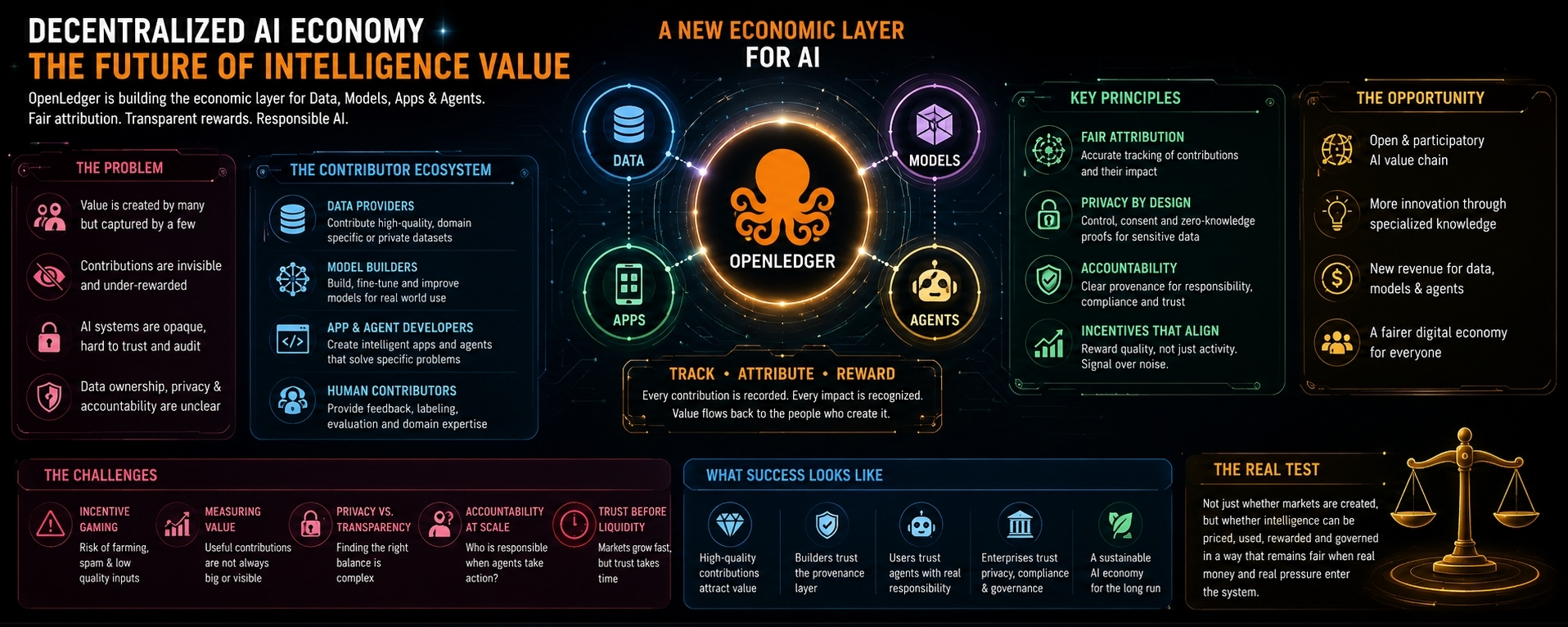
I've been watching OpenLedger from a slightly different angle now. Not as just another AI blockchain project, and not as another attempt to attach crypto rails to a trending technology. I’m watching it as part of a bigger shift in how the internet may start pricing intelligence itself. That sounds dramatic when written like that, but it does not feel dramatic when you follow the industry every day. It feels almost inevitable. Data is becoming more valuable. Models are becoming more specialized. Agents are starting to look less like chatbots and more like software workers. And somewhere in the middle of all this, projects like OpenLedger are asking a question the current AI economy has mostly avoided: if many people help create intelligence, why does the value usually end up in only a few places?
That’s where things get interesting. OpenLedger’s idea is not difficult to understand on the surface. It wants to create an economic layer for data, models, apps, and agents. In simple words, it is trying to make AI contributions trackable, usable, and monetizable. The clean version sounds fair. If someone contributes useful data, they should not disappear from the value chain. If someone builds or improves a model, their work should be recognized. If an AI agent creates value, the system should understand what powered that agent and who deserves the reward.
