I’ve become naturally skeptical whenever a blockchain project starts talking about AI infrastructure.
After a while, the language starts blending together. Every project claims to be building autonomous systems, coordination layers, decentralized intelligence, or some kind of AI-powered future. But once you look underneath the surface, most of the infrastructure still depends on fragmented tooling, centralized execution, or hidden trust assumptions somewhere in the middle.
That was honestly my expectation with OpenLedger too.
At first glance, “The AI Blockchain” sounded like another polished narrative trying to combine two industries that are already overloaded with hype. I assumed I’d find the same pattern again — strong branding on the surface, but very little structural difference underneath.
But the more time I spent looking into how OpenLedger is actually designed, the less interested I became in the marketing language and the more interested I became in the operational structure behind it.
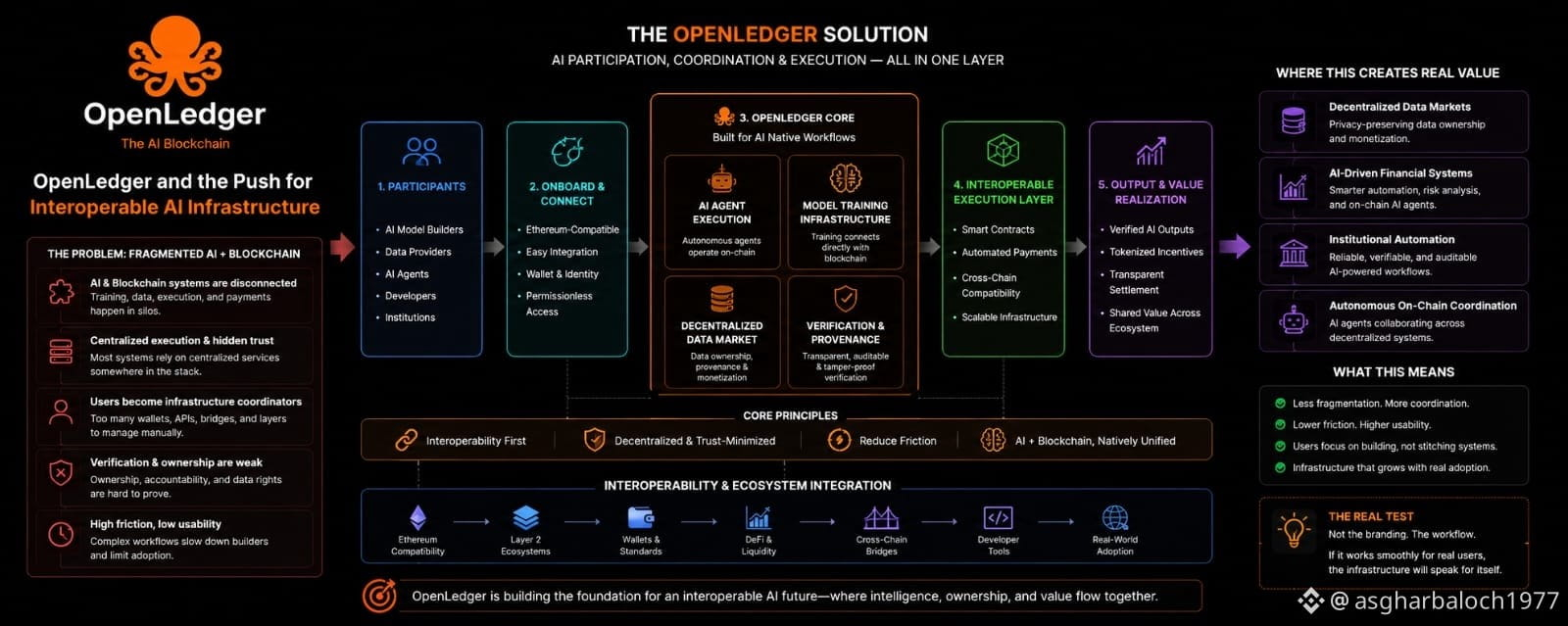
What stood out to me is that OpenLedger seems built around AI participation itself instead of simply attaching AI terminology onto existing blockchain infrastructure.
That distinction matters more than most people realize.
