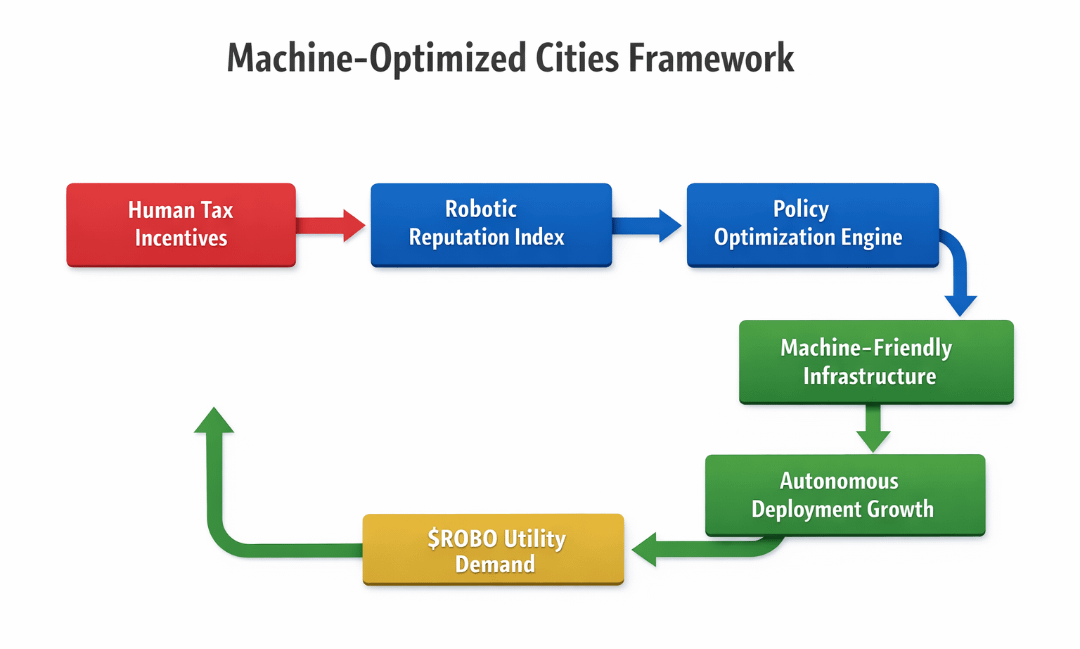
If $ROBO standardized robotic reputation scores across cities, would municipalities compete by optimizing machine-friendly policy instead of human tax incentives?
Last week I tried booking a municipal warehouse slot for a robotics demo. The page loaded, froze for two seconds, then refreshed with a higher “dynamic compliance fee.” No explanation. A small tooltip said the rate adjusted based on “automated operational density.” I hadn’t changed anything. The backend had. I paid it because the calendar was filling fast.
It wasn’t dramatic. Just quietly off. The system wasn’t negotiating with me; it was negotiating with something else — likely projected machine usage, not human intent. I was the interface, not the priority. That moment felt like watching policy shift in real time, optimized for metrics I couldn’t see. No debate, no ordinance vote, just an algorithm deciding what kind of activity a city preferred.
Modern digital systems already tilt this way. Platforms optimize for engagement curves, logistics networks optimize for routing density, exchanges optimize for liquidity fragmentation. The visible user becomes a proxy variable. Real decisions happen in backend models calibrated around throughput, reliability, and predictability. Humans supply tax revenue and votes. Machines supply uptime and measurable output.
Here’s the mental model that’s been sitting with me: cities are becoming operating systems, and robots are becoming first-class applications. In early operating systems, apps competed for CPU cycles through priority queues. The scheduler didn’t care about who wrote the app. It cared about resource efficiency, execution stability, and compliance with system rules. Over time, developers learned to write software that played nicely with the scheduler — optimizing memory footprint, avoiding crashes, respecting permission models. The system subtly shaped behavior.
Now imagine that same scheduler logic applied to municipalities.
If ROBO standardized robotic reputation scores across cities — uptime reliability, safety compliance, task accuracy, dispute resolution speed — then machines wouldn’t just operate inside cities. They would carry portable reputations between them. A delivery fleet with a 98.7% verified task completion score in one metro could request fast-track permitting in another. A warehouse automation cluster with low incident variance could receive automatic zoning priority.
Cities would stop competing through human tax breaks and start competing through machine-compatible policy environments. Instead of lowering corporate tax, they might reduce latency in robotic permitting APIs. Instead of offering payroll incentives, they might subsidize real-time safety audit feeds.
This isn’t entirely foreign to crypto ecosystems. Ethereum optimized first for security and composability; developers learned to live with higher gas costs because the settlement layer was credible. Solana optimized for throughput and low latency, attracting applications that required rapid state updates. Avalanche experimented with subnet architectures, letting specialized environments emerge under a shared security umbrella. Each system’s architectural bias shaped developer behavior more than any marketing campaign.
A standardized robotic reputation layer would do the same for cities. Policy would become a performance environment.
This is where MIRA becomes structurally relevant. Not as a promotional layer, but as a coordination fabric. If MIRA operates as a verifiable data and execution layer for cross-entity trust, it could anchor robotic reputation scores in cryptographic attestations rather than municipal databases. Instead of each city maintaining siloed compliance records, robots would carry proof-of-performance artifacts anchored to MIRA’s ledger.
