I. Wprowadzenie | Skok modelu Crypto AI
Dane, modele i moc obliczeniowa są trzema kluczowymi elementami infrastruktury AI, porównywalnymi z paliwem (dane), silnikiem (model) i energią (moc obliczeniowa), które są niezbędne. Podobnie jak w przypadku tradycyjnej ścieżki ewolucji infrastruktury branży AI, obszar Crypto AI przeszedł przez podobne etapy. Na początku 2024 roku rynek był w dużej mierze zdominowany przez zdecentralizowane projekty GPU (takie jak Akash, Render, io.net itp.), które powszechnie podkreślały logikę wzrostu opartą na „mocy obliczeniowej”. Po wejściu w 2025 rok, uwaga branży zaczęła stopniowo przesuwać się w kierunku modelu i warstwy danych, co oznacza, że Crypto AI przechodzi z konkurencji o zasoby podstawowe do bardziej zrównoważonej budowy o wartości aplikacyjnej na średnim poziomie.
Ogólny duży model (LLM) vs specjalistyczny model (SLM)
Tradycyjne duże modele językowe (LLM) w dużym stopniu polegają na ogromnych zbiorach danych i złożonych architekturach rozproszonych, a ich skala parametrów wynosi od 70B do 500B, a koszt jednego treningu często sięga kilku milionów dolarów. SLM (Specialized Language Model) jako lekka forma dostosowania modeli podstawowych, zazwyczaj oparta na modelach open source, takich jak LLaMA, Mistral i DeepSeek, łączy niewielką ilość wysokiej jakości danych specjalistycznych oraz technologie takie jak LoRA, szybko budując modele ekspertów z wiedzą z określonej dziedziny, znacząco obniżając koszty szkolenia i bariery techniczne.
Warto zaznaczyć, że SLM nie jest integrowany w wagach LLM, lecz współpracuje z LLM poprzez strukturę agenta, dynamiczne routowanie systemu wtyczek, gorące podłączanie modułów LoRA, RAG (Generowanie wzmacniane wyszukiwaniem) i inne. Ta architektura zachowuje dużą zdolność LLM do szerokiego zasięgu, jednocześnie wzmacniając specjalistyczną wydajność poprzez moduły dostosowujące, tworząc wysoko elastyczny system inteligentny o złożonej strukturze.
Crypto AI w modelu wartości i granicach
Projekty Crypto AI w istocie trudno jest bezpośrednio poprawić podstawowe zdolności dużych modeli językowych (LLM), a głównym powodem jest to, że
Wysokie bariery techniczne: Skala danych, zasoby obliczeniowe i umiejętności inżynieryjne potrzebne do trenowania modelu podstawowego są ogromne, obecnie tylko amerykańskie (OpenAI itp.) i chińskie (DeepSeek itp.) giganty technologiczne mają odpowiednie możliwości.
Ograniczenia ekosystemu open source: Chociaż główne modele podstawowe, takie jak LLaMA i Mixtral, zostały udostępnione jako open source, klucz do przełomu modeli wciąż koncentruje się w instytucjach badawczych i zamkniętych systemach inżynieryjnych, a projekty blockchain mają ograniczoną przestrzeń uczestnictwa na poziomie rdzenia modeli.
Jednakże, na bazie modeli open source, projekty Crypto AI mogą nadal wydłużać wartość poprzez dostosowanie specjalistycznych modeli językowych (SLM) oraz łączyć weryfikowalność i mechanizmy motywacyjne Web3. Jako „warstwa interfejsów” w łańcuchu przemysłu AI, manifestuje się w dwóch głównych kierunkach:
Warstwa wiarygodnej weryfikacji: Poprzez rejestrację ścieżki generowania modeli, wkład danych i ich wykorzystanie na blockchainie, zwiększa przejrzystość i odporność AI na manipulacje.
Mechanizm motywacji: Przy wsparciu rodzimego tokena, przeznaczonego do motywowania działań takich jak przesyłanie danych, wywołanie modeli, wykonanie agentów (Agent), buduje pozytywną pętlę treningu i usług modeli.
Klasyfikacja typów modeli AI i analiza ich przydatności w blockchainie

Z tego wynika, że wykonalne punkty Crypto AI skoncentrowane na projektach związanych z modelami obejmują głównie lekką kalibrację małych SLM, dostęp do danych blockchainowych w architekturze RAG i weryfikację oraz lokalne wdrażanie modeli Edge oraz motywacje. W połączeniu z weryfikowalnością blockchaina i mechanizmem tokenów, Crypto może dostarczać unikalną wartość dla tych scenariuszy modeli o średnich i niskich zasobach, tworząc zróżnicowaną wartość w warstwie „interfejsów” AI.
Na podstawie danych i modeli blockchain, można wyraźnie i nienaruszalnie rejestrować źródła wkładów każdej danej i modelu na blockchainie, znacznie zwiększając wiarygodność danych i możliwości śledzenia szkoleń modeli. Równocześnie dzięki mechanizmowi inteligentnych kontraktów, w przypadku wywołania danych lub modelu automatycznie uruchamiane są dystrybucje nagród, przekształcając działania AI w mierzalną i handelową wartość tokenizowaną, tworząc zrównoważony system motywacyjny. Dodatkowo, użytkownicy społeczności mogą również oceniać wydajność modeli za pomocą głosów tokenowych, uczestniczyć w tworzeniu i iteracji zasad, doskonaląc zdecentralizowaną strukturę zarządzania.
II. Opis projektu | Wizja łańcucha AI OpenLedger
@OpenLedger jest jednym z niewielu projektów AI na blockchainie na rynku, które koncentrują się na mechanizmach motywacji danych i modeli. Jako pierwszy zaproponował koncepcję „Płatnego AI”, mając na celu stworzenie uczciwego, przejrzystego i modularnego środowiska działania AI, które motywuje uczestników danych, deweloperów modeli i twórców aplikacji AI do współpracy na tej samej platformie oraz do uzyskiwania zysków na blockchainie w zależności od rzeczywistego wkładu.
