Kad pirmo reizi skatījos uz @OpenLedger 'Pierādījums par atribūciju', es domāju, ka galvenā problēma ir taisnīgums. Samaksājiet cilvēkiem, kuri sniedz noderīgus datus, un sistēma kļūst godīgāka. Bet šī doma tagad šķiet pārāk vienkārša.
Grūtākais jautājums nav, kurš ir ieguldījis. Grūtākais jautājums ir, kura ieguldījums patiešām mainīja atbildi.
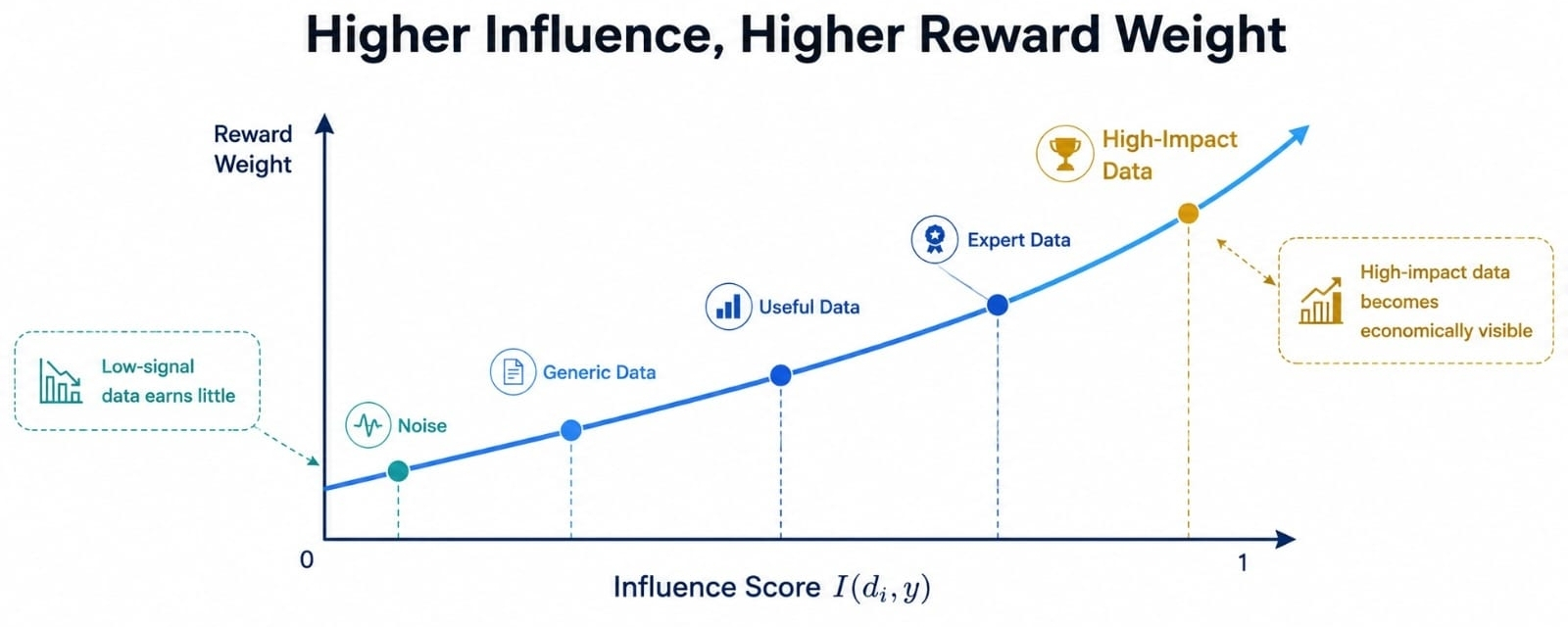
Tur ir svarīgs ietekmes rādītājs I(di, y). Vienkāršos vārdos, di nozīmē vienu datu punktu, y nozīmē vienu modeļa izeju, un I mēra, cik daudz šis datu punkts ietekmēja to konkrēto izeju. Tas pārvērš atribūciju no plaša īpašuma apgalvojuma par šaurāku mērījumu problēmu.
Uz virsmas, ieguldītājs augšupielādē datus DataNetā un gaida, kad vērtība atgriezīsies. Zem virsmas sistēmai jāuzdod jautājums, vai šie dati vienkārši pastāvēja apmācību vidē vai arī tie patiešām bija svarīgi, kad modelis radīja rezultātu.
Šī atšķirība ir klusa, bet tā pilnībā maina atlīdzības loģiku.
