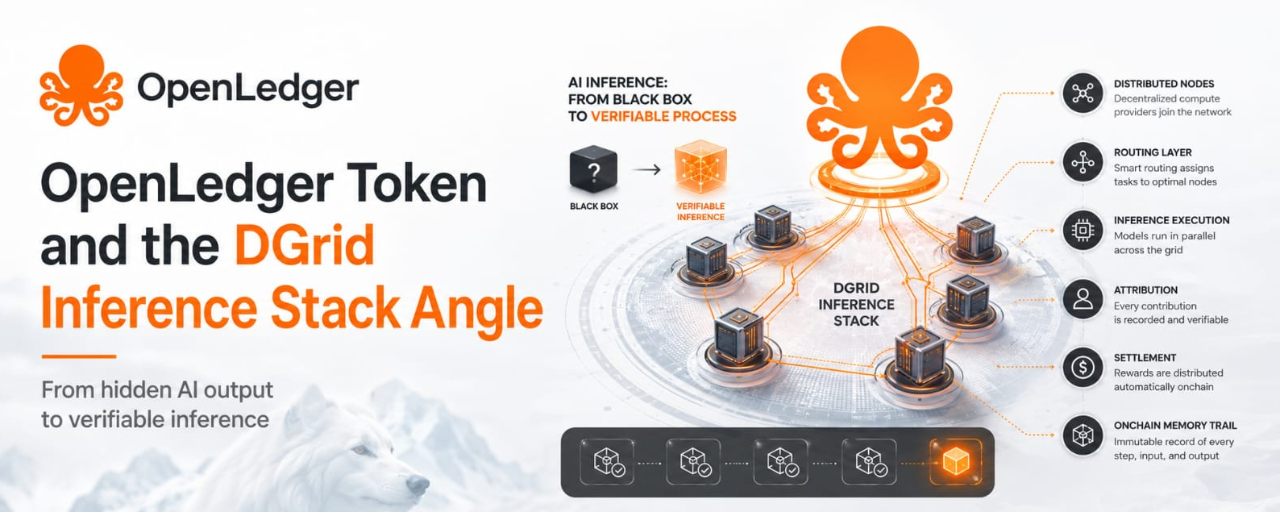

I used to think this angle was mostly about faster AI compute, but that view feels too small now. After watching how inference is being described, the harder point is not speed. It is memory. DGrid appears on the surface as a distributed route for AI work, meaning requests can move thru different compute providers instead of one closed server path. Underneath, the more important shift is that OpenLedger wants those inference events to become visible records: execution, attribution, and settlement tied to an onchain trail. That changes the question from “did the AI answer?” to “can the system show how the answer moved?”
The common misreading is simple: people call this another AI token story. I don’t think that is the stronger claim. The stronger claim is that OPEN becomes interesting only if inference itself starts behaving like an economic event. Inference means the moment a model produces an output from a request. Today it often looks like a quiet service call. But in Web3, where agents may trade, route, price, rank, or automate, that quiet call becomes a liability surface. A clean answer is not enough if nobody can inspect the workload behind it.
This is where the DGrid stack matters. On the surface, it schedules and routes workloads across distributed compute. Underneath, it is trying to make compute supply more flexible, so builders are not stuck inside one infrastructure chokepoint. That encourages apps that need constant model access, agent execution, and real-time responses. But the cost is coordination. Distributed compute can add spread between what was requested, who processed it, how quality was judged, and who gets paid. Without a reord, decentralization can become fog, not trust.

OpenLedger’s role is different. It is not just “AI data.” It is the receipt layer, or at least that is the serious version of the thesis. The project says its part is anchoring execution, attribution, and settlement onchain, while DGrid handles the workload route. Plainly said, one layer moves the work, the other tries to make the work remembered. That structure encourages business models where verified inference has value: agents with audit trails, models with data lineage, and apps that need accountable outputs. The blind spot is also clear: records are only useful if the activity underneath is real, repeated, and worth recording.
The market data keeps me cautious 🙂. On May 31, 2026, OPEN was shown near $0.18 on major public trackers, but reported circulating supply was not fully consistent: one showed about 215.50M OPEN, while another showed 290.76M OPEN. That gap matters more than the exact price, becuase small-cap AI narratives are sensitive to data trust. A token with a max supply of 1B also has future supply pressure sitting in the background, even if the current story sounds technical and clean.
Volume tells the same mixed story. One tracker showed roughly $5.55M in 24-hour trading, while another showed above $15M. That is not automatically bad, but it does warn me not to treat liqidity as one settled truth. In a market still pulled by AI-linked speculation, exchange flows, and concentrated retail attention, OPEN’s DGrid angle must compete with a harsher reality: traders may price the story before the infrastructure proves durable demand.