@OpenLedger zapewnia pełny cykl zamknięty od „dostarczania danych” do „wdrażania modeli” aż do „wywołania podziału zysków”, a jego kluczowe moduły obejmują:
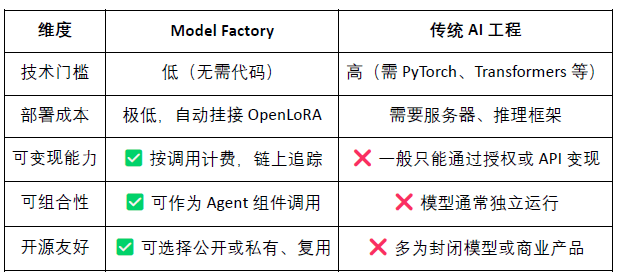
Model Factory: bez potrzeby programowania, można wykorzystać LoRA do dostosowywania, szkolenia i wdrażania modeli na podstawie otwartych LLM;
OpenLoRA: wspiera współistnienie tysięcy modeli, ładowanie na żądanie, znacznie obniżając koszty wdrożenia;
PoA (Proof of Attribution): realizuje pomiar wkładu i przydział nagród poprzez rejestrację wywołań na blockchainie;
Datanets: strukturalna sieć danych skierowana na konkretne scenariusze, budowana i weryfikowana przez społeczność;
Platforma propozycji modeli (Model Proposal Platform): złożony, wywoływalny, płatny rynek modeli na blockchainie.
Dzięki powyższym modułom, @OpenLedger stworzył infrastrukturę ekonomiczną inteligentnych bytów opartą na danych, umożliwiającą łańcuchową realizację wartości AI.
Jeśli chodzi o przyjęcie technologii blockchain, @OpenLedger na bazie OP Stack + EigenDA stworzył wysokowydajne, niskokosztowe i weryfikowalne środowisko do działania danych i umów dla modeli AI.
Zbudowany w oparciu o OP Stack: wykorzystuje technologię Optimism, wspierającą wysoką przepustowość i niskie koszty realizacji;
Rozliczenia na głównej sieci Ethereum: zapewnia bezpieczeństwo transakcji i integralność aktywów;
Kompatybilność EVM: ułatwia programistom szybkie wdrażanie i rozszerzanie w oparciu o Solidity;
EigenDA zapewnia wsparcie dla dostępności danych: znacznie obniża koszty przechowywania, zapewniając weryfikowalność danych.
W przeciwieństwie do NEAR, który bardziej koncentruje się na danych, suwerenności i architekturze „AI Agents on BOS”, @OpenLedger bardziej koncentruje się na budowie specjalnej sieci AI skoncentrowanej na danych i motywacji modeli, mając na celu umożliwienie rozwoju i wywoływania modeli na blockchainie, co prowadzi do ścisłego śledzenia, łączenia i zrównoważonej wartości. Jest to infrastruktura motywacyjna modeli w świecie Web3, łącząca hosting modeli w stylu HuggingFace, rozliczenia użytkowania w stylu Stripe oraz interfejsy do łączenia na blockchainie w stylu Infura, promując realizację „modelu jako aktywa”.
三、OpenLedger的核心组件与技术架构
3.1 Model Factory, bez potrzeby kodowania modelu fabryki
ModelFactory to @OpenLedger platforma dostosowywania dużych modeli językowych (LLM) w ekosystemie. W odróżnieniu od tradycyjnych ram dostosowywania, ModelFactory oferuje czysto graficzny interfejs operacyjny, bez potrzeby korzystania z narzędzi wiersza poleceń lub integracji API. Użytkownicy mogą dostosować model na podstawie zbioru danych autoryzowanych i zatwierdzonych na @OpenLedger . Zrealizowano zintegrowany przepływ pracy w zakresie autoryzacji danych, szkolenia modeli i wdrażania, którego kluczowe etapy obejmują:
Kontrola dostępu do danych: Użytkownik składa wniosek o dane, dostawcy zatwierdzają, dane automatycznie wchodzą do interfejsu szkolenia modeli.
Wybór i konfiguracja modeli: Wspiera główne LLM (takie jak LLaMA, Mistral), poprzez GUI konfiguruje hiperparametry.
Lekkie dostosowywanie: Wbudowany silnik LoRA / QLoRA, na bieżąco wyświetla postęp szkolenia.
Ocena modeli i wdrożenie: Wbudowane narzędzie oceny, wspiera eksport do wdrożenia lub współdzielenia ekosystemu.
Interaktywne interfejsy weryfikacyjne: Oferuje interfejs czatu, ułatwiając bezpośrednie testowanie zdolności odpowiedzi modeli.
Śledzenie generacji RAG: Odpowiedzi zawierają odniesienia do źródeł, zwiększając zaufanie i możliwość audytowania.
Architektura systemu Model Factory obejmuje sześć głównych modułów, przechodząc przez uwierzytelnianie tożsamości, uprawnienia do danych, dostosowywanie modeli, ocenę wdrożeń i śledzenie RAG, tworząc zintegrowaną platformę usług modeli, która jest bezpieczna, kontrolowana, interaktywna w czasie rzeczywistym i zrównoważona monetarnie.
Poniżej znajduje się tabela możliwości dużych modeli językowych, które obecnie obsługuje ModelFactory:
Seria LLaMA: najszerszy ekosystem, aktywna społeczność, silne ogólne wyniki, jeden z najpopularniejszych modeli podstawowych open source.
Mistral: wydajna architektura, doskonała wydajność wnioskowania, odpowiednia do elastycznych wdrożeń i ograniczonych zasobów.
Qwen: produkt Alibaba, doskonałe wyniki w zadaniach chińskich, silne ogólne możliwości, odpowiedni do wyboru krajowych programistów.
ChatGLM: wyjątkowe efekty w chińskich dialogach, odpowiednie do specjalistycznego wsparcia klienta i lokalizowanych scenariuszy.
Deepseek: doskonałe wyniki w generowaniu kodu i rozumowaniu matematycznym, odpowiednie do inteligentnych narzędzi wspierających rozwój.
Gemma: lekki model wydany przez Google, o przejrzystej strukturze, łatwy do szybkiego wdrożenia i eksperymentowania.
Falcon: wcześniej był wzorcem wydajności, odpowiedni do badań podstawowych lub testów porównawczych, ale aktywność społeczności zmniejszyła się.
BLOOM: silne wsparcie dla wielu języków, ale słaba wydajność wnioskowania, odpowiedni do badań nad pokryciem językowym.
GPT-2: klasyczny wczesny model, odpowiedni tylko do celów edukacyjnych i weryfikacyjnych, niezalecany do rzeczywistego wdrożenia.