Ja 100 ieguldītāji sniedz datus, plakanā atlīdzības shēma var attiekt dalību kā vērtību. Tas rada vāju stimulu. Cilvēki var vajāt apjomu, dublēt materiālus vai iesniegt zema signāla datus, kas izskatās aktīvi, bet neuzlabo modeli zem spiediena.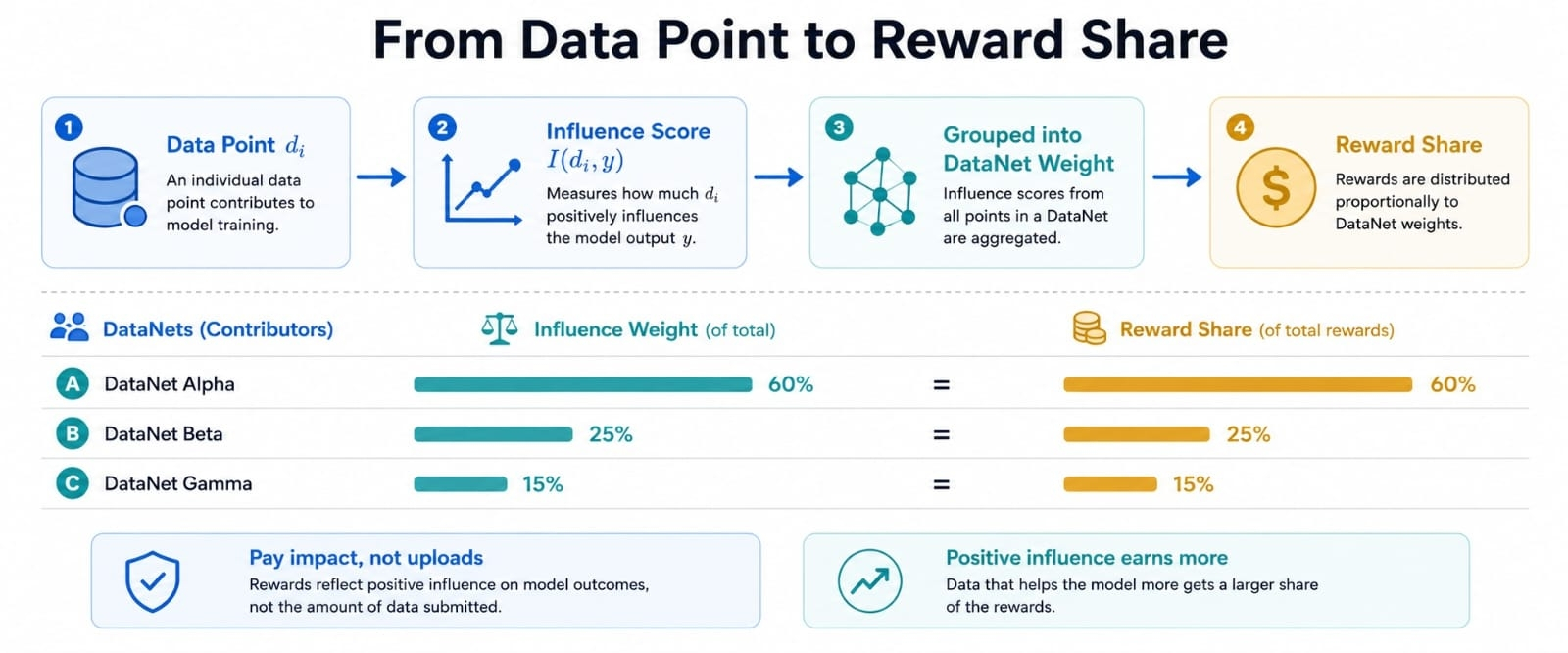
I(di, y) to izaicina. Tā prasa ietekmi, nevis troksni. Ja viens datu punkts uzlabo pārliecību, atbilstību vai precizitāti rezultātā, tam vajadzētu nopelnīt lielāku svaru nekā desmit vispārīgu punktu, kas atrodas tuvumā, bet nav īpaši nozīmīgi.
Izpratne par to palīdz izskaidrot, kāpēc atribūcijas matemātika ir vairāk nekā maksājumu rīks. Tā ir arī stimulus filtrs. Ieguldītājs netiek atlīdzināts vienkārši tāpēc, ka viņu dati iekļuva sistēmā. Viņi tiek atlīdzināti, jo viņu dati joprojām parādās modeļa uzvedībā.