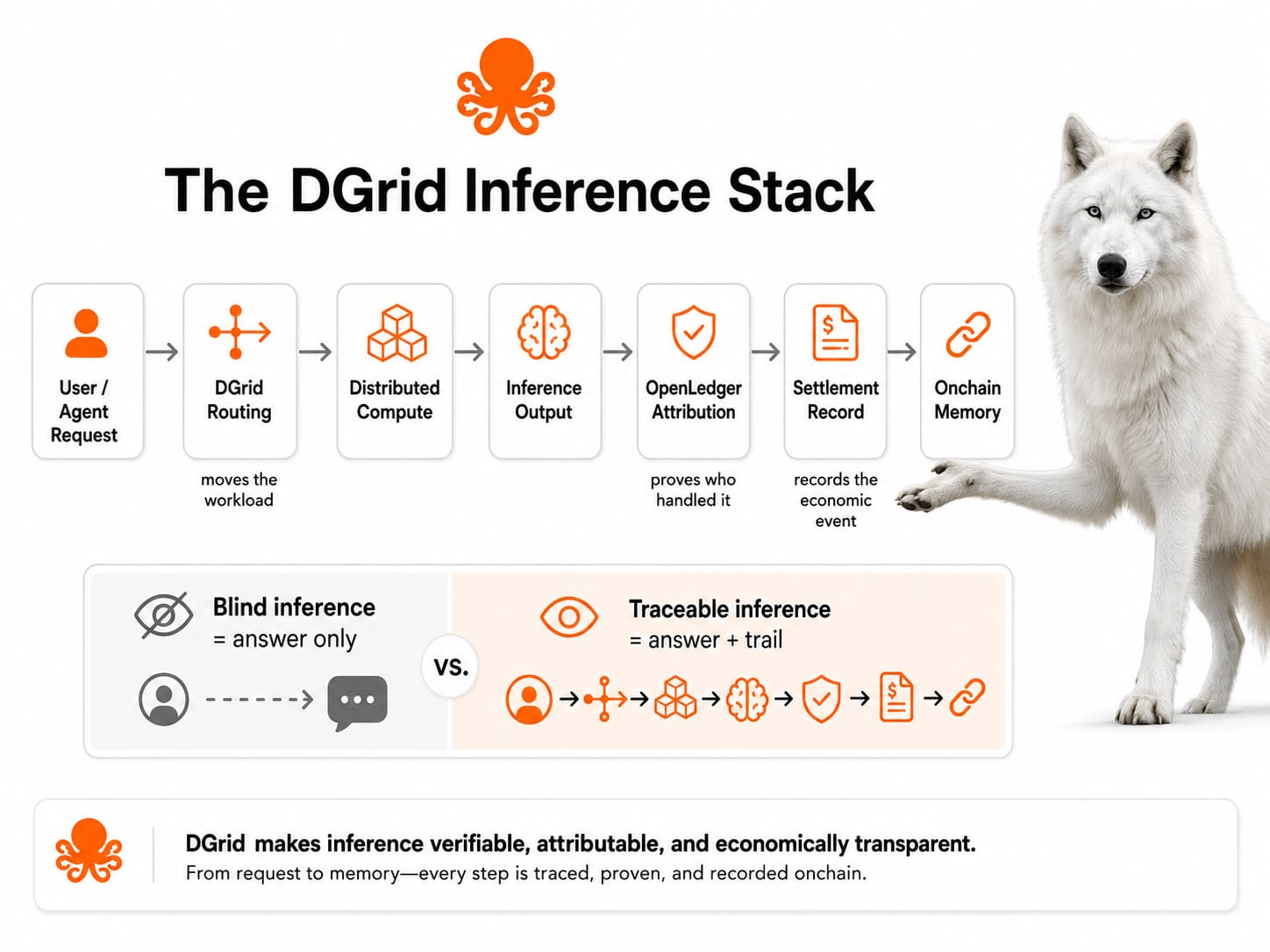
The counterargument is fair. Maybe the whole thing is still too early. Maybe “verifiable inference” sounds better in documents than inside messy production apps. Maybe users will keep choosing cheaper, faster black-box output untill regulation, custody, or agent failures force them to care. I think that skepticism is healthy. The thesis does not work because the words are impressive. It works only if machine activity becomes frequent enough that receipts are no longer optional.
For now, the stronger interpretation may be this: OpenLedger is not trying to make AI louder. It is trying to make the invisible middle harder to ignore. If DGrid moves inference and OpenLedger remembers it, then the real asset is not just the answer. It is the trail behind the answer, smalll, boring, and maybe the part markets learn to trustt last.