Chociaż @OpenLedger zestaw modeli nie obejmuje najnowszych modeli MoE o wysokiej wydajności ani modeli multimodalnych, jego strategia nie jest przestarzała, lecz wynika z rzeczywistych ograniczeń związanych z wdrożeniem na blockchainie (koszty wnioskowania, adaptacja RAG, kompatybilność LoRA, środowisko EVM) w ramach konfiguracji „pragmatyzmu priorytetowego”.
Model Factory jako narzędzie bez kodu, wszystkie modele zawierają wbudowany mechanizm dowodu wkładu, zapewniający prawa uczestników danych i programistów modeli, mające niskie bariery, możliwość monetizacji i łączenia, w porównaniu do tradycyjnych narzędzi do rozwoju modeli:
Dla programistów: zapewnia pełną ścieżkę inkubacji, dystrybucji i dochodów modeli;
Dla platformy: tworzy ekosystem obiegu aktywów modeli i ich kombinacji;
Dla użytkowników: mogą łączyć modele lub agentów tak, jakby wywoływali API.
3.2 OpenLoRA, aktywizacja modeli na blockchainie
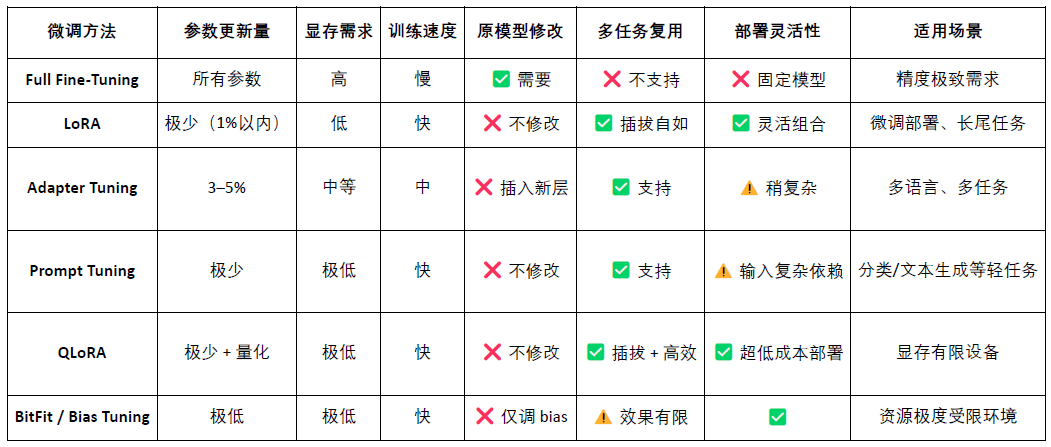
LoRA (Low-Rank Adaptation) jest efektywną metodą dostosowania parametrów, polegającą na wprowadzeniu „macierzy niskiej rangi” do pretrenowanego dużego modelu, aby uczyć nowe zadania bez zmiany parametrów oryginalnego modelu, co znacznie obniża koszty szkolenia i zapotrzebowanie na pamięć. Tradycyjne duże modele językowe (takie jak LLaMA, GPT-3) mają zazwyczaj dziesiątki miliardów, a nawet setki miliardów parametrów. Aby wykorzystać je do określonych zadań (takich jak pytania prawne, konsultacje medyczne), wymagają dostosowania (fine-tuning). Kluczowa strategia LoRA to: „zamrozić parametry oryginalnego dużego modelu, a jedynie trenować nowe macierze parametrów wstawionych.”, są one efektywne w parametrach, szybkie w szkoleniu i elastyczne w wdrażaniu, co czyni je obecnie najlepszą metodą dostosowywania modeli w Web3.
OpenLoRA to @OpenLedger zestaw lekkich ram do wnioskowania, zaprojektowanych specjalnie do wdrażania wielu modeli i współdzielenia zasobów. Jego głównym celem jest rozwiązanie powszechnych problemów związanych z wdrażaniem modeli AI, takich jak wysokie koszty, niska wielokrotność i marnotrawstwo zasobów GPU, oraz promowanie realizacji „płatnego AI” (Payable AI).
Główne komponenty architektury systemu OpenLoRA, oparte na modularnym projekcie, obejmują kluczowe etapy przechowywania modeli, wykonania wniosków, routingu żądań itp., osiągając wydajne i niskokosztowe możliwości wdrażania i wywoływania wielu modeli:
Moduł przechowywania adapterów LoRA (LoRA Adapters Storage): Po dostosowaniu adapter LoRA jest przechowywany na @OpenLedger , co umożliwia ładowanie na żądanie, unikając wcześniejszego ładowania wszystkich modeli do pamięci GPU, oszczędzając zasoby.
Warstwa hostingu modeli i dynamicznego łączenia (Model Hosting & Adapter Merging Layer): Wszystkie dostosowane modele dzielą się podstawowym dużym modelem (base model), podczas wnioskowania adapter LoRA jest dynamicznie łączony, wspierając wspólne wnioskowanie wielu adapterów (ensemble), poprawiając wydajność.
Silnik wnioskowania (Inference Engine): Zintegrowany z Flash-Attention, Paged-Attention, SGMV i innymi technikami optymalizacji CUDA.
Routowanie żądań i moduł strumieniowego wyjścia (Request Router & Token Streaming): Dynamically routes requests to the correct adapter based on model requirements, implementing token-level stream generation through kernel optimization.
Proces wnioskowania OpenLoRA należy do technicznej warstwy „dojrzałych i uniwersalnych” usług modeli, jak pokazano poniżej:
Ładowanie modeli podstawowych: System wstępnie ładuje takie podstawowe duże modele jak LLaMA 3, Mistral do pamięci GPU.
Dynamiczne wyszukiwanie LoRA: Po otrzymaniu żądania, system dynamicznie ładuje określony adapter LoRA z Hugging Face, Predibase lub lokalnego katalogu.
Aktywacja łączenia adapterów: poprzez optymalizację rdzenia, adapter jest łączony w czasie rzeczywistym z podstawowym modelem, wspierając wspólne wnioskowanie wielu adapterów.
Wykonanie wnioskowania i strumieniowe wyjście: Połączony model zaczyna generować odpowiedzi, przy użyciu strumieniowego wyjścia na poziomie tokenów, co zmniejsza opóźnienia, w połączeniu z kwantyzacją zapewniającą efektywność i dokładność.
Zakończenie wnioskowania i zwolnienie zasobów: Po zakończeniu wnioskowania adapter jest automatycznie odinstalowywany, a zasoby pamięci są zwalniane. Umożliwia to efektywne rotowanie na pojedynczym GPU i obsługę tysięcy dostosowanych modeli, wspierając efektywną rotację modeli.