At first it sounds simple, but reality is different. AI does not work like a normal product supply chain. You cannot always point to one clear input and say, “This created the value.” A model may improve because of thousands of small signals. A dataset may only become useful after being cleaned, filtered, labeled, and combined with other datasets. An agent may perform well not because of one model, but because of the way its tools, prompts, memory, and permissions are arranged. By the time the final output creates revenue, the original contribution may be buried under layers of decisions.
This is why I think OpenLedger is operating in one of the hardest parts of the AI economy. It is not just trying to move assets on-chain. It is trying to give structure to something that is naturally messy. Intelligence is not a clean asset. It is layered. It is borrowed. It is remixed. It is improved through use. And that makes monetization complicated.
I keep coming back to this idea: the future of AI will not only be about who owns the biggest model. It will also be about who owns the most useful context. Specialized data, niche knowledge, domain-specific models, agent workflows, human feedback, and private datasets may become more important than people think. Large general models will still matter, of course. But not every business, community, or developer needs the biggest model in the world. Many need a model that understands their exact problem better than a general system does.
That is where OpenLedger’s direction starts to make sense. If AI moves toward specialization, then contributors around those specialized systems need a way to participate economically. A legal expert who provides high-quality data. A medical team that contributes structured knowledge. A developer who builds an agent for a very specific workflow. A community that produces useful feedback over time. These contributions are not always visible in the final AI product, but they may be the reason the product works at all.
But I’m not fully convinced yet that the industry knows how to reward this fairly. That is not only an OpenLedger problem. It is a decentralized AI problem in general. Crypto is very good at creating markets. It is also very good at attracting people who learn how to game markets. Once rewards are introduced, behavior changes. People do not simply contribute because they care about the system. They contribute in ways that maximize whatever the system measures.
This is where it gets complicated. If the system rewards volume, people will upload more data, even if it is low quality. If it rewards model creation, people will create more models, even if most of them are barely different. If it rewards agent activity, people may create artificial activity. If it rewards early participation too heavily, the best long-term contributors may arrive late and receive less than they deserve. Every incentive creates a shadow version of itself.
That is the biggest risk I see in decentralized AI economies. Not that no one will participate. The risk is that too many people will participate in the wrong way. The system may become full of activity that looks useful from the outside but does not actually improve AI. Dashboards may look healthy. Transaction counts may rise. Agent interactions may increase. But underneath, the economy could be rewarding noise.
OpenLedger will have to prove that it can separate signal from noise. That is easy to say and very hard to build. Useful data is not always large. Valuable models are not always popular. Real agent performance is not always visible through simple metrics. Some of the best contributions may be quiet, rare, and difficult to measure. A system that rewards only what is obvious may miss the value that actually matters.
Privacy adds another layer. People talk about data monetization as if all data is waiting to be sold. But valuable data is often sensitive. It may belong to users, companies, creators, patients, researchers, or communities. It may carry legal restrictions. It may include context that should not be exposed publicly. If decentralized AI is going to work, it cannot treat privacy as an afterthought.
Real systems don’t work in extremes. Full transparency sounds good until it exposes sensitive data. Full privacy sounds good until nobody can verify contribution. OpenLedger and similar projects need a middle path. Contributors need control. Buyers and builders need trust. The system needs proof without unnecessary exposure. That balance is difficult, but it may decide whether serious participants enter the ecosystem or stay away.
I also think accountability will become a much bigger issue as AI agents become more common. A model gives an answer. An agent takes action. That difference matters. Once agents can execute tasks, connect to tools, handle payments, or make decisions, the question of responsibility becomes unavoidable. If an agent makes a mistake, who is responsible? The developer? The model provider? The data contributor? The user? The protocol? The answer cannot be vague forever.
This is one reason attribution matters beyond rewards. It is not only about paying contributors. It is also about understanding the chain of responsibility. If an AI system produces something valuable, attribution tells us who helped create that value. If an AI system causes harm, attribution may also help us understand where the problem came from. That is uncomfortable, but necessary.