Mechanically, that requires three design principles.
First, deterministic attestation pipelines. Sensor data, task logs, and safety events need to be hashed, verified, and aggregated into reputation deltas without exposing raw proprietary data. Zero-knowledge proofs or similar constructs would allow a robot to prove compliance thresholds without revealing operational blueprints.
Second, modular execution adapters. Cities run different regulatory stacks. MIRA would need interface contracts that translate local compliance requirements into standardized scoring adjustments. Think of it as a middleware layer between municipal APIs and robotic fleets.
Third, economic alignment through $MIRA. The token wouldn’t simply pay for transactions. It would likely stake reputation integrity. Operators could bond $MIRA against the accuracy of submitted performance data. If audits or cross-validation reveal manipulation, the stake is slashed. If long-term reliability is demonstrated, bonded tokens unlock with yield or enhanced scoring weight. Reputation becomes financially coupled to honesty.
The incentive loop is subtle but powerful. Robots seek higher scores to access machine-friendly cities. Operators stake $MIRA to back those scores. Cities prefer fleets with bonded reputations because enforcement costs drop. As more municipalities integrate the standard, the portability of robotic reputation increases network effects. Value accrues not from speculation, but from being the canonical coordination layer between machines and jurisdictions.
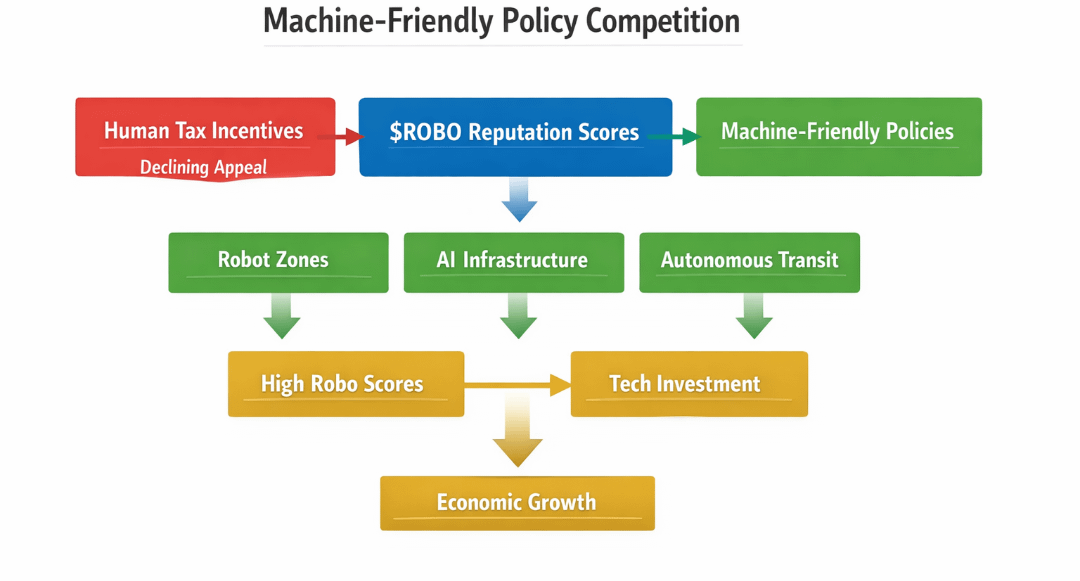
A useful visual here would be a three-column comparison table.
Column one: “Traditional Municipal Competition” — human tax incentives, zoning negotiations, payroll credits.
Column two: “Fragmented Robotic Compliance” — siloed city databases, manual audits, opaque scoring.
Column three: “Standardized Robotic Reputation via MIRA” — portable attested scores, bonded staking, automated permit prioritization.
The table would show how enforcement cost, data portability, and incentive alignment shift across models. It matters because it highlights that the real transition isn’t about robotics replacing labor. It’s about governance logic shifting from human lobbying to machine verifiability.
Second-order effects get complicated.
Developers would start optimizing hardware and software not just for performance, but for score maximization under MIRA’s attestation schema. Edge cases — like rare safety anomalies — would become economically significant. Some operators might over-optimize for measurable metrics while ignoring unscored externalities, similar to how social platforms optimize for engagement over well-being.
Cities might drift toward policies that privilege high-reputation machines, indirectly marginalizing smaller operators who cannot afford large $MIRA bonds. A reputation oligopoly could emerge, where established fleets dominate machine-friendly zones.
There’s also the governance risk. If MIRA’s scoring logic is captured by a narrow validator set or influenced by dominant robotic manufacturers, the “neutral scheduler” illusion breaks. The operating system becomes biased. And once municipal infrastructure depends on these scores, reversing course becomes politically and economically costly.
The deeper implication is uncomfortable. If robotic reputation becomes portable and standardized, municipalities stop asking, “How do we attract people?” and start asking, “How do we optimize for machines?” Policy shifts from persuasion to parameter tuning. Human incentives become secondary variables in a larger throughput equation.
The quiet loading-screen fee I paid wasn’t about money. It was a preview of governance becoming reactive to algorithmic density instead of civic deliberation. If $ROBO and MIRA formalize robotic reputation across cities, competition won’t disappear. It will migrate — from tax codes to API latency, from human incentives to machine compatibility.
And once cities become schedulers, the entities they prioritize will define whose interests the operating system truly serves.#ROBO $ROBO @Fabric Foundation