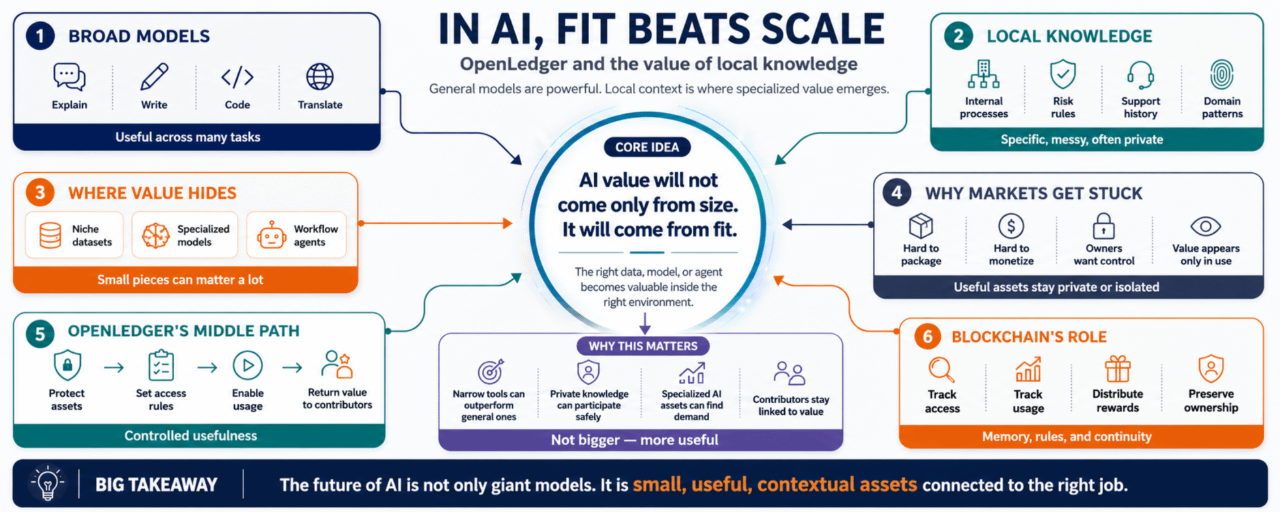
To be honest, General intelligence is useful, but local knowledge is where a lot of the real value hides.
That sounds a little plain, but it matters.
A large model can answer many things. It can explain, summarize, write, translate, code, and reason across broad topics. That is impressive. But when the work becomes specific, the model often needs something else.
It needs context.
Not just any context.
The right context.
A company’s internal process.
A hospital’s patient flow.
A trader’s risk rules.
A support team’s past tickets.
A logistics network’s small delays.
A legal team’s document patterns.
A developer team’s code habits.
These are not always things the open internet can teach well.
They are local.
Specific.
Messy.
Often private.
And that is where AI starts to become more interesting.
Because the future may not only be about who has the biggest model. It may also be about who can connect useful models to the most relevant local knowledge without losing control of it.
@OpenLedger fits into that thought.
Not as a loud promise about AI and blockchain. More as a system trying to give local AI assets a way to exist in a broader market.
Data, models, and agents are not all the same. But they have one thing in common: they become more valuable when they are connected to the right use case.
A dataset from one business may look boring from the outside.
A small model trained on one narrow task may not seem important.
An agent built for one workflow may not feel like a big product. $PORTAL
But inside the right environment, these things can matter a lot.
You can usually tell this after watching AI in real work. The generic answer is often only the beginning. The useful answer comes after the system understands the setting. The terms people use. The shortcuts they take. The risks they avoid. The patterns that repeat quietly over time.
That kind of knowledge is hard to package.
And even harder to monetize.
If a company has useful local data, it may not want to sell it. If a developer has a model tuned for one industry, they may not want it absorbed into a larger platform. If an agent works well in a specific workflow, its value may not be obvious until someone actually uses it.
So the market gets stuck.
Useful knowledge stays private.
Useful models stay isolated.
Useful agents stay small.
#OpenLedger seems to be trying to create a middle path for that.
A way for AI assets to be usable without becoming fully detached from their source. A way for local knowledge to travel under rules. A way for value to come back if that knowledge helps someone build something useful.
That is a subtle idea.
It is not the same as making everything open. Some knowledge should not be open. Some data needs limits. Some agents should only operate under certain conditions.
But closed knowledge also has a problem. If it never connects to anything, its value stays trapped.
So maybe the real question is not open versus closed.
It is controlled usefulness.
Can an asset remain protected and still participate?
Can a model be specialized and still find demand?
Can an agent be narrow and still earn from real work?
Can local knowledge become part of AI without being swallowed completely?
That is where blockchain can have a role, if used carefully.
A ledger can help track access, usage, and rewards. It can give AI assets some continuity. It can make the relationship between contributor and user less dependent on private trust. Not perfectly, of course. But maybe enough to make new kinds of sharing possible. $PLAY
And this matters because AI is becoming more contextual.
The broad model is only one layer. Around it, there will be smaller datasets, private memories, specialized models, workflows, and agents that understand one domain better than a general system can.
That does not make them bigger.
It makes them useful.
There is a difference.
A small agent that handles one business process well may create more real value than a general tool that does many things halfway. A dataset from a niche field may matter more than a giant public dataset when the task is narrow. A model trained for one workflow may become valuable because it reduces mistakes in that one place. #StrategyHintsNewBTCBuy
After a while, it becomes obvious that AI value will not only come from scale.
It will come from fit.
OpenLedger’s focus on data, models, and agents seems to sit around that shift. It gives a framework for the pieces that make AI fit a specific environment. Those pieces need ownership, access rules, and some path to monetization.
Without that, local knowledge stays locked away, or it gets absorbed by larger platforms without much visibility.
Neither outcome feels complete.
The more balanced path is harder. It means letting useful AI assets move, but with memory. With rules. With some way for contributors to stay connected to the value they helped create.
OpenLedger is trying to work somewhere in that space.
Not around the loudest version of AI.
Around the quieter one.
The one where a small piece of knowledge, in the right place, can matter more than a very large model trying to know everything.
@OpenLedger #OpenLedger $OPEN
Raksts
The more AI grows, the more one thing becomes clear.
Šajā rakstā minētais tokens var būt pakļauts augstam svārstīgumam. Veic patstāvīgu informācijas izpēti.
Atruna: iekļauti trešo pušu pausti viedokļi. Šī informācija nav uzskatāma par finansiālu padomu. Var būt iekļauts apmaksāts saturs. Skati lietošanas noteikumus.