Vienkārša atlīdzības sadalīšana parāda ideju. Ja viens DataNet satur 60 procentus no izmērītās ietekmes vērtīgā rezultātā, bet otrs satur 40 procentus, atlīdzības var pārvietoties ar šo proporciju, nevis tikt manuāli minētas. Šis skaitlis nav tikai grāmatvedības rīks. Tas ir veids, kā padarīt ieguldījumu grūtāk viltot.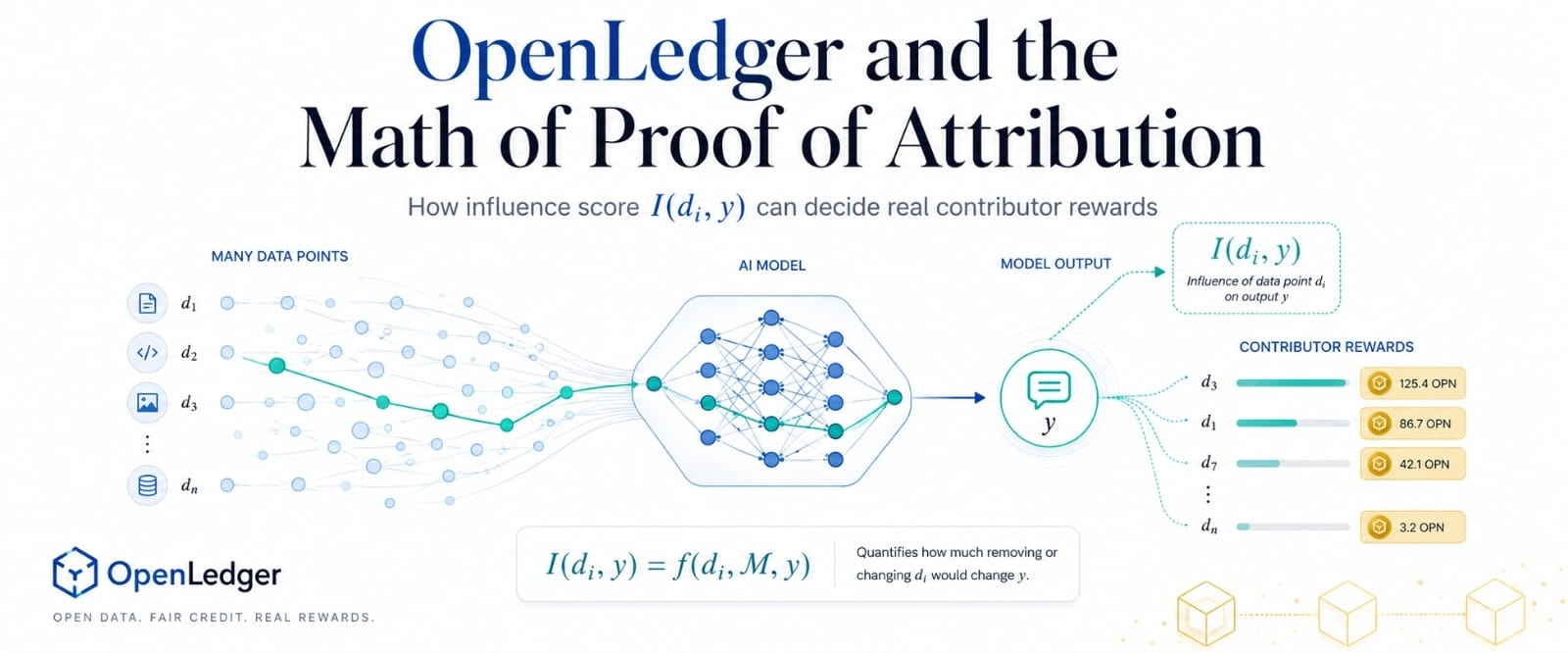
Tas rada citu problēmu. Ietekmes rezultāti var izskatīties tīrāki nekā realitāte. AI rezultāti bieži tiek veidoti, balstoties uz pārklājošiem datiem, atkārtotiem modeļiem un netiešiem signāliem. Augsts rezultāts var atspoguļot patiesu lietderību, bet tas var arī atspoguļot memorēšanu, dublēšanu vai datus, kas izstrādāti, lai izraisītu atribūciju.
Tātad OpenLedger spēcīgākā versija nevar paļauties tikai uz I(di, y). Tai nepieciešami ieraksti, hash, laika zīmogi, dublēšanas noņemšana, validācija un pārvaldība ap sliekšņiem. Formula var izmērīt spiedienu, bet sistēmai joprojām ir jāizlemj, kāda ietekmes pakāpe pelnījusi maksājumu.
Klusa problēma ir uzticība. Kad reālas atlīdzības ir pievienotas, katrs rezultāts kļūst par ekonomisku pamatu. Ieguldītāji pārbaudīs robežas. Pārvaldība saskarsies ar strīdiem. Tirgi jautās, vai atribūcijas slānis ir pietiekami paredzams, lai godīgi novērtētu ieguldījumu.
Ja tas turpinās, #OpenLedger ne tikai veido atlīdzības sistēmu AI datiem. Tas pārbauda, vai AI ieguldījums var kļūt par mērāmām infrastruktūrām.
Patiesais sasniegums nav pierādīt, ka dati bija klāt. Tas ir pierādīt, ka dati bija svarīgi.

