūtu noderīgs, bet reālā pasaule virzās pretējā virzienā, kur dati kļūst aizvien vairāk ierobežoti, regulēti un privātuma jutīgi.
Emocionālā līmenī man šī ideja šķiet patiešām aizraujoša, taču arī nedaudz pārāk optimistiska, pieņemot, ka pasaule gludi koordinēsies ap datu monetizāciju. Aizrautība nāk no ļoti reālas frustrācijas, ko jau redzam nozarēs, piemēram, veselības aprūpē, finansēs un uzņēmumu AI. Ikvienam ir dati, ikvienam gribas izmantot AI, bet gandrīz neviens vairs nevēlas atklāt neapstrādātus datu kopumus. Tāpēc sistēma, kas sola “tu vari pierādīt vērtību, apmācīt modeļus vai izmantot aģentus, neradot atklātus sensitīvos datus” šķiet kā dabiska evolūcija. Tajā pašā laikā es palieku skeptisks, jo datu īpašumtiesību stimulu jautājums ir sarežģīts, un slimnīcu, valdību vai lielo uzņēmumu piespiešana standartizēt kopēju on-chain likviditātes slāni datiem ir vēsturiski ārkārtīgi grūta.
Vienkāršos reālās pasaules vārdos, iedomājieties slimnīcu, kas izmanto AI, lai agrīnā stadijā atklātu vēzi no skenējumiem. Šodien slimnīca vai nu nosūta datus centralizētam AI pakalpojumu sniedzējam, vai arī viss tiek veikts iekšēji. Abām iespējām ir trūkumi: privātuma risks no vienas puses, ierobežota modeļa uzlabošana no otras. Sistemā, ko piedāvā OpenLedger, slimnīca teorētiski varētu ļaut AI modeļiem mācīties no paraugiem savos datos, nekad neizpaužot neapstrādātos pacientu ierakstus, un dalīties tikai ar pierādījumiem vai kriptogrāfiskiem apstiprinājumiem, ka modelis tika pareizi apmācīts vai izmantots. Tas izklausās jaudīgi, īpaši tādās jomās kā diagnostika, zāļu izstrāde vai genomika, kur datu jutīgums ir ārkārtīgi augsts.
Vēl viens piemērs ir apdrošināšanas krāpšanas atklāšana. Apdrošināšanas uzņēmumiem ir milzīgi datu kopumi, bet tie reti tos dalās, jo tie satur personīgu un regulētu informāciju. Privātumu saglabājoša AI izpildes slānis varētu ļaut vairākiem apdrošinātājiem piedalīties kopīgā krāpšanas atklāšanas modelī, vienlaikus saglabājot klientu līmeņa datus slēptus. Šāda veida selektīva izpaušana ir vieta, kur koncepts kļūst vairāk nekā tikai teorija un sāk justies operatīvi vērtīgs.