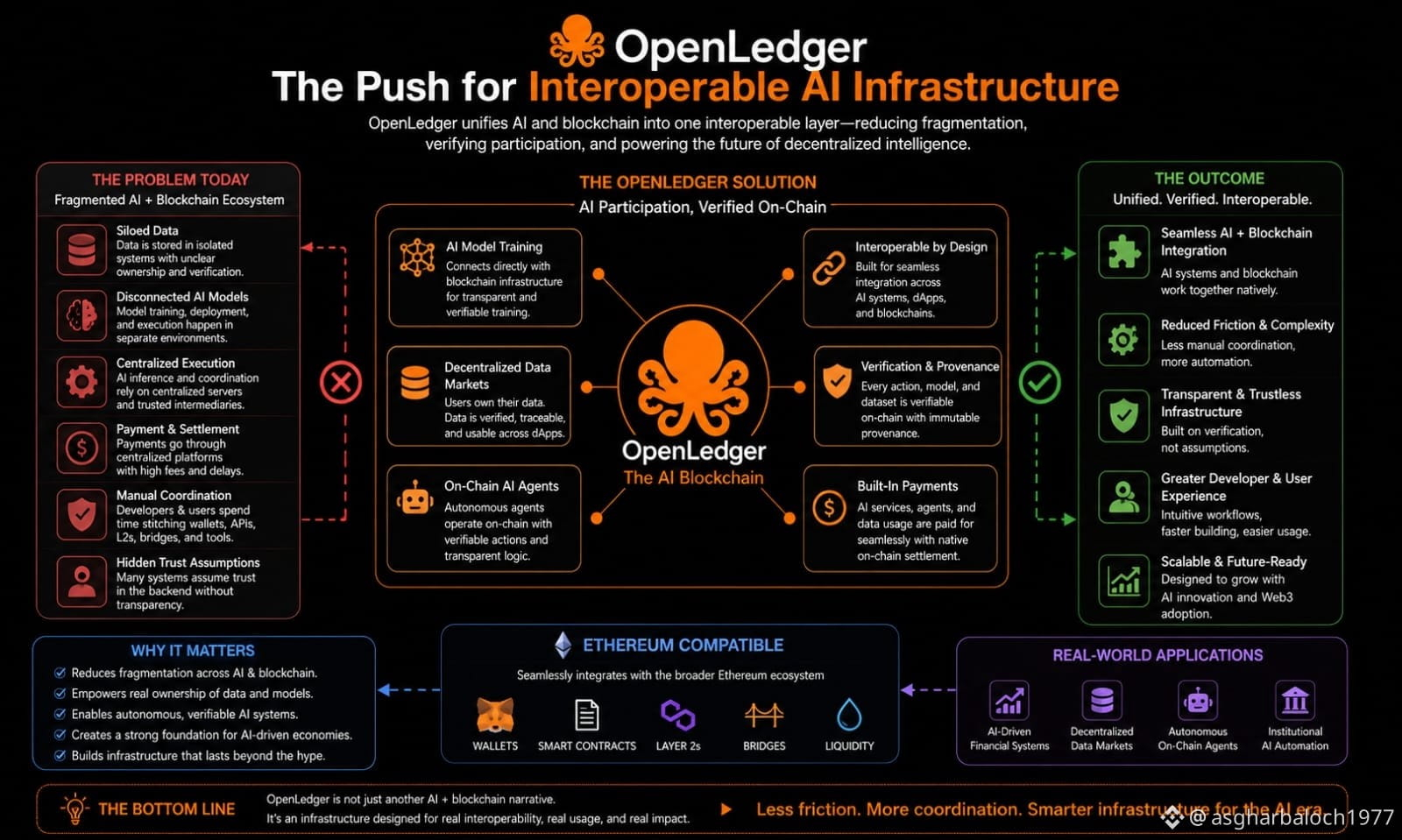
A lot of projects today treat AI like an add-on feature. The blockchain handles settlement, while the actual intelligence, data flow, execution, and coordination still happen off-chain through disconnected services and centralized systems. OpenLedger feels like it’s trying to reduce that separation by allowing AI agents, model builders, and data providers to interact directly inside the same coordinated environment.
At least conceptually, that creates a cleaner structure.
And honestly, fragmentation is one of the biggest problems across both AI and crypto right now.
Training infrastructure exists in one place. Models are deployed somewhere else. Data ownership becomes difficult to verify. Payments depend on centralized platforms. Verification often comes down to trusting whoever controls the backend. Even in Web3 environments, users still spend too much time manually coordinating wallets, APIs, Layer-2 systems, bridges, and execution layers that rarely feel connected properly.
The user ends up becoming the infrastructure coordinator.
That’s where OpenLedger started becoming more interesting to me.
The system appears designed from the infrastructure layer upward with interoperability in mind instead of treating coordination as the user’s responsibility. AI model training can connect more directly with blockchain infrastructure rather than functioning as a completely separate environment. Autonomous AI agents can also operate on-chain in a way that feels integrated into the execution layer itself instead of existing as disconnected external tooling.
On paper, that sounds technical.
But in practice, it’s really about reducing friction.
The less time developers and users spend stitching systems together manually, the more usable the infrastructure becomes. And usability is usually where a lot of supposedly advanced blockchain infrastructure quietly breaks down.
I also think the Ethereum compatibility matters more than people give it credit for.
Most serious blockchain activity still revolves around Ethereum standards in some form, whether through wallets, smart contracts, liquidity systems, or Layer-2 ecosystems. Infrastructure that isolates itself completely often struggles to gain real adoption because users don’t want to rebuild their entire workflow from scratch just to experiment with a new system.
OpenLedger integrating into that broader environment makes the architecture feel more practical instead of isolated.
That doesn’t mean everything is solved, obviously.
AI infrastructure is still messy in the real world. Adoption takes time. Regulation around AI ownership, accountability, and data rights is still evolving. Autonomous agents operating across decentralized systems will probably create new coordination problems that haven’t fully appeared yet. And infrastructure alone never guarantees success if developers don’t actually build useful applications on top of it.
That part matters.
A lot of technically impressive systems fail simply because the ecosystem around them never becomes active enough to justify the infrastructure itself.
Still, I think OpenLedger is approaching the problem from a direction that makes sense.
Instead of focusing purely on narratives, the architecture seems focused on verification, coordination, interoperability, and reducing operational friction between AI systems and blockchain execution. Areas like decentralized data markets, AI-driven financial systems, institutional automation, and autonomous on-chain coordination all feel like environments where this kind of infrastructure could eventually become genuinely valuable if execution stays consistent.
For me, though, the real test is never the branding.
It’s always the workflow.
I pay far more attention to whether systems actually function smoothly once real users begin interacting with them. I look at how reliable the integrations are, how much unnecessary complexity disappears during usage, and whether the infrastructure genuinely reduces coordination overhead instead of simply moving it somewhere less visible.
That’s usually where serious infrastructure reveals itself quietly over time.
And honestly, that’s the stage where OpenLedger became much more interesting to me.