I think many people want the upside of decentralized AI without the burden of accountability. They want agents that earn, data that pays, models that compose, and markets that grow. But they do not always want to talk about mistakes, misuse, disputes, bad data, copied models, privacy leaks, or regulatory pressure. Those parts are less exciting, but they are where real infrastructure is tested.
Execution will decide everything. That phrase gets used a lot, but in this case it is true. OpenLedger’s success will not depend only on whether people like the idea. People already like the idea of owning and monetizing AI contributions. The harder test is whether the system can work when incentives become messy. When contributors disagree. When someone uploads questionable data. When a model’s value is disputed. When agents create fake demand. When regulators ask where the data came from. When users demand privacy and transparency at the same time.
I keep seeing people describe decentralized AI like it is automatically more fair than centralized AI. I do not think that is guaranteed. Decentralization can open access, but it does not automatically create justice. A decentralized system can still be captured by capital, by early insiders, by technical complexity, or by people who understand incentive loops better than everyone else. Fairness has to be designed. It does not appear just because a system is on-chain.
That is why I find OpenLedger interesting but not easy to judge. The project is working around a real market need. The AI economy needs better attribution. It needs better ownership models. It needs ways for data and model contributors to earn from the value they create. It needs infrastructure for agents that does not depend entirely on closed platforms. But the quality of that infrastructure will depend on details that are hard to see from the outside.
How does the system measure contribution? How does it prevent farming? How does it handle copied or low-quality datasets? How does it protect private information? How does it reward small but valuable contributors? How does it stop agent activity from becoming fake traffic? How does it make sure liquidity does not arrive before trust?
These are the questions I care about.
The strongest version of OpenLedger would not just create another marketplace. It would create a more honest AI value chain. A place where data is not treated as free raw material. A place where models carry history. A place where agents can be useful without becoming unaccountable. A place where contributors have a reason to bring high-quality inputs instead of chasing short-term rewards.
The weaker version would be easier to build. It would look active, attract speculation, and produce a lot of visible movement. But if the underlying contribution system is weak, the economy would eventually feel hollow. People would start asking whether rewards are fair. Builders would question whether the best work is being recognized. Data owners would worry about control. Users would wonder who is responsible when something goes wrong.
That is the line OpenLedger has to walk.
I do not think the future of decentralized AI will be decided by slogans. It will be decided by trust. Can contributors trust the reward system? Can developers trust the provenance of data and models? Can users trust agents acting on their behalf? Can enterprises trust the privacy and compliance layer? Can the community trust that governance will not be captured by those with the most tokens or the earliest access?
This is why I am more interested in OpenLedger’s long-term architecture than short-term attention. Hype comes easily in crypto, especially when AI is involved. But lasting infrastructure is slower. It has to survive boredom, criticism, abuse, and edge cases. It has to keep working after the excitement fades.
I’m not watching OpenLedger because I think it has already solved decentralized AI. I’m watching because it is touching the right problem at the right time. The AI economy is becoming too important to remain completely closed. The people and systems that contribute to intelligence need better ways to be recognized. But recognition without accurate attribution becomes politics. Monetization without privacy becomes risk. Liquidity without quality becomes speculation.
That is the balance.
OpenLedger’s biggest opportunity is to make AI value more open and participatory. Its biggest risk is that the economy becomes active before it becomes fair. And in decentralized AI, fairness is not a soft idea. It is the foundation. If contributors do not trust the system, they will not bring their best data. If builders do not trust the attribution layer, they will not build serious models. If users do not trust agents, they will not give them real responsibility.
So I’m watching calmly. Not cheering blindly, not dismissing it either. OpenLedger represents one of the most important debates in AI right now: whether intelligence can become an open economy without becoming a chaotic one.
And I think that is the real test. Not whether decentralized AI can create markets. It can. Not whether data, models, and agents can become assets. They probably will. The real test is whether those assets can be priced, used, rewarded, and governed in a way that still feels fair when real money and real pressure enter the system.
Because if OpenLedger gets that right, it could become part of a serious shift in how AI value is shared.
If it gets that wrong, it may become another reminder that liquidity is easy, but trust is hard.