OpenLoRA poprzez zestaw podstawowych technik optymalizacyjnych znacząco zwiększył efektywność wdrażania i wnioskowania wielu modeli. Jego kluczowe elementy obejmują dynamiczne ładowanie adapterów LoRA (JIT loading), co skutkuje efektywnym zmniejszeniem zajętości pamięci GPU; równoległe przetwarzanie tensorów (Tensor Parallelism) i Paged Attention realizują wysoką równoległość i przetwarzanie długich tekstów; wspiera fuzję wielu modeli (Multi-Adapter Merging) i wykonanie łączenia LoRA (ensemble); jednocześnie, poprzez Flash Attention, wstępnie skompilowane rdzenie CUDA oraz techniki kwantyzacji FP8/INT8, wspiera dalszą optymalizację CUDA oraz kwantyzację, co zwiększa prędkość wnioskowania i zmniejsza opóźnienia. Te optymalizacje sprawiają, że OpenLoRA może efektywnie obsługiwać tysiące dostosowanych modeli w środowisku z jedną kartą, łącząc wydajność, skalowalność i wykorzystanie zasobów.
OpenLoRA nie tylko jest efektywną ramą wnioskowania LoRA, ale także głęboko łączy wnioskowanie modeli z mechanizmami motywacyjnymi Web3, mając na celu przekształcenie modeli LoRA w aktywa Web3, które można wywoływać, łączyć i dzielić się zyskami.
Model jako aktywa (Model-as-Asset): OpenLoRA nie tylko wdraża modele, ale także nadaje każdemu dostosowanemu modelowi tożsamość na blockchainie (Model ID) i wiąże jego zachowanie wywołania z zachętami ekonomicznymi, realizując „wywołanie oznacza podział zysków”.
Dynamiczne połączenie wielu LoRA + przypisanie zysków: wspiera dynamiczne połączenie wywołań wielu adapterów LoRA, pozwala na tworzenie nowych usług agentów poprzez łączenie różnych modeli, a system może dokładnie przypisywać zyski dla każdego adaptera na podstawie PoA (Proof of Attribution) w zależności od ilości wywołań.
Wsparcie dla „wielotenantowego współdzielenia wniosków” dla modeli z długim ogonem: dzięki mechanizmowi dynamicznego ładowania i zwalniania pamięci GPU, OpenLoRA może obsługiwać tysiące modeli LoRA w środowisku z jedną kartą, szczególnie odpowiednie dla niszowych modeli Web3, spersonalizowanych asystentów AI i innych scenariuszy o wysokiej wielokrotności i niskiej częstotliwości wywołań.

Dodatkowo, @OpenLedger opublikował swoje prognozy dotyczące wydajności OpenLoRA, w porównaniu do tradycyjnego wdrożenia modeli pełnych parametrów, zajętość pamięci GPU znacznie spadła do 8–12 GB; czas przełączania modeli teoretycznie może być krótszy niż 100 ms; przepustowość może wynosić ponad 2000 tokenów/sekundę; opóźnienie kontrolowane na poziomie 20–50 ms. Ogólnie rzecz biorąc, te wskaźniki wydajności są technicznie osiągalne, ale bliższe są „maxymalnym osiągom”, w rzeczywistym środowisku produkcyjnym, wydajność może być ograniczona przez sprzęt, strategię harmonogramowania i złożoność scenariuszy, powinna być traktowana jako „idealny limit”, a nie „stabilne codzienne”.
3.3 Datanets (sieć danych), od suwerenności danych do inteligencji danych
Wysokiej jakości, specyficzne dla dziedziny dane stają się kluczowym elementem budowy wysokowydajnych modeli. Datanets to @OpenLedger infrastruktura „dane to aktywa”, służąca do zbierania i zarządzania specyficznymi zbiorami danych, umożliwiająca agregację, weryfikację i dystrybucję danych w danej dziedzinie w zdecentralizowanej sieci, dostarczającej wysokiej jakości źródła danych do szkolenia i dostosowywania modeli AI. Każdy Datanet jest jak zorganizowane magazyn danych, do którego uczestnicy przesyłają dane i zapewniają ich śledzenie oraz wiarygodność poprzez mechanizm przypisania danych, a dzięki mechanizmowi motywacyjnemu i przejrzystemu kontrolowaniu uprawnień, Datanets realizują wspólne budowanie i wiarygodne wykorzystanie danych potrzebnych do szkolenia modeli.
W przeciwieństwie do projektów, które koncentrują się na suwerenności danych, takich jak Vana, @OpenLedger nie ogranicza się tylko do „zbierania danych”, ale poprzez Datanets (współpraca w oznaczaniu i przypisywaniu zbiorów danych), Model Factory (narzędzie do szkolenia modeli bez kodu) i OpenLoRA (adaptery modeli z możliwością śledzenia i łączenia), wydłuża wartość danych do szkolenia modeli i wywoływania na blockchainie, budując pełną pętlę „od danych do inteligencji (data-to-intelligence)”. Vana kładzie nacisk na „kto posiada dane”, podczas gdy @OpenLedger koncentruje się na „jak dane są szkolone, wywoływane i nagradzane”, zajmując kluczową pozycję w zabezpieczeniu suwerenności danych oraz ścieżki monetyzacji danych w ekosystemie Web3 AI.
3.4 Proof of Attribution(贡献证明):重塑利益分配的激励层
Proof of Attribution(PoA)是 @OpenLedger 实现数据归属与激励分配的核心机制,通过链上加密记录,将每一条训练数据与模型输出建立可验证的关联,确保贡献者在模型调用中获得应得回报,其数据归属与激励流程概览如下:
Zgłaszanie danych: Użytkownicy przesyłają zorganizowane, specyficzne dla dziedziny zbiory danych, a następnie są one rejestrowane na blockchainie.
Ocena wpływu: System ocenia wartość danych na podstawie cech wpływu i reputacji uczestników w każdym wnioskowaniu.
Weryfikacja szkolenia: Dzienniki szkoleniowe rejestrują rzeczywiste wykorzystanie każdego elementu danych, zapewniając, że wkład jest weryfikowalny.
Podział nagród: Na podstawie wpływu danych, uczestnicy otrzymują nagrody tokenowe związane z efektem.
