Market felt weird today. Not bad weird — just that specific kind of quiet where you open five tabs, close four of them, and end up somewhere you didn't expect.
I ended up looking at OpenLedger.
Not because of a signal. Not because someone called it. I'd seen $OPEN floating around and kind of ignored it the way you ignore most things when the market doesn't have a clear direction. But something made me click through.
And then I sat with it longer than I planned.
Here's the thing that shifted for me.
Everyone keeps framing OpenLedger as a "data marketplace" — like it's a tool, a platform, a place where AI developers can go buy training data. That framing is technically accurate. It's also, I think, the reason most people are sleeping on what's actually happening here.
Because the actual idea isn't data marketplace.
The actual idea is: what if users were never supposed to be the product in the first place?
That sounds obvious when you say it out loud. Of course users shouldn't be the product. We've all heard the line — if you're not paying, you are the product. And we nod, and then we keep using the apps.
But OpenLedger is doing something that makes that nodding feel different. Every time a user interacts with an AI system — every search, every correction, every labeled piece of feedback — they're generating something that has real, measurable value in the model training pipeline. Right now, that value flows one direction: up. To the company. To the model. You don't see it. You don't touch it.
OpenLedger is trying to close that loop. Attribute the data. Trace who contributed what. Pay out accordingly.
I thought this was just a DAO-style governance spin at first. Like, here's a token so you feel included. But actually — and this is what caught me — the mechanism is more specific than that. It's not just "contribute and earn." It's provenance tracking at the dataset level. The system is designed to know that this piece of data came from this source and shaped this model in this way. That's a harder technical problem than most projects are even attempting.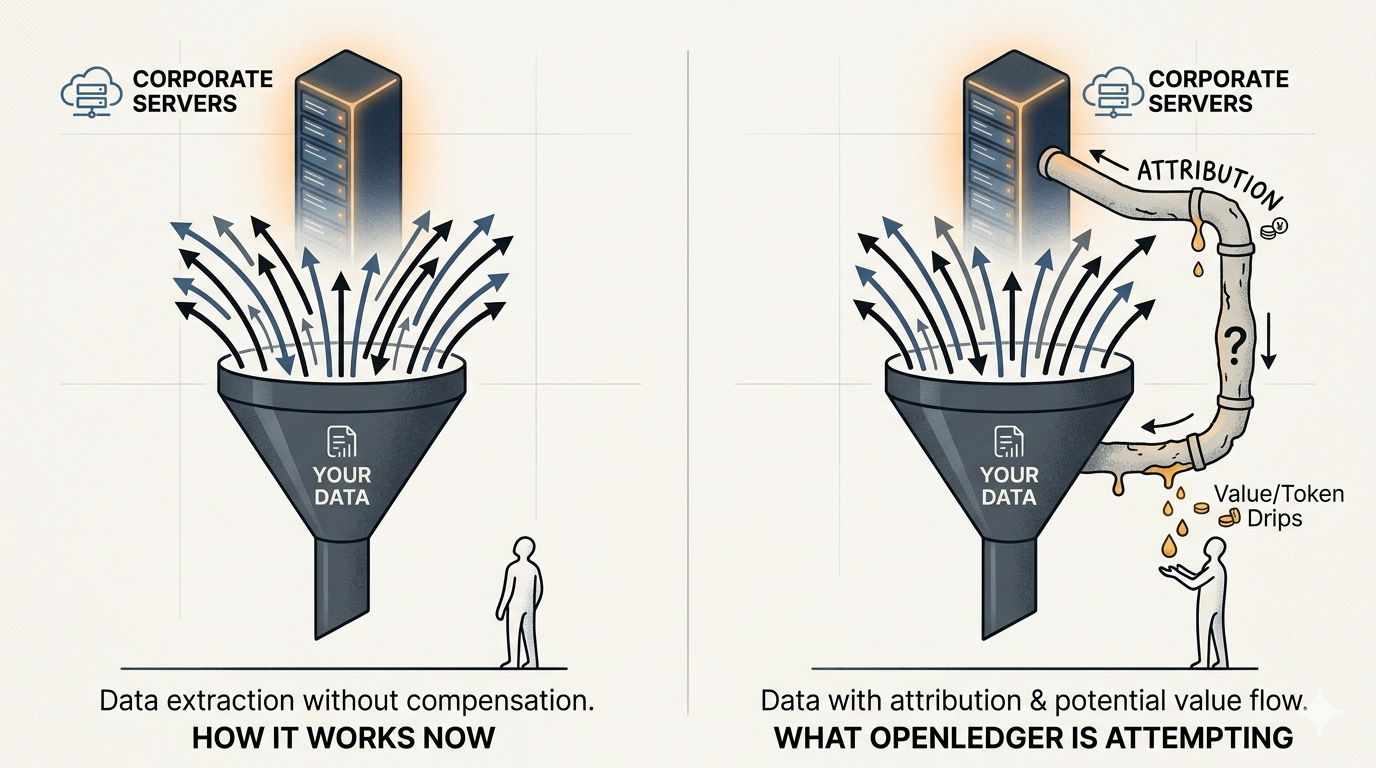
But here's the part that bothers me.
Proving attribution at scale is genuinely unsolved. Even inside major AI labs, they can't fully trace which training examples caused which behaviors. The science of data influence is still early — there are papers, there are methods, but nothing that works cleanly at production scale with millions of contributors.
So when OpenLedger says it's attributing value back to users… I believe the intent. I'm less sure about the precision. There's a real risk that "attribution" becomes a softer concept than it sounds — more like weighted participation scores than actual causal tracking. Which isn't nothing, but it's also not what the headline implies.
I keep thinking about that gap. Between the idea and the implementation. It doesn't kill the thesis, but it does change the question you should be asking. It's not "is this possible?" It's "how good does the attribution actually have to be before it works?"
And maybe that's the more interesting frame. Not whether OpenLedger solves data ownership perfectly — but whether it solves it well enough that the incentive structure changes.
Because even imprecise attribution is more than zero. Right now, users get exactly zero visibility into how their data contributes to model value. If OpenLedger creates some feedback loop — even an approximate one — it's already a different relationship than what exists today.
That shift matters more than people are pricing in. Not because $OPEN goes up (I genuinely don't know), but because it changes what a platform owes its users. And once that expectation exists somewhere, it's hard to un-exist it.
I'm still not fully convinced this holds under pressure. High token volumes, adversarial contributors, models that are hard to audit — there are a lot of ways the clean idea gets messy in production.
But I'm also not dismissing it the way I was an hour ago.
Anyway. Charts still look like nothing. I'll probably just watch how this develops before forming a stronger opinion. Maybe that's the right move. Maybe I'm already overthinking it.