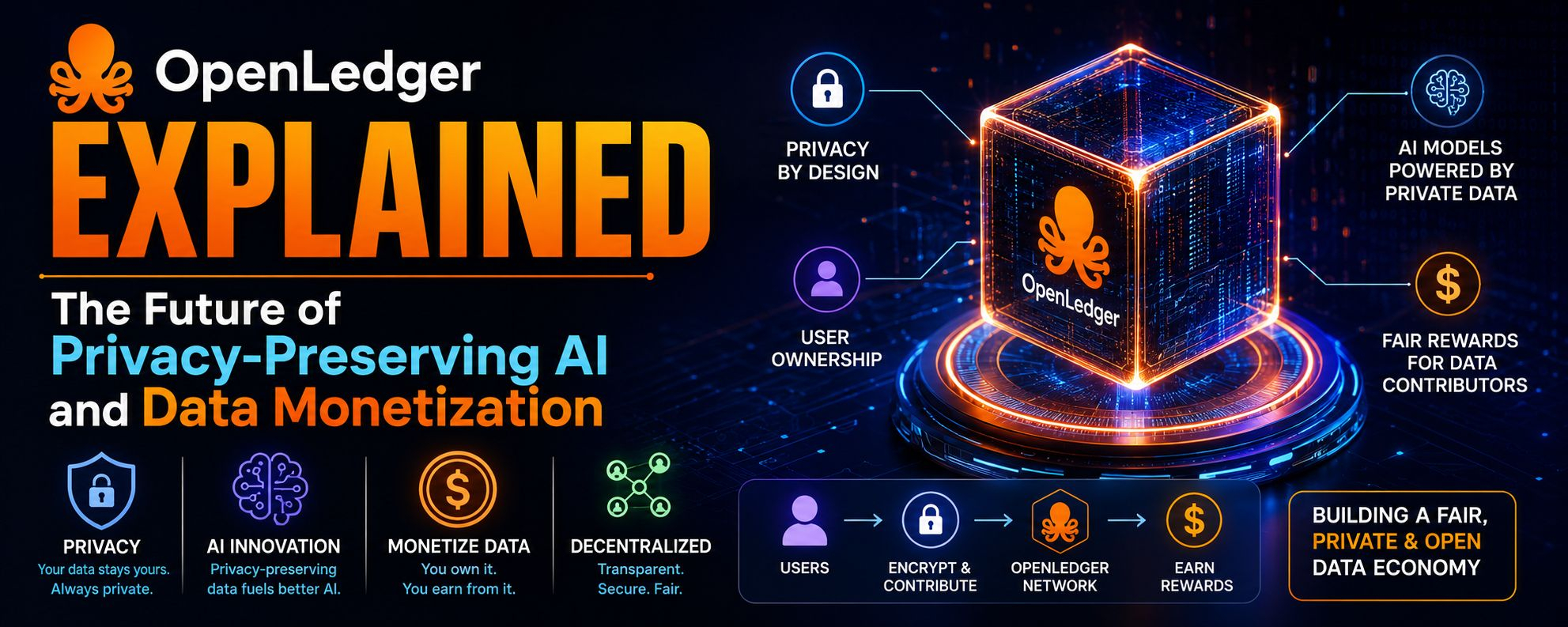
To, ko OpenLedger cenšas risināt savā pamatā, ir trīs pārklājoši problēmas. Pirmā ir datu nepietiekama izmantošana, kur vērtīgi datu kopumi paliek neizmantoti, jo tos nevar droši dalīt. Otrā ir AI modeļa atribūcija, kas nozīmē, kurš patiesībā ir devusi datus, aprēķinus vai apmācības pūles AI sistēmai. Trešā ir monetizācijas berze, kur šodien nav skaidras tirgus vietas, kur dati, modeļi un aģenti varētu tikt novērtēti, izsekoti un atlīdzināti caur caurspīdīgu veidu, bez juridiskām un privātuma komplikācijām, kas pastāvīgi to bloķē.
Plānotie lietotāji noteikti nav parastie lietotāji. Tas skaidri mērķē uz uzņēmumiem, AI izstrādātājiem, datu sniedzējiem un infrastruktūras operatoriem. Teorētiski slimnīcas, pētniecības laboratorijas, fintech uzņēmumi un pat autonomo AI aģentu izstrādātāji būtu galvenie ieguvēji. Komforts, ko tas sola, būtībā ir koordinācijas slānis, kur jums nav jāveic manuāla katra datu dalīšanas līguma saruna vai jāveido izolētas AI cauruļvadi katram partnerim. Drīzāk jūs pieslēdzaties kopīgai sistēmai, kur piekļuve, pierādījums un vērtības apmaiņa tiek veikta programmatiski.