Zarządzanie jakością: Kara za niskiej jakości, redundantne lub złośliwe dane, aby zapewnić jakość szkolenia modeli.
W porównaniu do sieci motywacyjnej Bittensor, która łączy mechanizm oceny w architekturze sub-sieci, @OpenLedger koncentruje się na przechwytywaniu wartości na poziomie modeli i mechanizmach podziału zysków. PoA jest nie tylko narzędziem dystrybucji motywacji, ale także ramą dla przejrzystości, śledzenia źródeł i wieloetapowego przypisania: rejestruje cały proces przesyłania danych, wywołania modeli i wykonywania agentów na blockchainie, realizując end-to-end weryfikowalną ścieżkę wartości. Mechanizm ten umożliwia zidentyfikowanie każdego wywołania modelu z danymi, które je wspierają, co prowadzi do prawdziwej „zgody wartości” i „możliwości przychodu” w systemie AI na blockchainie.
RAG (Retrieval-Augmented Generation) to architektura AI łącząca systemy wyszukiwania i modele generatywne, mająca na celu rozwiązanie problemów tradycyjnych modeli językowych związanych z „zamknięciem wiedzy” i „tworzeniem fałszywych informacji”, poprzez wprowadzenie zewnętrznych baz danych wzmacnia zdolności generacyjne modelu, czyniąc wyniki bardziej rzeczywistymi, zrozumiałymi i weryfikowalnymi. RAG Attribution to @OpenLedger mechanizm tworzenia danych przypisania i motywacji w scenariuszu generacji wzmacnianej wyszukiwaniem, zapewniający, że treści generowane przez model są śledzone, weryfikowalne, a uczestnicy mogą być motywowani, osiągając ostatecznie generację wiarygodnych i transparentnych danych, a jego proces obejmuje:
Pytanie użytkownika → Wyszukiwanie danych: AI odbiera pytanie i wyszukuje związane treści z indeksu danych @OpenLedger .
Dane są wywoływane i generują odpowiedzi: Wyszukane treści są wykorzystywane do generowania odpowiedzi modelu, a działania wywołania są rejestrowane na blockchainie.
Uczestnicy otrzymują nagrody: Po wykorzystaniu danych, ich uczestnicy otrzymują zachęty obliczane na podstawie kwoty i związku.
Wygenerowane wyniki zawierają odniesienia: Wyjścia modelu są dołączone do linków do źródeł danych, co zapewnia przejrzystość odpowiedzi i weryfikowalność treści.

@OpenLedger RAG Attribution pozwala na przypisanie każdej odpowiedzi AI do rzeczywistego źródła danych, a uczestnicy otrzymują nagrody w zależności od częstotliwości cytowania, realizując „wiedzę z źródła, wywołanie z możliwością realizacji”. Mechanizm ten nie tylko zwiększa przejrzystość wyników modeli, ale także buduje trwałą pętlę motywacyjną dla wysokiej jakości wkładów danych, będąc kluczową infrastrukturą do promowania wiarygodnego AI i aktywów danych.
Cztery, postęp projektu OpenLedger i współpraca ekosystemu
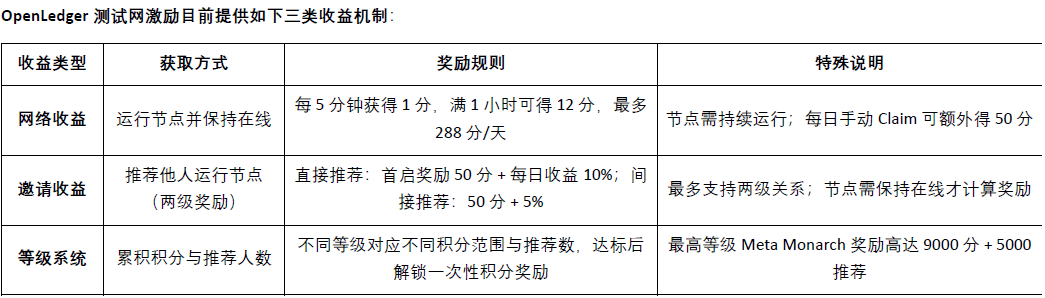
Obecnie@OpenLedger testowa sieć jest już uruchomiona, warstwa inteligencji danych (Data Intelligence Layer) to @OpenLedger pierwszy etap testowej sieci, mający na celu stworzenie internetowego magazynu danych napędzanego wspólnotowymi węzłami. Dane te są filtrowane, wzmacniane, klasyfikowane i przetwarzane w sposób strukturalny, ostatecznie tworząc inteligencję pomocniczą odpowiednią dla dużych modeli językowych (LLM) do budowy @OpenLedger dziedzinowych modeli AI na. Członkowie społeczności mogą uruchamiać węzły urządzeń brzegowych, uczestniczyć w zbieraniu i przetwarzaniu danych, węzły będą korzystać z lokalnych zasobów obliczeniowych do realizacji zadań związanych z danymi, uczestnicy otrzymają punkty nagród w zależności od aktywności i stopnia realizacji zadań. Punkty te zostaną w przyszłości wymienione na tokeny OPEN, a dokładny współczynnik wymiany zostanie ogłoszony przed wydarzeniem generowania tokenów (TGE).
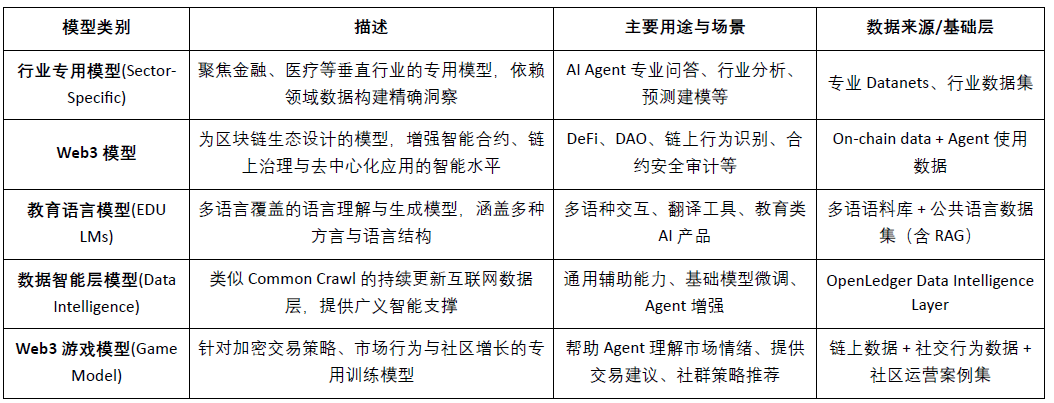
Faza testowa 2 kładzie nacisk na mechanizm sieci danych Datanets, ta faza jest ograniczona do użytkowników z białej listy, muszą oni przejść wstępną ocenę, aby odblokować zadania. Zadania obejmują weryfikację danych, klasyfikację itp., po ich zakończeniu uczestnicy otrzymają punkty w zależności od dokładności i trudności, a lista rankingowa motywuje do wysokiej jakości wkładów, obecnie dostępne modele danych, w które można uczestniczyć, to:
a @OpenLedger ma długoterminowy plan działania, przechodząc od zbierania danych do budowy modeli, co prowadzi do ekosystemu agentów, stopniowo realizując pełen zdecentralizowany model AI gospodarczy, w którym „dane to aktywa, model to usługa, agent to inteligentny byt”.
Faza 1 · Warstwa inteligencji danych (Data Intelligence Layer): Społeczność gromadzi i przetwarza dane z internetu, budując podstawową warstwę inteligencji danych o wysokiej jakości i ciągłej aktualizacji.
Faza 2 · Wkład danych od społeczności (Community Contributions): Społeczność uczestniczy w weryfikacji danych i feedbacku, wspólnie tworząc wiarygodny zbiór danych (Golden Dataset), dostarczając wysokiej jakości wejście do szkolenia modeli.
Faza 3 · Budowanie modeli i ogłoszenia własności (Build Models & Claim): Na podstawie złotych danych, użytkownicy mogą szkolić dedykowane modele i ogłaszać ich własność, osiągając aktywizację modeli i możliwość łączenia ich wartości.
Faza 4 · Tworzenie agentów (Build Agents): Na podstawie opublikowanych modeli, społeczność może tworzyć spersonalizowane inteligentne byty (Agents), realizując wiele scenariuszy wdrożenia i ciągłej współpracy.
@OpenLedger partnerzy ekosystemu obejmują moc obliczeniową, infrastrukturę, narzędzia oraz aplikacje AI. Wśród ich partnerów znajdują się platformy zdecentralizowanej mocy obliczeniowej, takie jak Aethir, Ionet, 0G, oraz AVS z AltLayer, Etherfi i EigenLayer, które oferują wsparcie dla podstawowych rozszerzeń i rozliczeń; narzędzia, takie jak Ambios, Kernel, Web3Auth, Intract, które zapewniają możliwość uwierzytelniania i integracji rozwoju; w zakresie modeli AI i agentów, @OpenLedger współpracuje z projektami takimi jak Giza, Gaib, Exabits, FractionAI, Mira, NetMind, aby wspierać wdrażanie modeli i realizację agentów, budując otwarty, złożony i zrównoważony ekosystem AI w Web3.
W ciągu ostatniego roku #OpenLedger zorganizował cykl szczytów DeAI Summit w Singapurze, Tajlandii, Hongkongu i ETH Denver, koncentrując się na tematyce Crypto AI, zapraszając wiele kluczowych projektów i liderów technologicznych z dziedziny zdecentralizowanej AI. Jako jeden z nielicznych projektów infrastrukturalnych, które mogą ciągle organizować wysokiej jakości wydarzenia branżowe, #OpenLedger skutecznie wzmocnił swoją markę i renomę w społeczności deweloperów i ekosystemie Web3 AI, kładąc solidne podstawy dla późniejszej ekspansji ekosystemu i wdrożenia technologii.
Pięć, finansowanie i tło zespołu
@OpenLedger zakończył rundę finansowania seedową na poziomie 11,2 miliona dolarów w lipcu 2024 roku, a inwestorzy to Polychain Capital, Borderless Capital, Finality Capital, Hashkey oraz wielu znanych inwestorów aniołów, takich jak Sreeram Kannan (EigenLayer), Balaji Srinivasan, Sandeep (Polygon), Kenny (Manta), Scott (Gitcoin), Ajit Tripathi (Chainyoda) i Trevor. Fundusze będą głównie przeznaczone na rozwój sieci AI Chain @OpenLedger oraz pełną realizację mechanizmu motywacji modeli, podstawy danych i ekosystemu aplikacji Agent.

@OpenLedger został założony przez Rama Kumara, który jest głównym współtwórcą #OpenLedger oraz przedsiębiorcą z siedzibą w San Francisco, posiadającym solidne podstawy techniczne w dziedzinie AI/ML i technologii blockchain. Wnosi do projektu połączenie wnikliwości rynkowej, wiedzy technicznej i strategicznego przywództwa. Ram wcześniej współkierował firmą zajmującą się badaniami i rozwojem w dziedzinie blockchain i AI/ML, której roczne przychody przekroczyły 35 milionów dolarów, a także odegrał kluczową rolę w nawiązywaniu współpracy, w tym w ramach strategicznego partnerstwa z podmiotem zależnym Walmart. Skupia się na budowie ekosystemu i współpracy o wysokim współczynniku dźwigni, dążąc do przyspieszenia zastosowań w rzeczywistości w różnych branżach.
VI. Projektowanie modeli ekonomicznych tokenów i zarządzanie
$OPEN jest podstawowym tokenem funkcjonalnym ekosystemu @OpenLedger , umożliwiającym zarządzanie siecią, działanie transakcji, dystrybucję nagród oraz działalność AI Agent, jest podstawą budowy zrównoważonego obiegu modeli AI i danych na blockchainie, obecnie oficjalne ekonomiczne ramy tokena są wczesnym etapie projektowania, szczegóły nie są jeszcze całkowicie jasne, ale z projektem zbliżającym się do etapu generowania tokenów (TGE), jego wzrost społeczności, aktywność deweloperów i eksperymenty z zastosowaniami przyspieszają w Azji, Europie i na Bliskim Wschodzie.
Zarządzanie i podejmowanie decyzji: Posiadacze Open mogą uczestniczyć w głosowaniu w sprawie finansowania modeli, zarządzania agentami, ulepszania protokołów i wykorzystania funduszy.
Paliwo transakcyjne i płatności za usługi: jako natywny token gazowy sieci @OpenLedger , wspiera natywne mechanizmy dostosowywania stawek dla AI.
Motywacja i nagrody za przypisanie: programiści, którzy wnoszą wysokiej jakości dane, modele lub usługi, mogą otrzymać Open w zależności od wpływu użycia.