No funkcionalitātes viedokļa vissvarīgākā ideja ir "kontrolēta redzamība". Tā vietā, lai dalītos ar neapstrādātiem datiem, tiek dalīti verifikējami aprēķinu rezultāti, lietojuma pierādījumi vai modeļu iznākumi, kas saistīti ar kriptogrāfisku atbildību. Ja tas darbosies kā paredzēts, tas samazinās berzi regulētās vidēs, vienlaikus ļaujot AI sistēmām uzlaboties, izmantojot plašākus mācību signālus. Tas ir ļoti spēcīgs konceptuāls priekšrocība pasaulē, kur privātuma regulējumi, piemēram, GDPR stila struktūras, kļūst stingrāki visā pasaulē.
Paskatoties uz plašākiem trendiem 2026. gadā, AI infrastruktūra ātri pārvēršas uz privātumu saglabājošām aprēķinu metodēm, nevis tikai centralizētu apmācību. Tehnikas, piemēram, federētā mācīšanās, drošas zonas un nulles zināšanu pierādījumi, pāriet no eksperimentālā uz agrīnu ražošanas izmantošanu, īpaši veselības aprūpē un finanšu analītikā. Tajā pašā laikā blockchain sistēmas cenšas atrast reālu lietderību ārpus spekulācijām, tāpēc jebkuram projektam, kas savieno blockchain ar reālu AI darba slodzi, piemēram, datu atribūciju vai modeļu licencēšanu, ir labāka naratīva piesaiste nekā tīrajai DeFi. Tomēr realitāte ir tāda, ka pieņemšana joprojām ir agrīnā stadijā. Lielākā daļa uzņēmumu eksperimentē, bet vēl nav apņēmušies pilnībā decentralizētām AI tirgus vietām.
Nākotnes potenciāls, ja OpenLedger labi izpildīs, varētu būt nozīmīgs. Tas varētu izveidot slāni, kur AI apmācības dati kļūst par izsekojamu, atlīdzināmu aktīvu klasi. Tas fundamentāli mainītu motivāciju datu radītājiem un pat varētu novest pie jauniem ekonomiskiem modeļiem, kur mazi datu kopumi kļūst vērtīgi, ja tie ir augstas kvalitātes un juridiski izmantojami. Tas varētu arī padarīt AI aģentus uzticamākus regulētās vidēs, jo viņu lēmumu plūsmas būtu auditable bez jutīgu ievades datu izpaušanas.
Bet ierobežojumi ir tikpat nopietni. Lielākais ir koordinācijas sarežģītība. Reālā pasaulē ir ļoti grūti panākt, lai iestādes vienojas par kopīgiem standartiem datu privātumam, pierādījumu sistēmām un tokenizētām motivācijām. Vēl viens risks ir veiktspējas pārslodze. Privātumu saglabājošā aprēķināšana joprojām ir dārgāka un lēnāka nekā tradicionālā centralizētā apstrāde. Tad ir klasiskā blockchain problēma: ja tokenu vai motivāciju slānis kļūst svarīgāks par faktiskās lietderības, sistēma var novirzīties uz spekulāciju, nevis reālu pieņemšanu. Un, visbeidzot, ir regulatīvā nenoteiktība. Pat ja dati netiek tieši izpausti, regulatoriem var būt bažas par pāri robežām notiekošu secinājumu vai netiešu datu noplūdi.
Tātad mana godīgā secinājuma ir tāda. OpenLedger šķiet, ka norāda uz reālu struktūras nākotni AI infrastruktūrā, kur dati netiek tieši dalīti, bet joprojām kļūst ekonomiski aktīvi caur pierādījumiem, atļaujām un kontrolētu aprēķinu. Ideja ir saskaņota ar to, kur dodas veselības aprūpe, finanses un uzņēmumu AI. Bet atstatums starp vīziju un reālo īstenošanu joprojām ir plašs, un panākumi būs atkarīgi mazāk no tehnoloģijas elegances un vairāk no tā, vai iestādes patiešām uzticas un integrē to savās ikdienas operācijās. Šajā ziņā tas ir mazāk pabeigts produkts šodien un vairāk likme uz to, kā nākamās paaudzes AI infrastruktūras standarti tiks definēti.