Możliwości mostu międzyłańcuchowego: Open wspiera mosty L2 ↔ L1 (Ethereum), zwiększając dostępność modeli i agentów w wielu łańcuchach.
Mechanizm stakowania AI Agent: Uruchomienie AI Agenta wymaga stakowania $OPEN , słaba wydajność prowadzi do obniżenia stakowania, co motywuje do wydajnych i zaufanych wyników usług.
W przeciwieństwie do wielu protokołów zarządzania tokenami powiązanych z wpływem i ilością posiadanych monet, @OpenLedger wprowadza mechanizm zarządzania oparty na wartości wkładu. Jego waga głosów jest związana z rzeczywistą wartością, a nie tylko z kapitałem, priorytetowo traktując tych, którzy uczestniczą w budowie, optymalizacji i użytkowaniu modeli oraz zbiorów danych. Taki projekt architektoniczny sprzyja długoterminowej zrównoważoności zarządzania, zapobiega dominacji spekulacyjnej w podejmowaniu decyzji, naprawdę odpowiada wizji zdecentralizowanej gospodarki AI „przejrzystej, sprawiedliwej, napędzanej przez społeczność”.
Siedem, dane, modele oraz dynamika rynku motywacji i porównania konkurencji
@OpenLedger jako infrastruktura motywacyjna „płatnego AI (Payable AI)” ma na celu zapewnienie uczestnikom danych i programistom modeli ścieżki realizacji wartości, która jest weryfikowalna, przypisywalna i zrównoważona. Koncentruje się na wdrożeniu na blockchainie, motywacji do wywołania oraz mechanizmach łączenia agentów, tworząc zróżnicowany system modułowy, który wyróżnia się w obecnym torze Crypto AI. Choć żaden projekt nie pokrywa się całkowicie w architekturze, OpenLedger wykazuje wysoką porównywalność i potencjał współpracy w kluczowych wymiarach, takich jak motywacja protokołu, ekonomia modeli i prawność danych.
Warstwa motywacyjna protokołu: OpenLedger vs. Bittensor
Bittensor jest obecnie najbardziej reprezentatywną zdecentralizowaną siecią AI, która zbudowała wieloosobowy system współpracy napędzany przez sub-sieci (Subnet) i mechanizmy ocen, wykorzystując token $TAO do motywowania uczestników modeli, danych i węzłów porządkowych. W porównaniu do tego,@OpenLedger Skupia się na podziale zysków z wdrożenia modeli na blockchainie i wywołania modeli, podkreślając lekką architekturę i mechanizm współpracy agentów. Choć logiki motywacyjne obu mają pewne pokrywanie, różnią się celami i złożonością systemu: Bittensor koncentruje się na ogólnej sieci zdolności AI.@OpenLedger jest platformą do przechwytywania wartości w warstwie aplikacji AI.
Przypisanie modeli i motywacja do wywołania: OpenLedger vs. Sentient
Sentient zaproponował ideę „OML (Open, Monetizable, Loyal) AI”, która w identyfikacji praw własności modeli i wspólnej własności pokrywa się z @OpenLedger Część pomysłów jest podobna i koncentruje się na realizacji identyfikacji przypisania i śledzenia przychodów za pomocą Model Fingerprinting. Różnicą jest to, że Sentient skupia się bardziej na etapie szkolenia i generacji modeli, podczas gdy @OpenLedger Skupia się na wdrożeniu modeli na blockchainie, ich wywołaniu i mechanizmie podziału zysków, obie znajdują się w górnej i dolnej części łańcucha wartości AI, co powoduje naturalną komplementarność.
Platforma przechowywania modeli i wiarygodnego wnioskowania: OpenLedger vs. OpenGradient
OpenGradient koncentruje się na budowie bezpiecznej ramy wykonawczej wnioskowania opartej na TEE i zkML, oferując zdecentralizowane usługi przechowywania modeli i wnioskowania, skupiając się na zaufanym środowisku uruchomieniowym. W przeciwieństwie do tego,@OpenLedger bardziej podkreśla ścieżkę przechwytywania wartości po wdrożeniu na blockchainie, budując pełną pętlę „trening — wdrożenie — wywołanie — podział zysków” wokół Model Factory, OpenLoRA, PoA i Datanets. Obie są w innym etapie cyklu życia modeli: OpenGradient koncentruje się na zaufaniu operacyjnym, OpenLedger na motywacji dochodowej i kombinacji ekosystemu, oferując wysoki potencjał komplementarności.
Modele zbiorowe i oceny nagród: OpenLedger vs. CrunchDAO
CrunchDAO koncentruje się na zdecentralizowanym mechanizmie rywalizacji modeli prognoz finansowych, zachęcając społeczność do przesyłania modeli i zdobywania nagród na podstawie wyników, odpowiedni do określonych scenariuszy wertykalnych. W porównaniu do tego,@OpenLedger Oferują złożony rynek modeli i zintegrowane ramy wdrożeniowe, mające szerszą ogólną funkcjonalność i natywne możliwości monetyzacji na blockchainie, odpowiednie do rozszerzenia różnorodnych scenariuszy agentów. Obie mają komplementarne logiki motywacyjne, oferując potencjał synergii.
Społecznie napędzana platforma lekkich modeli: OpenLedger vs. Assisterr
Assisterr zbudowany na Solana, zachęca społeczność do tworzenia małych modeli językowych (SLM) i zwiększa częstotliwość użycia poprzez narzędzia bez kodu i mechanizm zachęt $sASRR. W porównaniu do tego,@OpenLedger bardziej podkreśla zamkniętą pętlę śledzenia i podziału wartości danych-model-wywołanie, wykorzystując PoA do realizacji szczegółowego podziału zysków. Assisterr jest bardziej odpowiedni dla społeczności współpracy modeli o niskich barierach,@OpenLedger dąży do zbudowania infrastruktury modelowej, która jest wielokrotnego użytku i modułowa.
Fabryka modeli: OpenLedger vs. Pond
Pond i @OpenLedger również oferują moduł „Model Factory”, ale ich pozycjonowanie i grupa docelowa różnią się znacznie. Pond koncentruje się na modelowaniu zachowań na blockchainie opartym na grafowych sieciach neuronowych (GNN), głównie skierowane do badaczy algorytmów i naukowców zajmujących się danymi, i poprzez mechanizm rywalizacji promuje rozwój modeli, Pond jest bardziej skłonny do konkurencji modeli; OpenLedger opiera się na dostosowaniu modeli językowych (np. LLaMA, Mistral), służy programistom i użytkownikom nietechnicznym, kładąc nacisk na doświadczenie bez kodu oraz mechanizm automatycznego podziału zysków na blockchainie, budując ekosystem motywacyjny modeli AI oparty na danych, OpenLedger jest bardziej skłonny do współpracy w zakresie danych.
Wiarygodna ścieżka wnioskowania: OpenLedger vs. Bagel
Bagel wprowadził ramy ZKLoRA, wykorzystując modele LoRA do dostosowywania oraz technologię dowodów zerowej wiedzy (ZKP), aby zapewnić weryfikowalność szyfrowania procesu wnioskowania poza łańcuchem, zapewniając poprawność wykonania. Z kolei @OpenLedger poprzez OpenLoRA wspiera elastyczne wdrażanie modeli LoRA oraz dynamiczne wywoływanie, jednocześnie rozwiązując problemy związane z weryfikowalnością wnioskowania z różnych perspektyw - poprzez dołączanie dowodów przypisania (Proof of Attribution, PoA) do każdego wyjścia modelu, śledząc źródła danych i ich wpływ na proces wnioskowania. To nie tylko zwiększa przejrzystość, ale także nagradza uczestników, którzy dostarczają wysokiej jakości dane i zwiększa zrozumiałość oraz wiarygodność procesu wnioskowania. W skrócie, Bagel koncentruje się na weryfikacji poprawności wyników obliczeń, podczas gdy @OpenLedger realizuje śledzenie odpowiedzialności i weryfikowalność procesu wnioskowania poprzez mechanizm przypisania.
Ścieżka współpracy po stronie danych: OpenLedger vs. Sapien / FractionAI / Vana / Irys
Sapien i FractionAI oferują zdecentralizowane usługi oznaczania danych, Vana i Irys koncentrują się na suwerenności danych i mechanizmach prawnych.@OpenLedger realizuje śledzenie wykorzystania wysokiej jakości danych oraz dystrybucję nagród na blockchainie za pomocą modułu Datanets + PoA. Pierwszy może działać jako dostawca danych,@OpenLedger działa jako centrum rozdzielania wartości i wywołania, a wszystkie trzy mają dobrą współpracę w łańcuchu wartości danych, a nie konkurencyjną relację.
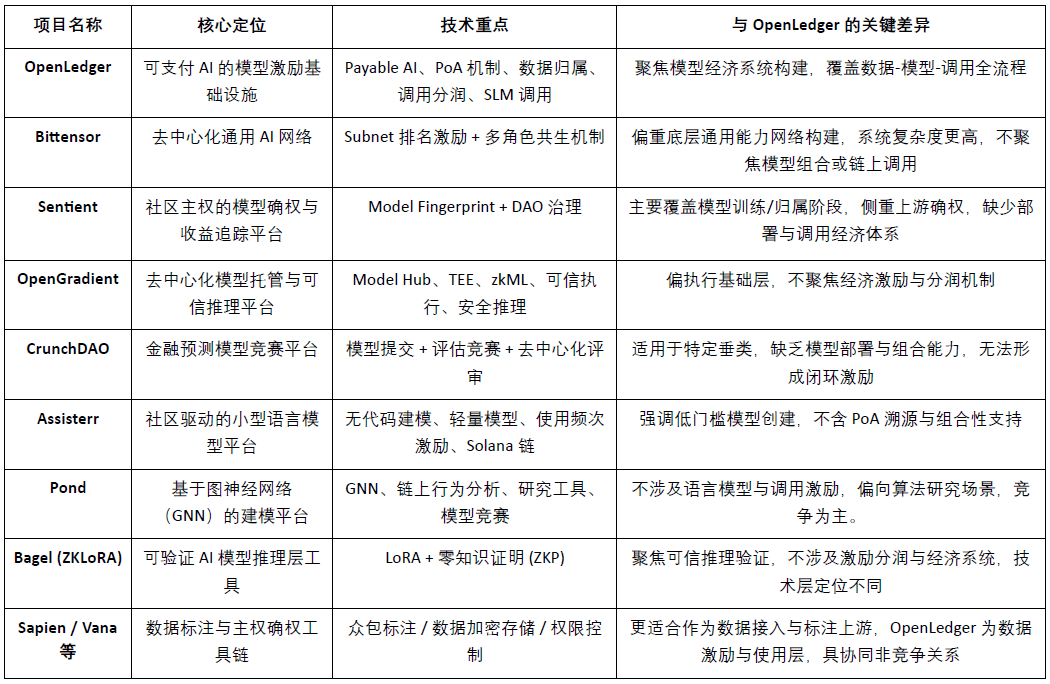
Podsumowując, @OpenLedger zajmuje pośrednią pozycję w obecnym ekosystemie Crypto AI jako „model aktywów na blockchainie i motywacja do wywołania”, może łączyć sieci treningowe i platformy danych w górę, a także obsługiwać warstwę agentów i aplikacji końcowych w dół, jest kluczowym protokołem łączącym dostarczanie wartości modeli i ich zastosowanie.
VIII. Wnioski | Od danych do modeli, ścieżka monetizacji łańcucha AI
#OpenLedger ma na celu stworzenie infrastruktury „model jako aktywa” w świecie Web3, poprzez budowę pełnej pętli na blockchainie dla wdrożenia, motywacji do wywołania, potwierdzenia własności i kombinacji agentów, po raz pierwszy wprowadzając modele AI do rzeczywistej, weryfikowalnej, monetyzowalnej i współpracującej gospodarki. Jego technologia oparta na Model Factory, OpenLoRA, PoA i Datanets zapewnia programistom niskie bariery do narzędzi szkoleniowych, uczestnikom danych zapewnia zasady podziału zysków, a stronom aplikacji umożliwia elastyczne wywołanie modeli i mechanizmy podziału zysków, całkowicie aktywując długoterminowo ignorowane zasoby „danych” i „modeli” w łańcuchu wartości AI.
#OpenLedger jest bardziej jak fuzja HuggingFace + Stripe + Infura w świecie Web3, oferując hosting modeli, rozliczenia wywołań oraz modułowe interfejsy API na blockchainie. W miarę jak przyspiesza się trend aktywizacji danych, autonomizacji modeli i modułowości agentów, OpenLedger ma szansę stać się kluczowym węzłem w modelu „Płatnego AI”.


